
«`html
Самообучение (SSL) расширило возможности речевых технологий для многих языков, минимизируя необходимость в размеченных данных. Однако текущие модели поддерживают только 100-150 из более чем 7 000 языков мира. Ограничение это в значительной степени обусловлено недостатком транскрибированной речи, так как лишь около половины этих языков имеют формальные письменные системы, и еще меньше из них имеют ресурсы для создания обширных размеченных данных, необходимых для обучения. Проекты, такие как MMS, расширили охват на более чем 1 000 языков, но нуждаются в помощи в обработке шума данных и в разнообразных условиях записи.
Решение XEUS
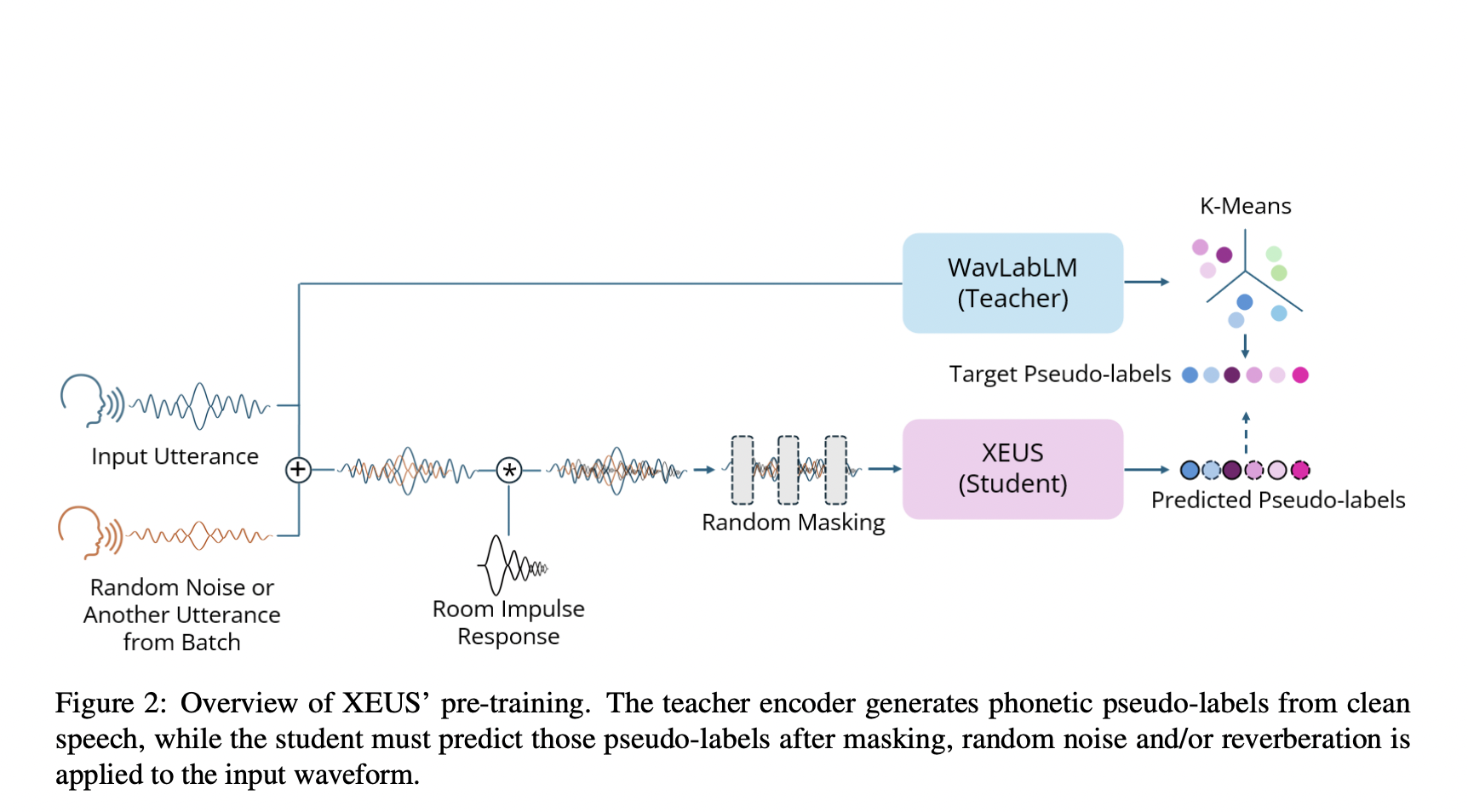
Исследователи из Университета Карнеги-Меллона, Шанхайского Жяотунского университета и Технологического института Тойоты в Чикаго разработали XEUS, кросс-языковой кодировщик универсальной речи. XEUS обучен на более чем 1 миллионе часов данных из 4 057 языков, значительно увеличивая охват языков для моделей SSL. Это включает новый корпус из 7 413 часов из 4 057 языков, который будет общедоступно выпущен. XEUS включает новую цель дереверберации для улучшенной устойчивости. Он превосходит современные модели в различных бенчмарках, включая ML-SUPERB. Для поддержки дальнейших исследований исследователи выпустят XEUS, его код, конфигурации обучения, контрольные точки и журналы обучения.
