
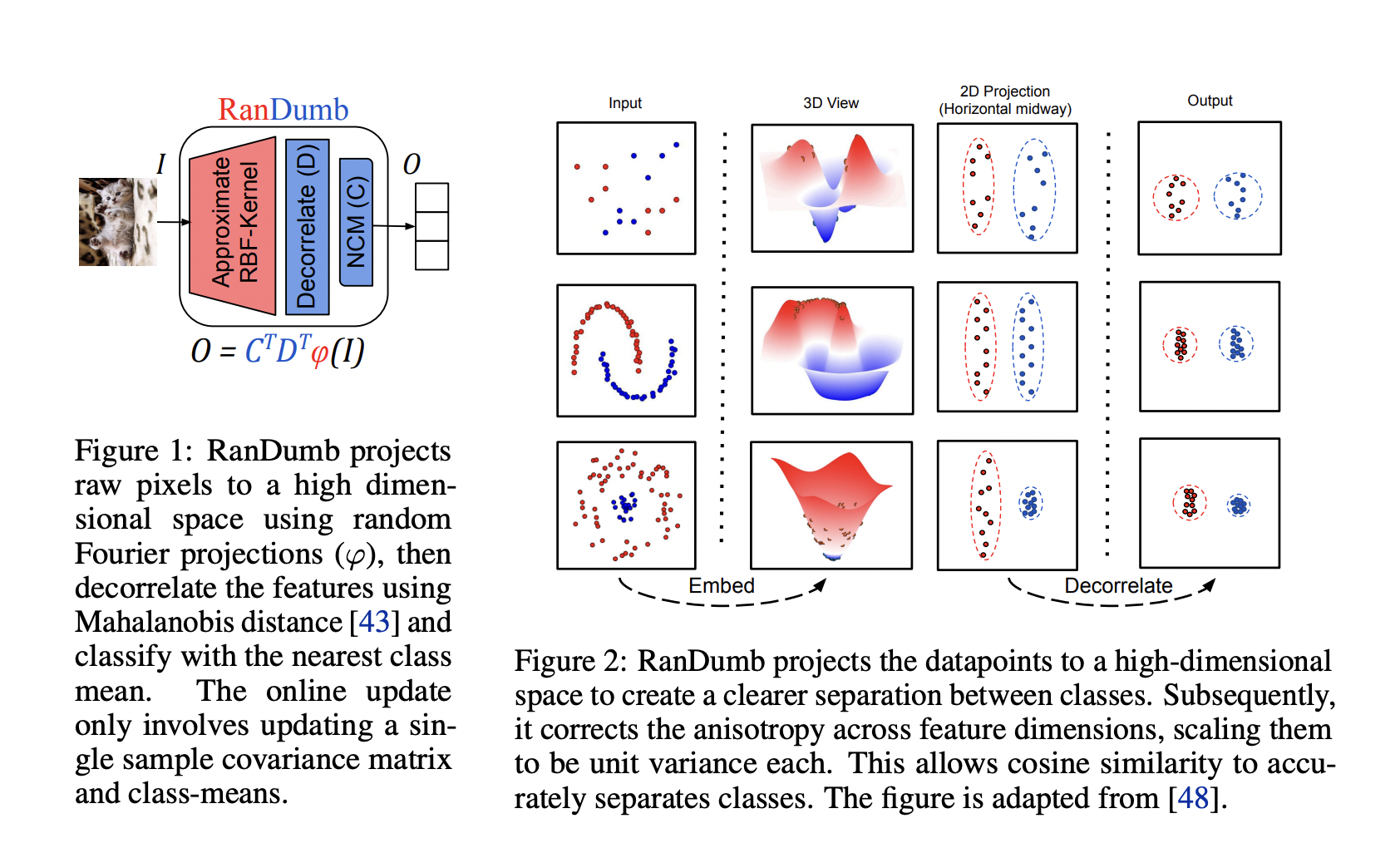
Практические решения и ценность RanDumb в области непрерывного обучения
Проблема «катастрофического забывания» и решение RanDumb
Непрерывное обучение требует моделей, способных адаптироваться к новым данным, сохраняя при этом ранее полученные знания. RanDumb предлагает простое и эффективное решение, используя комбинацию случайных преобразований Фурье и линейного классификатора для создания эффективных представлений для классификации без необходимости хранения образцов или частых обновлений. Этот метод превосходит многие существующие техники, устраняя необходимость в fein-tuning или сложных обновлениях нейронных сетей, что делает его идеальным для непрерывного обучения без образцов.
Эффективность и преимущества RanDumb
RanDumb встраивает данные в высокоразмерное пространство, обеспечивая точную классификацию за счет декорреляции признаков. Он оперирует с фиксированным случайным преобразованием для встраивания и требует только онлайн-обновлений матрицы ковариации и средних классов, что позволяет эффективно обрабатывать новые данные по мере их поступления. RanDumb не требует буферов памяти, что делает его идеальным решением для сред с ограниченными ресурсами.
Результаты и перспективы RanDumb
Экспериментальные оценки показывают, что RanDumb стабильно демонстрирует высокую производительность на различных бенчмарках непрерывного обучения. Например, на наборе данных MNIST RanDumb достиг точности 98.3%, превзойдя существующие методы на 5-15%. RanDumb показал точности 55.6% и 28.6% на бенчмарках CIFAR-10 и CIFAR-100 соответственно, превзойдя передовые методы, основанные на хранении предыдущих образцов. RanDumb отличается своей эффективностью и простотой в обработке даже больших наборов данных.





















