
«`html
NVIDIA представляет Nemotron-4 340B: Семейство открытых моделей для генерации синтетических данных для обучения больших языковых моделей (LLM)
NVIDIA недавно представила Nemotron-4 340B, семейство моделей, разработанных для генерации синтетических данных для обучения больших языковых моделей (LLM) в различных коммерческих приложениях. Этот релиз является значительным прорывом в области генеративного искусственного интеллекта, предлагая полный набор инструментов, оптимизированных для NVIDIA NeMo и NVIDIA TensorRT-LLM, включая передовые модели инструкций и наград. Эта инициатива направлена на то, чтобы предоставить разработчикам эффективное и масштабируемое средство для доступа к высококачественным обучающим данным, что критически важно для улучшения производительности и точности пользовательских LLM. Nemotron-4 340B включает три варианта: модели инструкций, наград и базовые модели, каждая предназначена для определенных функций в процессе генерации и усовершенствования данных.
Модель Nemotron-4 340B Instruct
Эта модель предназначена для создания разнообразных синтетических данных, имитирующих характеристики реальных данных, улучшая производительность и надежность пользовательских LLM в различных областях. Эта модель важна для создания первоначальных выходных данных, которые могут быть улучшены и доработаны.
Модель Nemotron-4 340B Reward
Эта модель является ключевой в фильтрации и улучшении качества искусственно сгенерированных данных. Она оценивает ответы на основе полезности, правильности, связности, сложности и многословности. Эта модель гарантирует, что синтетические данные имеют высокое качество и соответствуют потребностям приложения.
Базовая модель Nemotron-4 340B
Служит основополагающим каркасом для настройки. Обученная на 9 трлн токенов, эта модель может быть тонко настроена с использованием собственных данных и различных наборов данных для адаптации к конкретным случаям использования. Она поддерживает обширную настройку через фреймворк NeMo, позволяя проводить надзорную тонкую настройку и эффективные методы параметрической адаптации, такие как LoRA.
Источник изображения
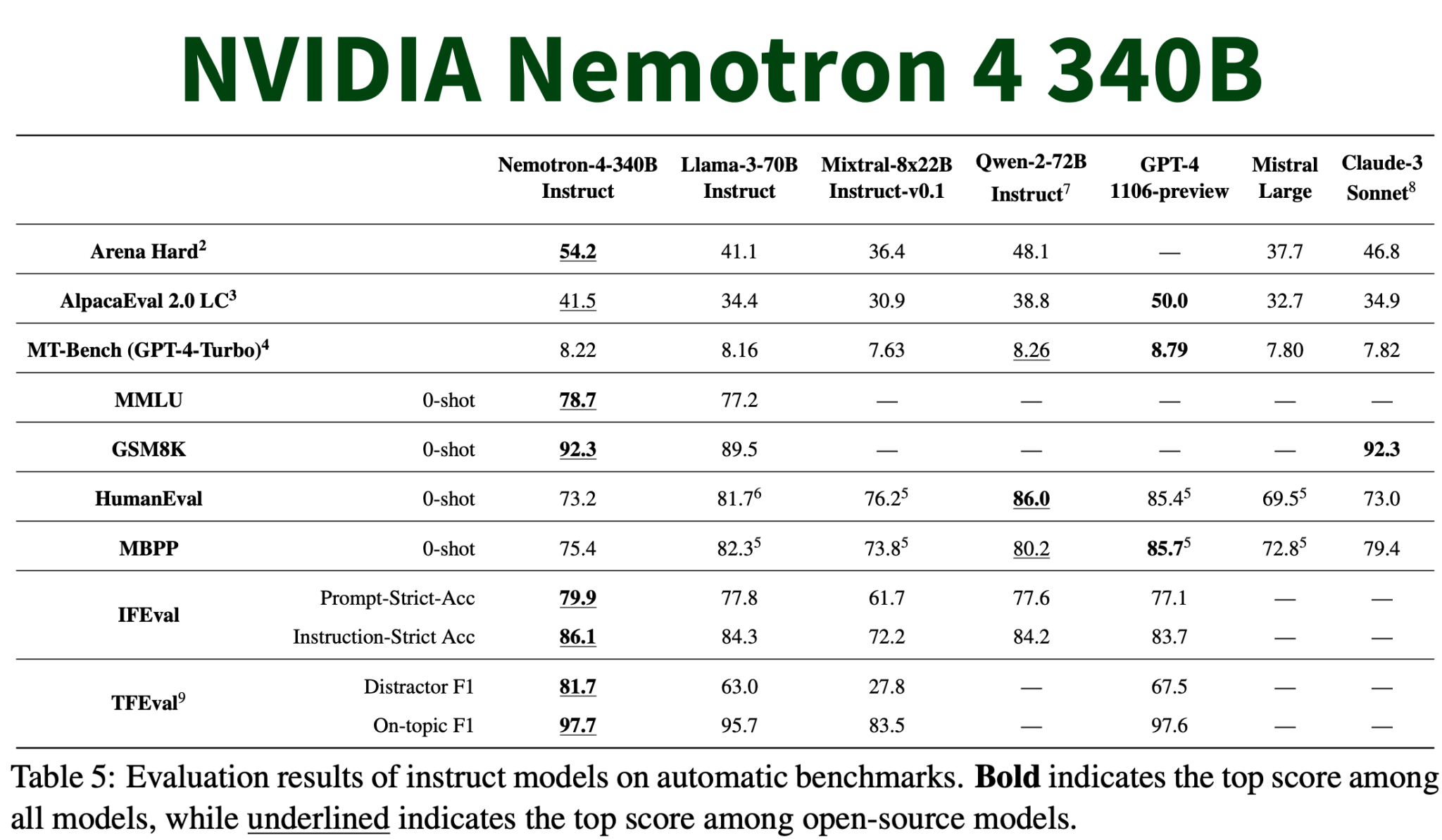
Это инновационное семейство моделей имеет впечатляющие спецификации, включая контекстное окно 4k, обучение в более чем 50 и 40 языках программирования, а также достижение заметных показателей, таких как 81,1 MMLU, 90,53 HellaSwag и 85,44 BHH. Модели требуют значительной вычислительной мощности, включая 16x H100 GPU в bf16 и приблизительно 8x H100 в конфигурациях int4.
