
«`html
Глубокое обучение и его применение в искусственном интеллекте
Глубокое обучение сделало значительные шаги в области искусственного интеллекта, особенно в обработке естественного языка и компьютерном зрении. Однако даже самые передовые системы часто терпят неудачи, выходящие за рамки человеческого понимания, что подчеркивает критическую разницу между искусственным и человеческим интеллектом. Это возродило дебаты о том, обладают ли нейронные сети основными компонентами человеческого познания. Основной вызов заключается в разработке систем, проявляющих более похожее на человеческое поведение, особенно в отношении устойчивости и обобщения. В отличие от людей, способных адаптироваться к изменениям окружающей среды и обобщать в различных визуальных ситуациях, модели искусственного интеллекта часто нуждаются в помощи при сдвиге данных между обучающими и тестовыми наборами. Этот недостаток устойчивости в визуальных представлениях представляет существенные вызовы для последующих приложений, требующих сильных обобщающих способностей.
Уникальная методология AligNet для выравнивания визуальных представлений
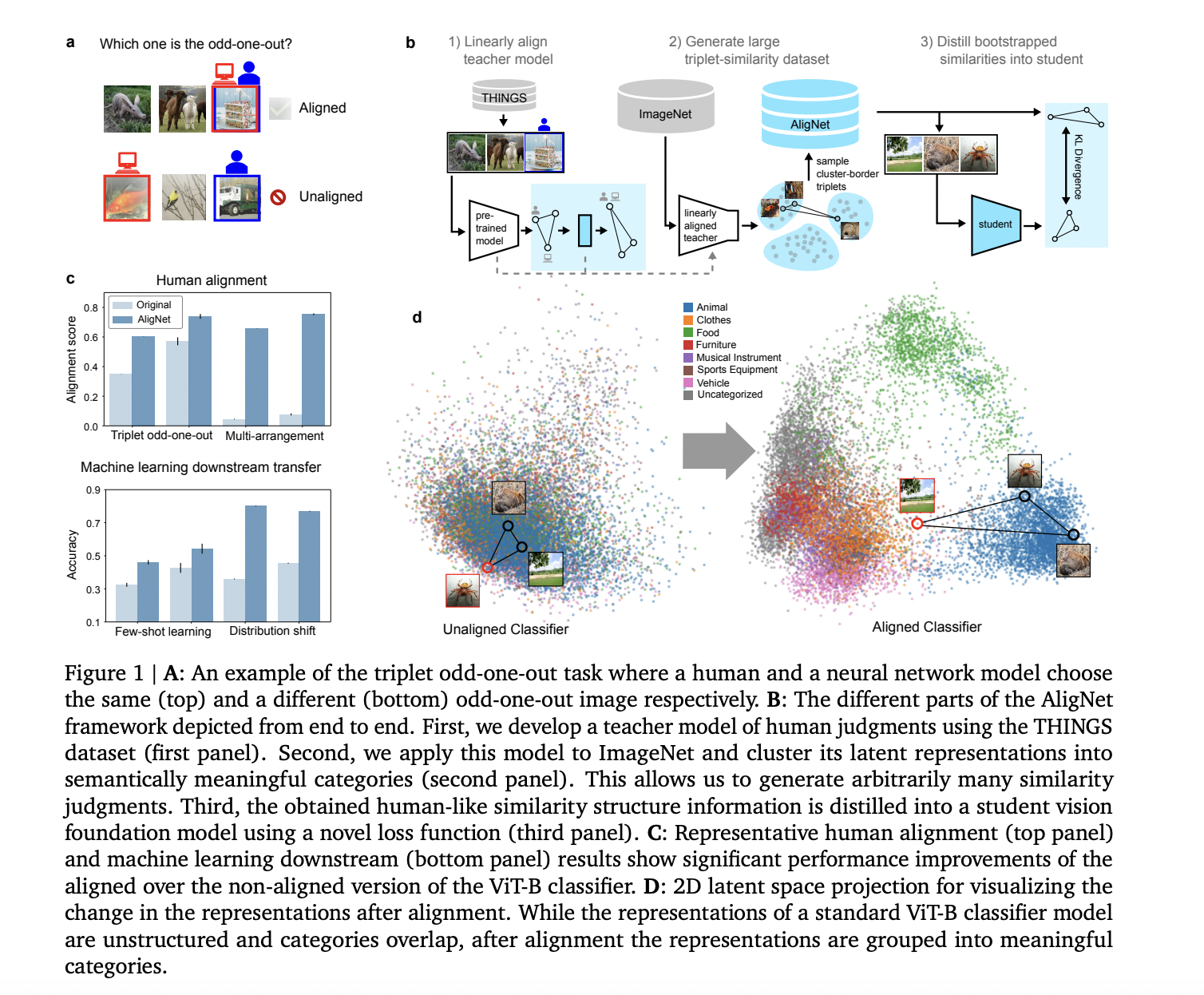
Исследователи из Google DeepMind, Machine Learning Group, Technische Universität Berlin, BIFOLD, Berlin Institute for the Foundations of Learning and Data, Max Planck Institute for Human Development, Anthropic, Department of Artificial Intelligence, Korea University, Seoul, Max Planck Institute for Informatics предлагают уникальную методологию под названием AligNet для решения несоответствия между человеческими и машинными визуальными представлениями. Этот подход направлен на моделирование масштабных наборов данных о сходстве, похожих на человеческие, для выравнивания моделей нейронных сетей с человеческим восприятием. Методология начинается с использования аффинного преобразования для выравнивания визуальных представлений модели с человеческими семантическими суждениями в задачах тройных «нечетных» задач. Этот процесс включает меры неопределенности из ответов людей для улучшения калибровки модели. Выровненная версия передовой модели визуального фундамента (VFM) затем служит заменой для генерации сходства, похожего на человеческое, с помощью модели AligNet.
