
«`html
Конструирование графов знаний из неструктурированных данных
Конструирование графов знаний (Knowledge Graphs, KGs) из неструктурированных данных представляет собой сложную задачу из-за трудностей извлечения и структурирования значимой информации из сырого текста. Неструктурированные данные часто содержат неразрешенные или дублированные сущности и несогласованные отношения, что затрудняет их преобразование в целостный граф знаний. Кроме того, огромное количество неструктурированных данных в различных областях подчеркивает необходимость масштабируемых методов для автоматической обработки, извлечения и структурирования этих данных в графы знаний. Эффективное решение этих проблем критически важно для обеспечения эффективного рассуждения, выводов и принятия решений на основе данных в областях от научных исследований до анализа веб-данных.
Традиционные методы построения графов знаний из неструктурированного текста
Традиционные методы построения графов знаний из неструктурированного текста в основном опираются на такие техники, как распознавание именованных сущностей, извлечение отношений и разрешение сущностей. Эти подходы часто ограничены необходимостью заранее определенных типов сущностей и отношений, часто зависящих от онтологий, специфичных для области. Кроме того, они обычно включают надзорное обучение, которое требует большого количества размеченных данных. Существенным ограничением этих методов является их склонность к созданию несогласованных графов с дублированными или неразрешенными сущностями, что приводит к избыточности и неоднозначностям, требующим обширной последующей обработки. Кроме того, многие существующие решения зависят от тематики, что ограничивает их применимость в различных областях, что снижает их масштабируемость и адаптивность к новым случаям использования.
Решение iText2KG
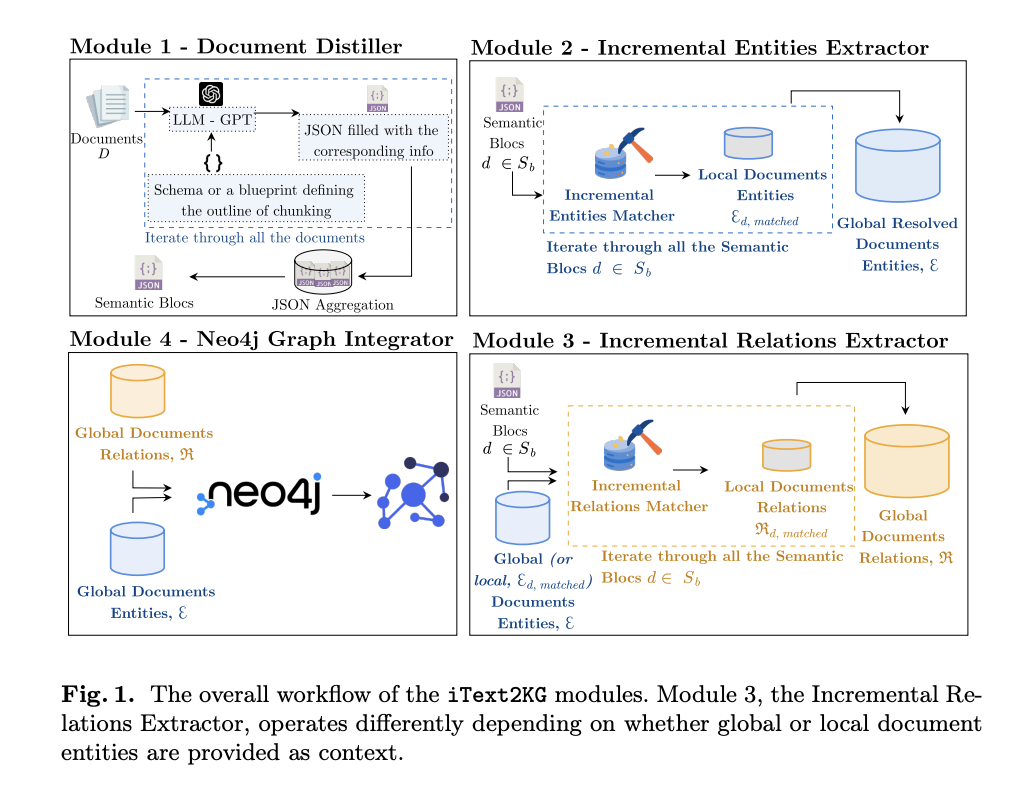
Исследователи из INSA Lyon, CNRS и Universite Claude Bernard Lyon 1 представляют iText2KG — нулевой, тематически независимый метод поэтапного построения графов знаний из неструктурированных данных без необходимости заранее определенных онтологий или последующей обработки. Эта система состоит из четырех отдельных модулей:
- Document Distiller: преобразует сырые документы в семантические блоки с использованием больших языковых моделей (LLMs) под руководством гибкой, определенной пользователем схемы.
- Incremental Entity Extractor: извлекает уникальные сущности из семантических блоков, обеспечивая отсутствие дублирования или семантических неоднозначностей.
- Incremental Relation Extractor: идентифицирует и извлекает семантически уникальные отношения между сущностями.
- Graph Integrator: визуализирует сущности и отношения в граф знаний с использованием Neo4j, обеспечивая структурированное представление данных.
Этот модульный дизайн разделяет задачи извлечения сущностей и отношений, что приводит к улучшению точности и последовательности. Более того, использование парадигмы нулевого обучения обеспечивает адаптивность в различных областях без необходимости тонкой настройки или повторного обучения, делая его гибким, точным и масштабируемым решением для построения графов знаний.
В заключение, iText2KG представляет собой значительное достижение в построении графов знаний, предоставляя гибкий, тематически независимый подход, способный структурировать неструктурированные данные в согласованные графы знаний. Модульное выполнение задач извлечения сущностей и отношений и применение поэтапного процесса позволяет преодолеть основные ограничения традиционных подходов, таких как зависимость от заранее определенных онтологий и обширной последующей обработки. С превосходной производительностью на различных типах документов iText2KG демонстрирует огромный потенциал для широкого применения в областях, требующих структурированные знания из неструктурированного текста, предлагая надежное, масштабируемое и эффективное решение для построения графов знаний.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИИ: «SAM 2 для видео: как настроить на ваши данные» (Ср, 25 сентября, 4:00 — 4:45 EST)
Источник: MarkTechPost