
«`html
Listening-While-Speaking Language Model (LSLM): An End-to-End System Equipped with both Listening and Speaking Channels
В области взаимодействия человека с компьютером (HCI) диалог выделяется как наиболее естественная форма общения. Возникновение моделей речевого языка (SLM) значительно улучшило речевые разговорные ИИ, однако эти модели остаются ограниченными в своей способности вести разговор в реальном времени, что ограничивает их применимость в ситуациях, требующих мгновенной обратной связи и динамического разговорного потока. Невозможность обрабатывать прерывания и поддерживать бесперебойное взаимодействие побудила исследователей исследовать полнодуплексное моделирование (FDM) в интерактивных моделях речевого языка (iSLM). Для решения этой проблемы исследование представляет модель речевого языка «Listening-while-Speaking Language Model (LSLM)», интегрирующую возможности прослушивания и речи в одной системе для обеспечения взаимодействия в реальном времени без прерываний.
Применение в реальном мире
Текущие методы в моделях речевого языка обычно включают системы с поочередным обменом, где прослушивание и речь происходят в изолированных фазах. Эти системы часто используют отдельные модули автоматического распознавания речи (ASR) и текстового воспроизведения речи (TTS), что приводит к проблемам задержки и неспособности эффективно обрабатывать прерывания в реальном времени. Несмотря на значительные достижения в области разговорного ИИ, такие как SpeechGPT и LauraGPT, они остаются ограниченными по сравнению с моделями, неспособными обеспечить плавное взаимодействие, необходимое для более естественного диалога между человеком и компьютером.
Практические решения
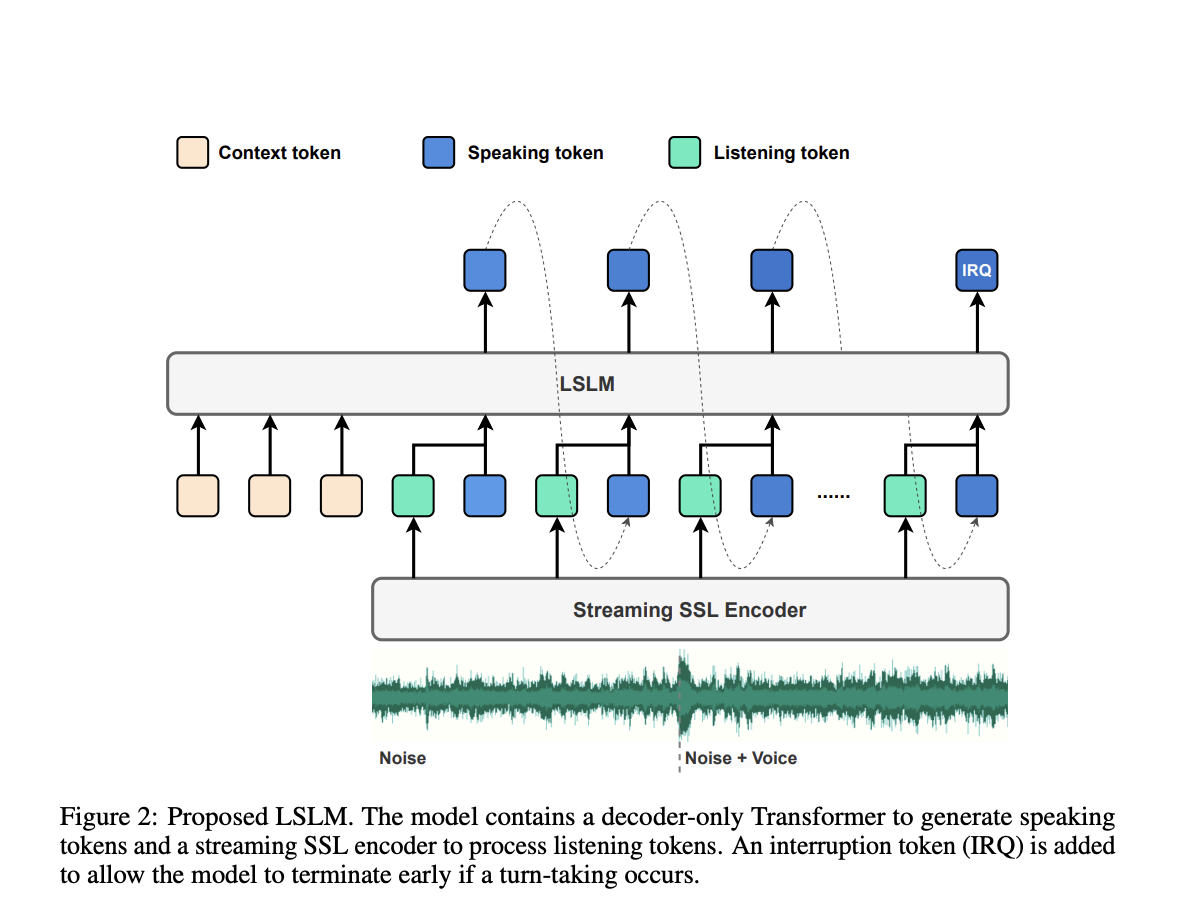
Для преодоления этих ограничений команда исследователей из Университета Шанхайского Цзяотун и ByeDance предлагает LSLM, систему, способную одновременно выполнять прослушивание и речь. Эта модель использует декодерную систему TTS на основе токенов для генерации речи и потоковый самообучающийся кодировщик для обработки аудиовхода в реальном времени. Уникальность LSLM заключается в способности объединять эти каналы, обеспечивая обнаружение обмена ходами в реальном времени и динамический ответ. Путем изучения трех стратегий слияния — раннего, среднего и позднего — исследователи выявили среднее слияние как оптимальный баланс между генерацией речи и возможностями взаимодействия в реальном времени.
Архитектура LSLM основана на ее двухканальном дизайне. Для речи модель использует авторегрессивную систему TTS на основе токенов. В отличие от предыдущих моделей, LSLM упрощает процесс, используя дискретные аудиотокены, повышая взаимодействие в реальном времени и устраняя необходимость в обширной обработке перед синтезом речи. Канал речи генерирует речевые токены на основе заданного контекста с помощью вокодера, который преобразует эти токены в слышимую речь. Такая настройка позволяет модели сосредотачиваться на семантической информации, улучшая ясность и актуальность ее ответов.
