
«`html
Революция в компьютерном зрении с помощью Pixel Transformer
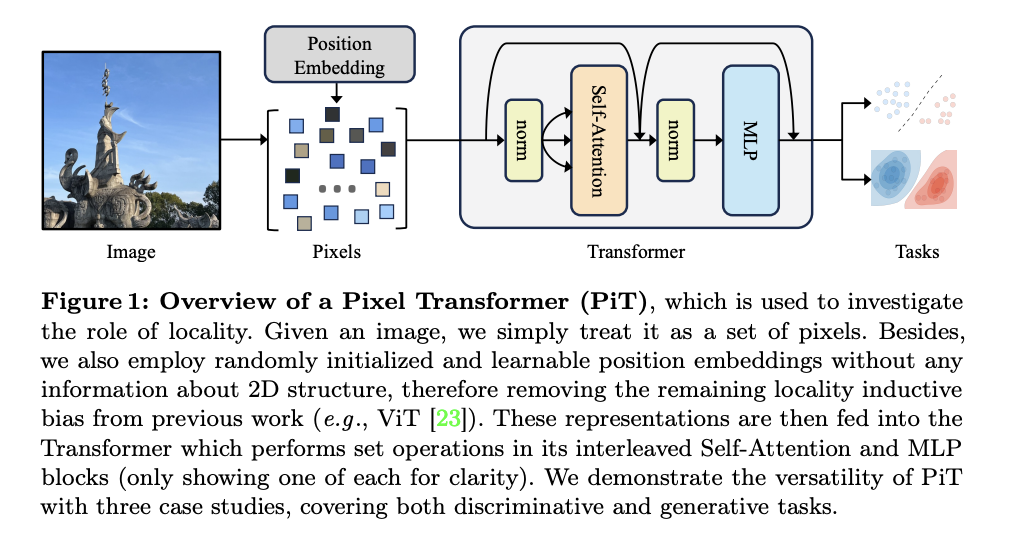
Глубокое обучение в компьютерном зрении перешло от ручно созданных признаков к подходам, основанным на данных, подчеркивая потенциал снижения смещений признаков. Этот переход направлен на создание более универсальных систем, которые превосходят в различных задачах зрения. Vision Transformer (ViT) снижает пространственную иерархию, сохраняя трансляционную эквивариантность и локальность через проекцию патчей и позиционные вложения. Однако вызов заключается в устранении оставшихся смещений, чтобы дальше улучшить производительность и универсальность модели.
Практические решения и ценность
Исследователи из FAIR, Meta AI и Университета Амстердама представляют подход «Pixel Transformer» (PiT), который демонстрирует эффективность в различных задачах, включая классификацию, самообучение и генерацию изображений. PiT превосходит базовые модели, оснащенные локальными смещениями. Это открывает новые возможности для проектирования следующего поколения моделей в компьютерном зрении и за его пределами, что может привести к более универсальным и масштабируемым архитектурам.
Подробнее ознакомиться с исследованием.
Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
«`



















