
«`html
Изучение скрытых слоев в больших языковых моделях LLMs
Исследователи из Hebrew University бросили вызов задаче понимания того, как информация проходит через различные уровни декодирования крупных языковых моделей (LLMs). Особенно они исследовали, являются ли скрытые состояния предыдущих токенов в более высоких уровнях такими же важными, как считается. Текущие LLMs, такие как модели на основе трансформера, используют механизм внимания для обработки токенов, обращая внимание на все предыдущие токены на каждом уровне. В то время как каждый уровень трансформера применяет это внимание равномерно, предыдущие исследования указывают на то, что разные уровни захватывают различные типы информации. Исследование основано на идее, что не все уровни могут одинаково полагаться на скрытые состояния предыдущих токенов, особенно на более высоких уровнях.
Исследовательская группа предположила, что в то время как более низкие уровни фокусируются на агрегировании информации от предыдущих токенов, более высокие уровни могут меньше полагаться на эту информацию. Они предлагают различные манипуляции со скрытыми состояниями предыдущих токенов на разных уровнях модели. К ним относятся замена скрытых состояний случайными векторами, замораживание скрытых состояний на определенных уровнях и замена скрытых состояний одного токена другим из другой подсказки. Они проводят эксперименты на четырех открытых LLMs (Llama2-7B, Mistral-7B, Yi-6B и Llemma-7B) и четырех задачах, включая вопросно-ответную систему и резюмирование, чтобы оценить влияние этих манипуляций на производительность модели.
Одна из техник включает в себя добавление шума путем замены скрытых состояний случайными векторами, что позволяет исследователям оценить, имеет ли значение содержание этих скрытых состояний на определенных уровнях. Второй метод, замораживание, блокирует скрытые состояния на определенном уровне и повторно использует их для последующих уровней, снижая вычислительную нагрузку.
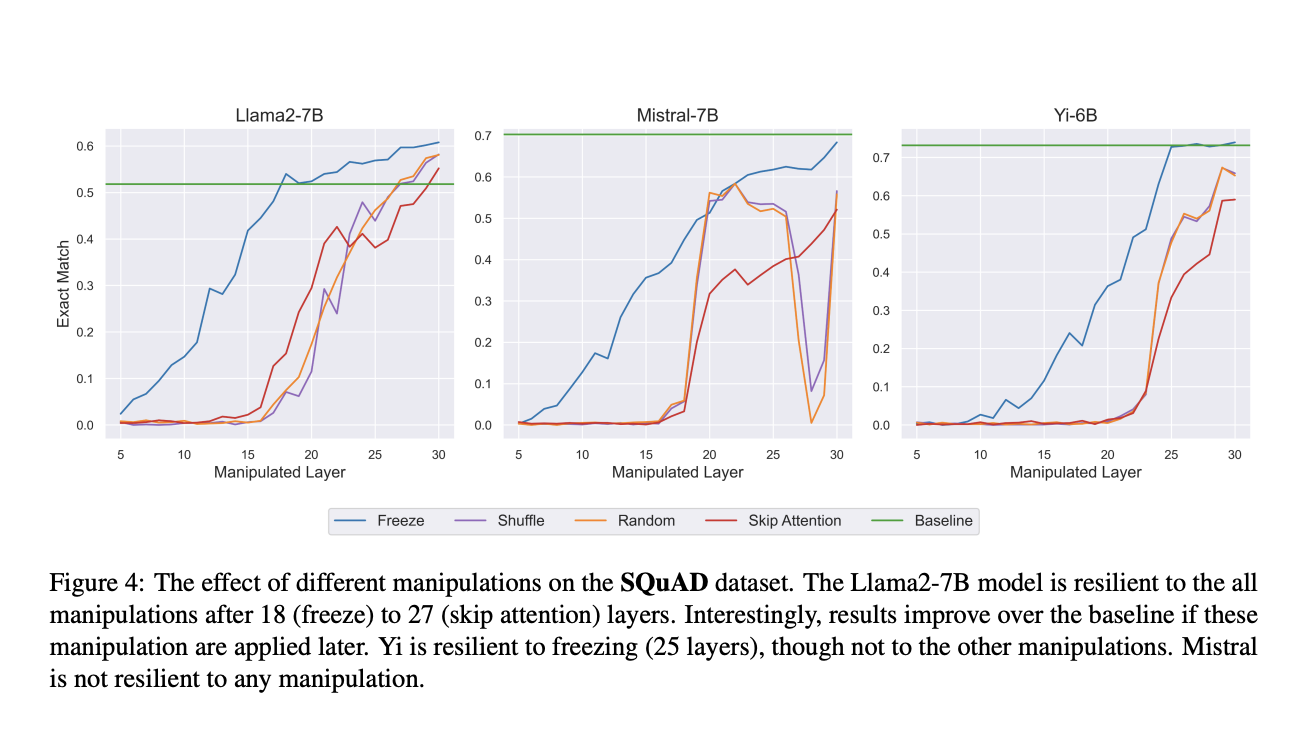
Исследователи обнаружили, что когда эти манипуляции применялись к верхним 30-50% модели, производительность на нескольких задачах почти не снизилась, что свидетельствует о том, что верхние уровни меньше полагаются на скрытые представления предыдущих токенов. Например, при замораживании до 50% уровней модели сохраняли производительность, сравнимую с базовой. Кроме того, замена скрытых состояний из разных подсказок дополнительно подтвердила это наблюдение; модель игнорировала изменения, внесенные в верхние уровни, тогда как изменения на более низких уровнях значительно изменяли результат. Эксперименты проводились для понимания, требуется ли внимание на более высоких уровнях модели, пропуская блок внимания на этих уровнях. Этот тест показал, что пропуск внимания на верхних уровнях имел минимальное влияние на задачи, такие как резюмирование и вопросно-ответная система, в то время как это привело к серьезному снижению производительности на более низких уровнях.
В заключение, исследование раскрывает двухфазный процесс в LLMs на основе трансформера: начальные уровни собирают информацию от предыдущих токенов, в то время как более высокие уровни в основном обрабатывают эту информацию внутренне. Полученные результаты указывают на то, что более высокие уровни менее зависят от детального представления предыдущих токенов, предлагая потенциальные оптимизации, такие как пропуск внимания на этих уровнях для снижения вычислительных затрат. В целом, статья погружается в иерархическую природу обработки информации в LLMs и приводит к более обоснованным и эффективным моделям.
Посмотреть статью
Вся заслуга за это исследование принадлежит исследователям этого проекта.
Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу из более чем 50 тысяч человек на ML SubReddit.
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИИ: «SAM 2 для видео: Как настроить на ваши данные» (Ср, 25 сентября, 4:00 — 4:45 EST)
Эта публикация была опубликована на MarkTechPost.
«`
«`html
Практическое применение исследования
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте «Изучение скрытых слоев в больших языковых моделях LLMs».
— Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
— Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
— Подберите подходящее решение, сейчас очень много вариантов ИИ.
— Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
— На полученных данных и опыте расширяйте автоматизацию.
— Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai.
— Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
— Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
— Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