Результаты и практические применения
Результаты демонстрируют значительные улучшения в выравнивании машинных представлений с человеческими суждениями на различных уровнях абстракции. Для глобальной грубой семантики мягкое выравнивание существенно улучшило производительность модели, с точностью, увеличившейся с 36,09-57,38% до 65,70-68,56%, превышая показатель надежности человека-человека в 61,92%. Для локальной тонкой семантики выравнивание улучшилось умеренно, с точностью, возросшей с 46,04-57,72% до 58,93-62,92%. Для троек, связанных с классами, тонкая настройка AligNet достигла замечательного выравнивания, с точностью, достигающей 93,09-94,24%, превышая предел шума человека в 89,21%. Эффективность выравнивания различалась на разных уровнях абстракции, при этом различные модели проявляли сильные стороны в различных областях. Важно отметить, что тонкая настройка AligNet хорошо обобщается на другие наборы данных о сходстве человека, демонстрируя существенные улучшения в выравнивании на различных задачах сходства объектов, включая многоразмещение и попарные оценки сходства по шкале Ликерта.
Методология AligNet и ее ключевые шаги
Методология AligNet включает несколько ключевых шагов для выравнивания машинных представлений с человеческим визуальным восприятием. Вначале она использует набор данных THINGS для изучения аффинного преобразования в глобальное человеческое пространство сходства объектов. Это преобразование применяется к представлениям модели-учителя, создавая матрицу сходства для пар объектов. Процесс включает меры неопределенности в ответах людей с использованием метода приближенного байесовского вывода, заменяя жесткое выравнивание мягким выравниванием.
Целью функции обучения преобразования неопределенности является объединение мягкого выравнивания с регуляризацией для сохранения локальной структуры сходства. Преобразованные представления затем кластеризуются в суперординарные категории с использованием кластеризации k-средних. Эти кластеры направляют генерацию троек из различных изображений ImageNet, с выбором «нечетных» вариантов, определяемых моделью-учителем.
Наконец, устойчивая целевая функция на основе дивергенции Кульбака-Лейблера облегчает дистилляцию парного сходства учителя в сеть студента. Эта цель AligNet комбинируется с регуляризацией для сохранения пространства предварительного обучения, что приводит к тонкой настройке модели студента, которая лучше соответствует человеческим визуальным представлениям на различных уровнях абстракции.
Заключение
Данное исследование решает критическое недостаток моделей визуального фундамента: их неспособность адекватно представлять многоуровневую концептуальную структуру человеческих семантических знаний. Разработка методологии AligNet, которая выравнивает модели глубокого обучения с человеческими суждениями о сходстве, демонстрирует значительные улучшения производительности модели на различных когнитивных и машинном обучении задачах. Полученные результаты вносят вклад в текущие дебаты о способности нейронных сетей улавливать человекоподобный интеллект, особенно в отношении отношений и иерархической организации знаний. В конечном итоге данная работа иллюстрирует, как выравнивание представлений может улучшить обобщение и устойчивость модели, сокращая разрыв между искусственным и человеческим визуальным восприятием.
Проверьте статью. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу Reddit.
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ: «SAM 2 для видео: как настроить на ваши данные» (Ср, 25 сентября, 4:00 — 4:45 EST)
Источник: MarkTechPost