Преимущества и применение
SSL улучшило обработку речи, позволяя нейронным сетям учиться на больших объемах неразмеченных данных, которые затем могут быть донастроены для различных задач. Мультиязычные модели SSL могут использовать кросс-языковое обучение передачи, но охватывают лишь несколько языков. XEUS, однако, охватывает 4 057 языков, превосходя модели, такие как MMS. XEUS включает новую цель дереверберации во время обучения для обработки шумной и разнообразной речи. В отличие от современных моделей, которые часто используют закрытые наборы данных и лишены прозрачности, XEUS полностью открыт, с общедоступными данными, кодом обучения и обширной документацией, способствуя дальнейшим исследованиям масштабного мультиязычного SSL.
Обучение и оценка
XEUS предварительно обучен на обширном наборе данных в 1,081 миллиона часов из 4 057 языков, собранных из 37 общедоступных наборов речи и дополнительных источников, таких как Global Recordings Network, WikiTongues и Jesus Dramas. Уникальные типы данных улучшают его устойчивость, такие как акцентированная речь и смешивание кодов. XEUS включает новые цели, включая дереверберацию и уменьшение шума, во время обучения. Архитектура модели основана на HuBERT, но включает улучшения, такие как слои E-Branchformer и упрощенная функция потерь. Обучение на 64 графических процессорах NVIDIA A100 использует передовые техники аугментации и охватывает значительно больше данных, чем предыдущие модели.
Результаты и применение
Модель XEUS оценивается на различных задачах для оценки ее мультиязычных и акустических возможностей. Она превосходит другие модели в мультиязычных речевых задачах, превосходя современные модели, такие как XLS-R, MMS и w2v-BERT, на бенчмарках, таких как ML-SUPERB и FLEURS, особенно в условиях языков с ограниченными ресурсами. Кроме того, XEUS проявляет сильную производительность в универсальности задач, соответствуя или превосходя ведущие модели в задачах только на английском языке, таких как распознавание эмоций и диаризация диктора. В акустическом представлении XEUS превосходит модели, такие как WavLM и w2v-BERT, в генерации высококачественной речи, что подтверждается метриками, такими как MOS и WER.
Заключение
XEUS — это надежный кодировщик речи SSL, обученный на более чем 1 миллионе часов данных из 4 057 языков, демонстрирующий превосходную производительность в широком спектре мультиязычных и низкоресурсных задач. Задача дереверберации улучшает его устойчивость, и несмотря на ограниченные данные для многих языков, он все равно предоставляет ценные результаты. XEUS продвигает мультиязычные исследования, предоставляя открытый доступ к своим данным и модели. Однако важны этические соображения, особенно при работе с речевыми данными от коренных сообществ и предотвращении их злоупотребления, такого как создание аудио-дипфейков. Интеграция XEUS с доступными платформами направлена на демократизацию разработки речевых моделей.
Подробнее о работе можно узнать в статье, наборе данных и модели. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забывайте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему SubReddit с более чем 46 000 подписчиков.
«`




















