
«`html
NLP Решения на базе T-FREE
Обработка естественного языка (NLP) побуждает исследователей разрабатывать алгоритмы, которые позволяют компьютерам понимать, интерпретировать и генерировать человеческие языки. Основной проблемой являются неэффективность и ограничения токенизаторов, используемых в больших языковых моделях (LLMs).
Проблема с токенизаторами
Традиционные методы, такие как Byte Pair Encoding (BPE) и Unigram токенизаторы, создают словари на основе статистических частот в корпусе. Однако они требуют значительных вычислительных ресурсов и приводят к большим, неэффективным словарям с множеством избыточных токенов.
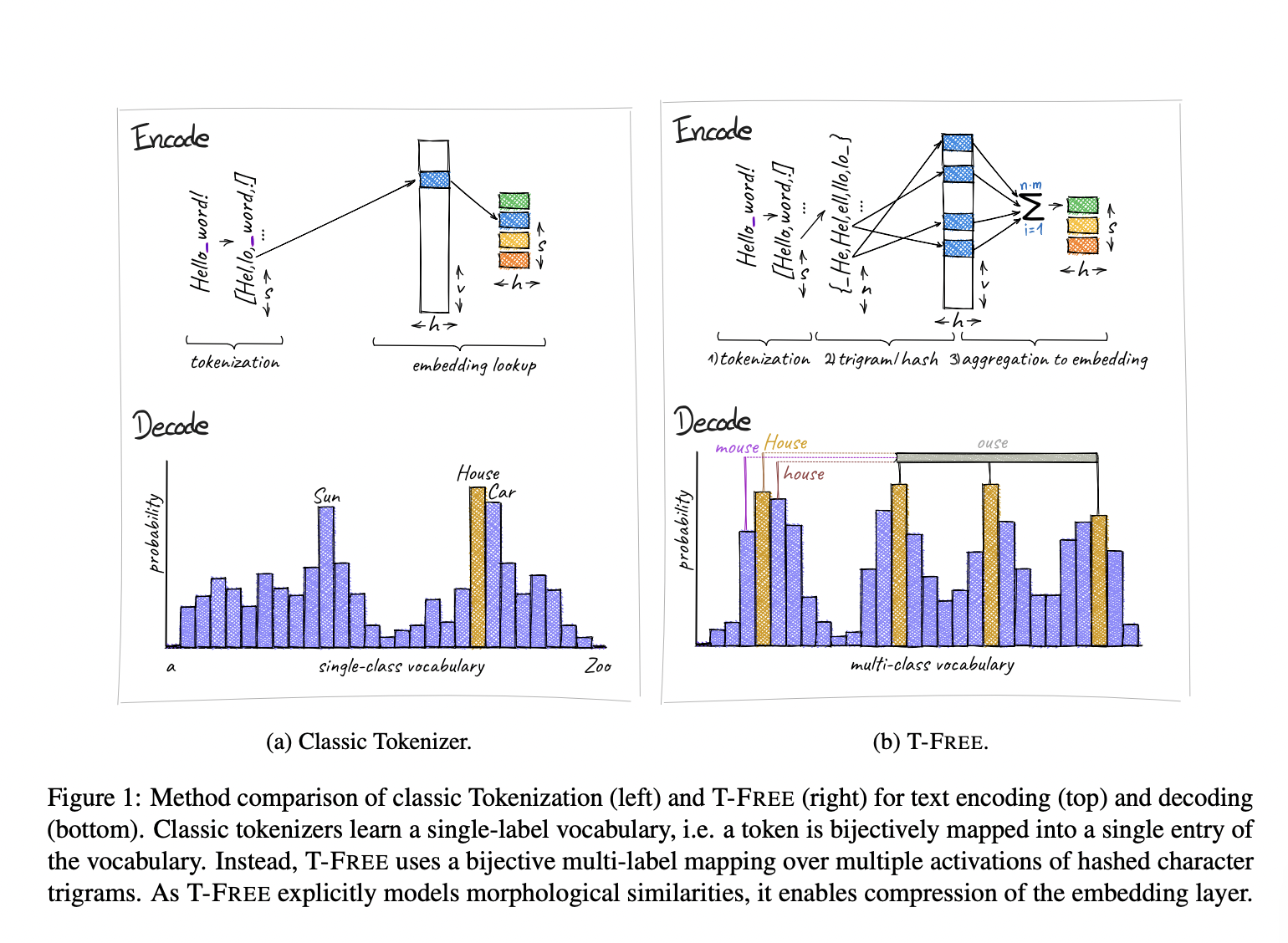
Решение: T-FREE
Исследователи из Aleph Alpha, Технического университета Дармштадта, Хесского центра искусственного интеллекта и Немецкого центра искусственного интеллекта представили новый подход под названием T-FREE. Этот метод без токенизации значительно уменьшает размер встраиваемых слоев и повышает производительность на различных языках.
Преимущества и результаты
Эксперименты показали значительные улучшения по сравнению с традиционными токенизаторами. T-FREE позволяет достичь конкурентоспособной производительности с уменьшением параметров более чем на 85% на слоях кодирования текста. Он также продемонстрировал существенные улучшения в кросс-языковом обучении. T-FREE превзошел традиционные токенизаторы в бенчмарк-тестах, подчеркивая его эффективность и эффективность в обработке различных языков и задач.
Применение в бизнесе
Такое решение может значительно улучшить процессы в компании, снизить вычислительные затраты и повысить эффективность обработки текста. Также оно может быть особенно полезно для обработки недостаточно представленных языков.
Подробнее о работе исследователей можно узнать в статье.
Подписывайтесь на наш Twitter и присоединяйтесь к нашему Telegram каналу.
«`

