Высококачественные обучающие данные важны для разработки надежных LLM, но часто сопряжены с существенными затратами и проблемами доступности. Nemotron-4 340B решает эту проблему, позволяя генерацию синтетических данных с использованием лицензии открытой модели. Это семейство моделей включает базовые, инструктивные и наградные модели, формируя конвейер, который облегчает создание и усовершенствование синтетических данных. Эти модели без проблем интегрируются с NVIDIA NeMo, фреймворком с открытым исходным кодом, который поддерживает полный цикл обучения моделей, включая курирование данных, настройку и оценку. Они оптимизированы для вывода с использованием библиотеки NVIDIA TensorRT-LLM, улучшая их эффективность и масштабируемость.
Модель Nemotron-4 340B Instruct заслуживает особого внимания, поскольку создает синтетические данные, близкие к реальным, улучшая качество данных и повышая производительность пользовательских LLM в различных областях. Эта модель может создавать разнообразные и реалистичные выходные данные, которые затем могут быть улучшены с помощью модели Nemotron-4 340B Reward. Модель Reward оценивает ответы на основе полезности, правильности, связности, сложности и многословности, обеспечивая соответствие сгенерированных данных высоким стандартам качества. Этот процесс оценки критичен для поддержания актуальности и точности синтетических данных, делая их подходящими для различных приложений.
Источник изображения
Одним из ключевых преимуществ Nemotron-4 340B является его возможности настройки. Исследователи и разработчики могут настраивать базовую модель, используя собственные данные, включая набор данных HelpSteer2, что позволяет создавать индивидуальные инструктивные или наградные модели. Этот процесс настройки облегчается фреймворком NeMo, который поддерживает различные методы тонкой настройки, включая надзорную тонкую настройку и эффективные методы, такие как LoRA. Эти методы позволяют разработчикам адаптировать модели под конкретные случаи использования, улучшая их точность и эффективность в последующих задачах.
Модели оптимизированы с использованием TensorRT-LLM для использования тензорной параллелизации, формы параллелизма модели, которая распределяет отдельные матрицы весов по нескольким GPU и серверам. Эта оптимизация позволяет эффективное вывод на масштабе, обеспечивая возможность более эффективной обработки больших наборов данных и сложных вычислений.
Релиз Nemotron-4 340B также подчеркивает важность безопасности и оценки модели. Модель Instruct прошла строгие проверки безопасности, включая адверсные тесты, чтобы обеспечить надежность при различных показателях риска. Несмотря на эти меры предосторожности, NVIDIA рекомендует пользователям тщательно оценивать выходные данные модели, чтобы убедиться, что сгенерированные синтетические данные безопасны, точны и подходят для их конкретных случаев использования.
Разработчики могут получить доступ к моделям Nemotron-4 340B на платформах, таких как Hugging Face, и вскоре они будут доступны в качестве микросервиса NVIDIA NIM с стандартным API. Эта доступность, в сочетании с мощными возможностями моделей, позиционирует Nemotron-4 340B как ценный инструмент для организаций, стремящихся использовать силу синтетических данных в их процессах разработки искусственного интеллекта.
В заключение, Nemotron-4 340B от NVIDIA представляет собой существенный шаг в области генерации синтетических данных для обучения LLM. Его открытая лицензия, передовые модели инструкций и наград, а также безупречная интеграция с фреймворками NeMo и TensorRT-LLM от NVIDIA предоставляют разработчикам мощные инструменты для создания высококачественных обучающих данных. Это новшество предназначено для стимулирования прогресса в области искусственного интеллекта во многих отраслях, от здравоохранения до финансов и за ее пределами, обеспечивая разработку более точных и эффективных языковых моделей.
Проверьте технический отчет, блог и модели. Весь заслуги за этот проект принадлежат исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Телеграм-каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 44+ тыс. ML SubReddit
«`




















