
«`html
Перспективы и область автоматизации в цифровой жизни
Развитие способностей к инструктированию, кодированию и использованию инструментов больших языковых моделей (LLM) расширяет перспективы и область автоматизации в цифровой жизни. Большинство повседневных цифровых задач включают сложные действия в различных приложениях, требующие рассуждений и принятия решений на основе промежуточных результатов. Однако развитие таких автономных агентов требует тщательной, воспроизводимой и надежной оценки с использованием реалистичных задач, учитывающих сложности и динамику реальных цифровых сред.
Текущие бенчмарки и их ограничения
Существующие бенчмарки для инструментальных решений не могут решить эту проблему, поскольку они используют линейную последовательность вызовов API без обширного или интерактивного кодирования, и их оценка через эталонные решения не подходит для сложных задач с разнообразными решениями.
Предложенные решения и их практическое применение
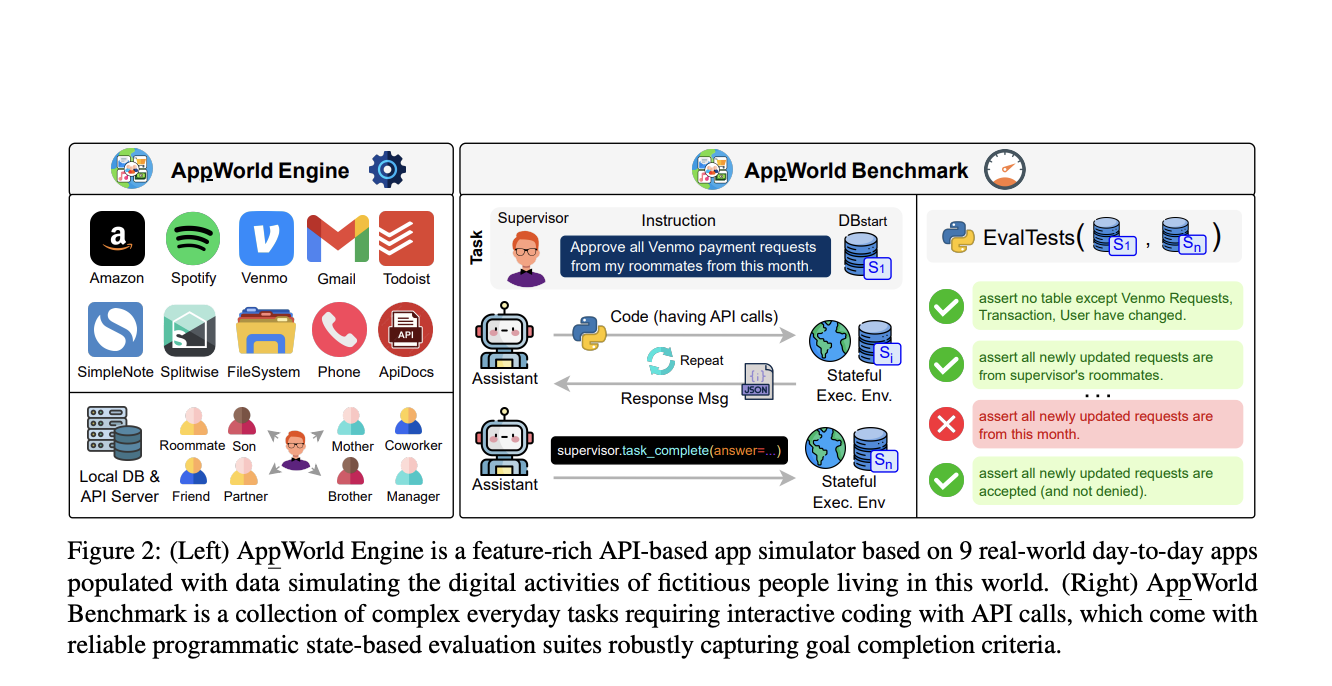
Исследователи из Университета Стоуни-Брук, Института искусственного интеллекта Аллена и Университета Заарландии предложили AppWorld Engine — высококачественную среду выполнения, включающую 60 тыс. строк кода. Эта среда включает 9 повседневных приложений, работающих через 457 API, и моделирует реалистичные цифровые действия для приблизительно 100 вымышленных пользователей.
AppWorld Engine реализует 9 приложений в различных областях, включая электронную почту (Gmail), перевод денег (Venmo), покупки (Amazon) и локальные файловые системы. Он содержит 457 API, среднее количество API на приложение — 50, и включает 1470 аргументов. Эти API выполняют действия через операции чтения/записи в базе данных. Кроме того, реализованы два вспомогательных приложения: ApiDocs предоставляет API для интерактивной документации, а Supervisor API предоставляет информацию о назначителе задач, такую как адреса, платежные карты и пароли от учетных записей.
Результаты показывают, что все методы демонстрируют низкие оценки выполнения задач и сценариев как в тесте N, так и в тесте C. Сильнейшая модель, ReAct + GPT4O, достигает оценки выполнения задач 48,8 в тесте N, что снижается до 30,2 в тесте C. Вторая по силе модель, GPT4Trb, значительно уступает GPT4O, с оценкой выполнения задач 32,7 и 17,5 соответственно. Модель FullCodeRefl + LLaMA3 получает оценку выполнения задач 24,4 в тесте N и 7,0 в тесте C. CodeAct и ToolLLaMA не справились с задачами из-за узкоспециализированного обучения.
Заключение и перспективы применения
AppWorld Engine представляет собой среду выполнения из 60 тыс. строк кода и бенчмарк для интерактивных задач на основе API. Его программная система оценки и реалистичные вызовы обеспечивают тщательную оценку. Оценка современных моделей подчеркивает сложность AppWorld и проблемы, с которыми сталкиваются LLM при автоматизации задач. Модульность и расширяемость системы создают возможности для управления пользовательским интерфейсом, координации между несколькими агентами и изучения вопросов конфиденциальности и безопасности в цифровых помощниках.
Подробнее ознакомьтесь с научной статьей, GitHub и проектом. Все заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в ML SubReddit!
Узнайте, как AI Sales Bot может помочь в вашем бизнесе: AI Sales Bot.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab: ближайшие вебинары по ИИ.