В отношении прослушивания модель использует потоковый самообучающийся кодировщик для непрерывной обработки входящих аудиосигналов. Этот кодировщик преобразует аудиовход в непрерывные вложения, которые затем проецируются в пространство, где их можно обрабатывать наряду с речевыми токенами. Эти каналы объединяются одним из трех методов слияния, и среднее слияние оказывается наиболее эффективным. В этом методе прослушивающие и говорящие каналы объединяются на каждом блоке трансформатора, что позволяет модели использовать информацию обоих каналов на протяжении процесса генерации речи. Эта стратегия слияния обеспечивает способность LSLM плавно обрабатывать прерывания и поддерживать последовательный и отзывчивый диалоговый поток.
Значение для бизнеса
Оценка производительности LSLM была проведена в двух экспериментальных сценариях: командном FDM и голосовом FDM. В командном сценарии модель была протестирована на способность реагировать на конкретные команды в условиях фонового шума. В отличие от этого, голосовой сценарий оценивал ее чувствительность к прерываниям от различных дикторов. Результаты продемонстрировали устойчивость LSLM к шумным средам и способность распознавать и адаптироваться к новым голосам и инструкциям. Особенно среднее слияние сбалансировало требования к взаимодействию в реальном времени и генерации речи, обеспечивая плавный пользовательский опыт.
Listening-While-Speaking Language Model (LSLM) представляет собой значительный прорыв в области интерактивных моделей речевого языка. Решая ограничения поочередных систем и вводя надежные возможности взаимодействия в реальном времени, LSLM открывает путь к более естественному и плавному диалогу между человеком и компьютером. Исследование подчеркивает важность интеграции полнодуплексных возможностей в SLM, демонстрируя, как такие достижения могут улучшить применимость разговорного ИИ в реальных сценариях. Своим инновационным дизайном и впечатляющей производительностью LSLM устанавливает новый стандарт для будущих разработок в области речевого HCI.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу из 47 тысяч человек.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI выпустила DistillKit: открытый инструмент для моделирования моделей для создания эффективных малых языковых моделей высокой производительности.
Статья была опубликована на MarkTechPost.
Применение в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Listening-While-Speaking Language Model (LSLM): An End-to-End System Equipped with both Listening and Speaking Channels.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru — будущее уже здесь!
«`





















