
«`html
Эффективное выравнивание больших языковых моделей (LLM) с человеческими инструкциями
Выравнивание больших языковых моделей (LLM) с человеческими инструкциями — критическая задача в области искусственного интеллекта. Текущие LLM-модели часто испытывают трудности в генерации ответов, которые были бы одновременно точными и контекстуально соответствующими инструкциям пользователя, особенно при использовании синтетических данных. Традиционные методы, такие как дистилляция моделей и аннотированные человеком наборы данных, имеют свои ограничения, включая проблемы масштабируемости и отсутствие разнообразия данных. Решение этих проблем является важным для улучшения производительности систем искусственного интеллекта в реальных приложениях, где они должны интерпретировать и выполнять широкий спектр задач, определенных пользователем.
Новый метод «перевода вперед и назад» для генерации синтетических данных
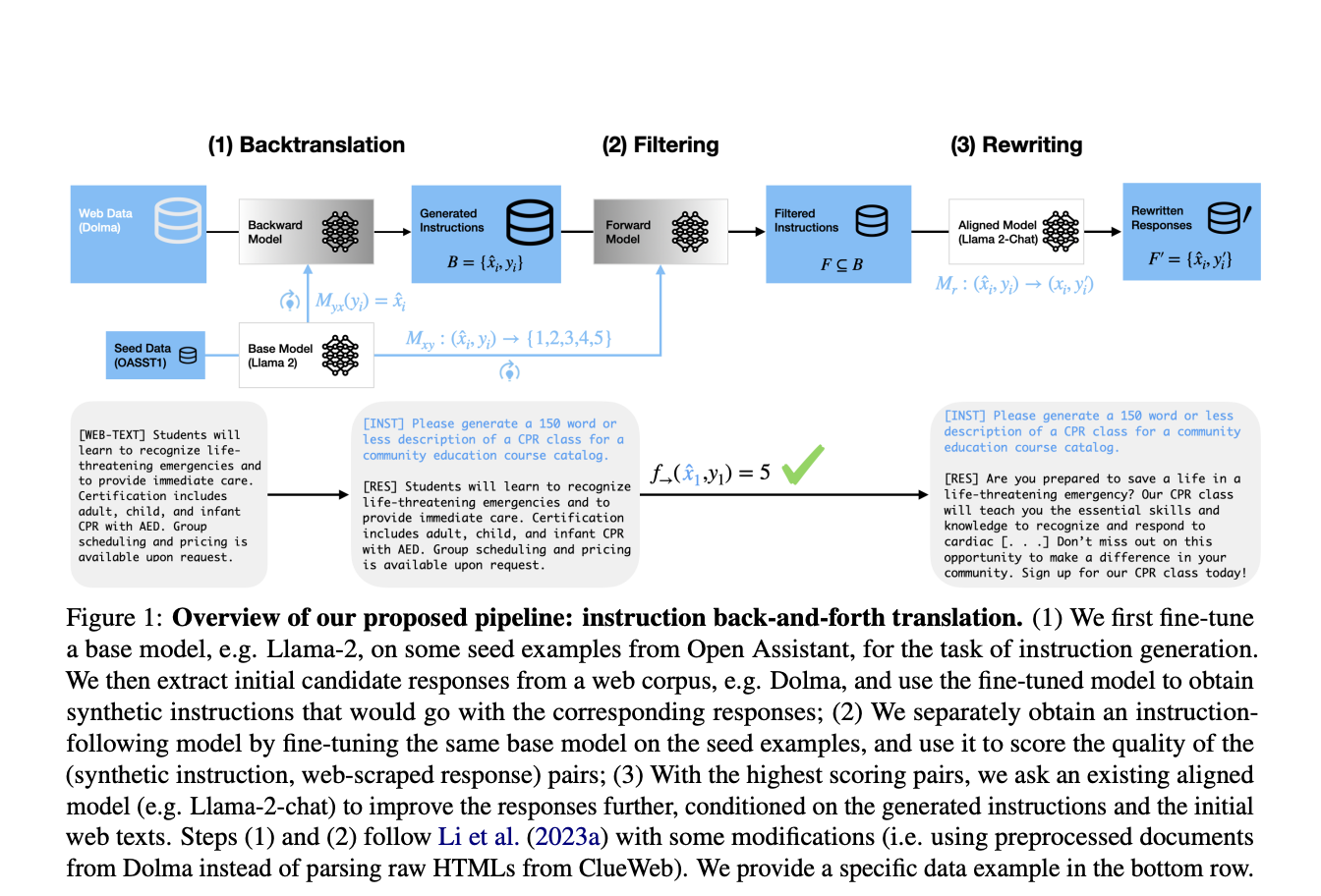
Исследователи из Университета Вашингтона и Meta Fair предлагают новый метод, известный как «перевод вперед и назад инструкций». Этот подход улучшает генерацию синтетических пар инструкция-ответ путем интеграции обратного перевода с переписыванием ответов. Изначально инструкции генерируются из существующих ответов, извлеченных из крупных веб-корпусов. Затем эти ответы уточняются LLM, который переписывает их, чтобы лучше соответствовать сгенерированным инструкциям. Этот инновационный метод использует богатое разнообразие информации, доступной в сети, обеспечивая высококачественные данные, соответствующие инструкциям, что является значительным прорывом в области.
Улучшение производительности моделей и их преимущества
Этот подход включает тонкую настройку базовой LLM на исходных данных для создания инструкций, соответствующих ответам, полученным из веб-сайтов. После генерации начальных пар инструкция-ответ происходит этап фильтрации, оставляющий только пары высокого качества. Выравненная LLM, такая как Llama-2-70B-chat, затем переписывает ответы, чтобы дополнительно улучшить их качество. Для генерации ответов используется метод nucleus sampling с акцентом на фильтрацию и переписывание для обеспечения качества данных. Тестирование на нескольких базовых наборах данных показывает превосходную производительность моделей, настроенных на синтетические данные, сгенерированные с помощью этой техники.
Значительное улучшение производительности моделей
Этот новый метод достигает значительных улучшений в производительности моделей по различным показателям. Модели, настроенные с использованием набора данных Dolma + фильтрация + переписывание, достигают победы в 91,74% на бенчмарке AlpacaEval, превосходя модели, обученные на других распространенных наборах данных, таких как OpenOrca и ShareGPT. Кроме того, они превосходят предыдущие подходы, использующие данные из ClueWeb, что демонстрирует их эффективность в генерации высококачественных и разнообразных данных, соответствующих инструкциям. Улучшенная производительность подчеркивает успех методики «перевода вперед и назад» в создании более точных и точно выравненных больших языковых моделей.
Заключение
Внедрение этого нового метода для генерации высококачественных синтетических данных является значительным прорывом в выравнивании LLM с человеческими инструкциями. Путем объединения обратного перевода с переписыванием ответов исследователи разработали масштабируемый и эффективный подход, который улучшает производительность моделей, следующих за инструкциями. Этот прорыв критичен для области искусственного интеллекта, предлагая более эффективное и точное решение для выравнивания инструкций, что является важным для внедрения LLM в практические приложения.
Проверьте статью. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI представляет Arcee Swarm: Революционное смешение агентов MoA Architecture, вдохновленное кооперативным интеллектом, обнаруженным в самой природе
Публикация Cracking the Code of AI Alignment: This AI Paper from the University of Washington and Meta FAIR Unveils Better Alignment with Instruction Back-and-Forth Translation в MarkTechPost.