
«`html
Преодоление барьеров: масштабирование мультимодального искусственного интеллекта с помощью CuMo
Появление больших языковых моделей (LLM), таких как GPT-4, вызвало волну восторга вокруг их усовершенствования с мультимодальными возможностями для понимания визуальных данных наряду с текстом. Однако предыдущие усилия по созданию мощных мультимодальных LLM столкнулись с проблемами масштабирования и поддержания производительности. Для устранения этих проблем исследователи черпали вдохновение из архитектуры смеси экспертов (MoE), широко используемой для масштабирования LLM путем замены плотных слоев разреженными экспертными модулями.
Реализация MoE
В подходе MoE вместо передачи входных данных через одну большую модель есть множество более мелких экспертных подмоделей, каждая из которых специализируется на подмножестве данных. Сеть маршрутизации определяет, какой(е) эксперт(ы) должен обрабатывать каждый входной пример, что позволяет масштабировать общую емкость модели более параметрически эффективным способом.
Интеграция CuMo
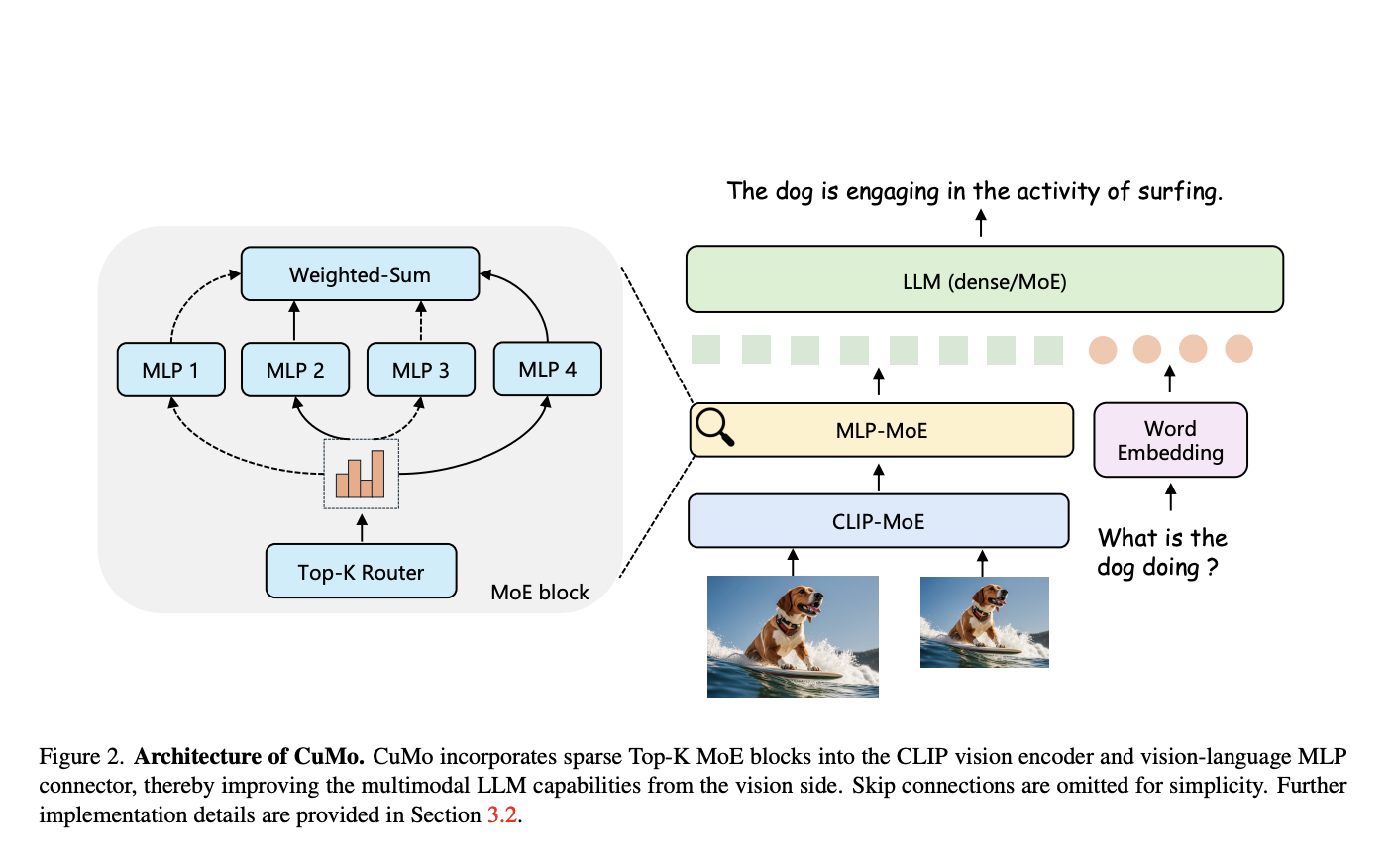
В своем подходе исследователи интегрировали разреженные блоки MoE (показано на рисунке 2) в визионный кодер и соединитель визионного и языкового модулей мультимодального LLM. Это позволяет различным экспертным модулям обрабатывать различные части визуальных и текстовых входов параллельно, вместо того чтобы полагаться на монолитную модель для анализа всего.
Ключевая инновация — концепция совместного переобучения
Вместо обучения разреженных блоков MoE с нуля, они инициализируются из предварительно обученной плотной модели перед тонкой настройкой. Это обеспечивает лучшую отправную точку для специализации экспертов во время обучения.
Трехэтапный процесс обучения CuMo
Для обучения CuMo используется тщательный трехэтапный процесс:
1) Предварительное обучение только соединителя визионного и языкового модулей на изображениях и тексте, например, на данных LLaVA, для выравнивания модальностей.
2) Предварительная тонкая настройка всех параметров модели на подписях из ALLaVA для разогрева всей системы.
3) Наконец, тонкая настройка с визуальными инструкциями из наборов данных, таких как VQAv2, GQA и LLaVA-Wild, вводит разреженные блоки MoE вместе с вспомогательными потерями для балансировки нагрузки экспертов и стабилизации обучения.
Этот комплексный подход, интегрирующий разреженность MoE в мультимодальные модели через совместное переобучение и тщательное обучение, позволяет CuMo масштабироваться более эффективно по сравнению с простым увеличением размера модели.
Оценка моделей CuMo
Исследователи оценили модели CuMo на ряде бенчмарков визуального вопросно-ответного тестирования, таких как VQAv2 и GQA, а также на вызовах мультимодального рассуждения, таких как MMMU и MathVista. Их модели, как показано на рисунке 1, обученные исключительно на общедоступных наборах данных, превзошли другие современные подходы в пределах одинаковых категорий размеров моделей.
Эти впечатляющие результаты подчеркивают потенциал разреженных архитектур MoE в сочетании с совместным переобучением для разработки более способных, но при этом эффективных мультимодальных AI-ассистентов. Поскольку исследователи опубликовали свою работу в открытом доступе, CuMo может проложить путь для нового поколения AI-систем, способных без проблем понимать и рассуждать о тексте, изображениях и не только.
Ознакомьтесь с статьей и GitHub. Вся заслуга за это исследование принадлежит исследователям проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпреддиту по машинному обучению (ML) с более чем 42 тысячами участников.
Этот пост был опубликован на MarkTechPost.
«`




















