
«`html
Текущие методологии Text-to-SQL
Существующие методы Text-to-SQL в основном опираются на модели глубокого обучения, в частности, модели Sequence-to-Sequence (Seq2Seq), которые стали основными благодаря своей способности преобразовывать естественный язык напрямую в SQL без промежуточных этапов. Эти модели, усиленные предварительно обученными языковыми моделями (PLM), устанавливают современные стандарты в этой области, используя масштабные корпуса для улучшения своих лингвистических возможностей. Однако переход к большим языковым моделям (LLM) обещает еще более высокую производительность благодаря их масштабным законам и вновь возникающим способностям. Эти LLM с их значительным количеством параметров могут захватывать сложные закономерности в данных, что делает их отлично подходящими для задачи Text-to-SQL.
Исследование из Пекинского университета
Новая научная статья из Пекинского университета рассматривает проблему преобразования естественных языковых запросов в SQL-запросы, процесс, известный как Text-to-SQL. Это преобразование критически важно для обеспечения доступности баз данных для неспециалистов, которые могут не знать SQL, но нуждаются во взаимодействии с базами данных для извлечения информации. Внутренняя сложность синтаксиса SQL и тонкости, связанные с пониманием схемы базы данных, делают это значительной проблемой в обработке естественного языка (NLP) и управлении базами данных.
Предложенный метод
Предложенный метод в данной статье использует LLM для задач Text-to-SQL через две основные стратегии: инженерия запросов и тонкая настройка. Инженерия запросов включает такие техники, как Retrieval-Augmented Generation (RAG), обучение с малым количеством данных и рассуждения, которые требуют меньше данных, но могут давать оптимальные результаты только иногда. С другой стороны, тонкая настройка LLM с данными, специфичными для задачи, может значительно улучшить производительность, но требует большого набора данных для обучения. В статье исследуется баланс между этими подходами с целью найти оптимальную стратегию, которая максимизирует производительность LLM в генерации точных SQL-запросов из естественных языковых вводов.
Многоступенчатые методы рассуждения
Статья исследует различные многоступенчатые методы рассуждения, которые могут быть применены к LLM для задач Text-to-SQL. К ним относятся Chain-of-Thought (CoT), который направляет LLM на генерацию ответов шаг за шагом, добавляя конкретные запросы для разбиения задачи; Least-to-Most, который разбивает сложную проблему на более простые подзадачи; и Self-Consistency, который использует стратегию большинства для выбора наиболее частого ответа, сгенерированного LLM. Каждый метод помогает LLM генерировать более точные SQL-запросы, имитируя человеческий подход к решению сложных проблем пошагово и итеративно.
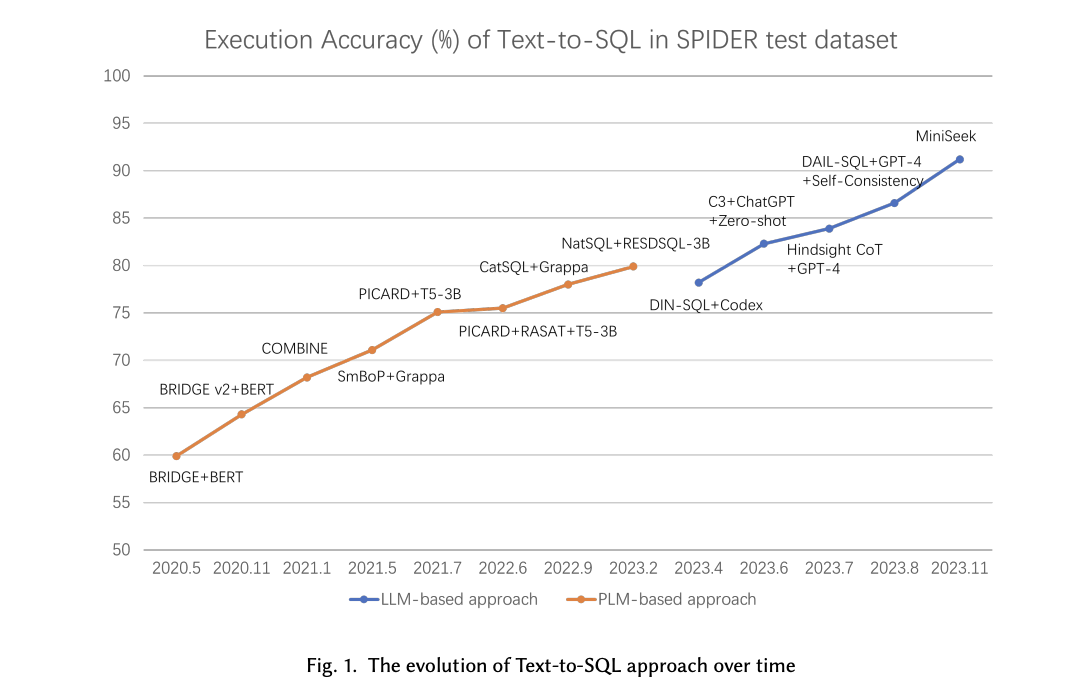
Производительность и выводы
Статья подчеркивает, что применение LLM значительно улучшило точность выполнения задач Text-to-SQL. Например, современная точность на бенчмарк-наборах данных, таких как Spider, выросла с примерно 73% до 91,2% с интеграцией LLM. Однако остаются вызовы, особенно с появлением новых наборов данных, таких как BIRD и Dr.Spider, которые представляют более сложные сценарии и тесты на устойчивость. Исследования показывают, что даже продвинутые модели, такие как GPT-4, все еще сталкиваются с определенными изменениями, достигая только 54,89% точности на наборе данных BIRD. Это подчеркивает необходимость дальнейших исследований и разработок в этой области.
Заключение
Статья предоставляет всесторонний обзор использования LLM для задач Text-to-SQL, выделяя потенциал многоступенчатых методов рассуждения и стратегий тонкой настройки для улучшения производительности. Решая проблемы преобразования естественного языка в SQL, это исследование прокладывает путь для более доступного и эффективного взаимодействия с базами данных для неспециалистов. Предложенные методы и детальные оценки демонстрируют значительные прогрессивные достижения в этой области, обещая более точные и эффективные решения для прикладных задач. Эта работа продвигает современные стандарты в области Text-to-SQL и подчеркивает важность использования возможностей LLM для сокрытия разрыва между пониманием естественного языка и запросами к базам данных.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 47 тыс. ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Опубликовано на MarkTechPost.
«`



















