
Оптическое распознавание символов (OCR)
Оптическое распознавание символов (OCR) — это мощная технология, которая преобразует изображения текста в машинно-читаемый контент. С ростом потребности в автоматизации извлечения данных, инструменты OCR стали неотъемлемой частью многих приложений, от цифровки документов до извлечения информации из сканированных изображений.
Создание приложения OCR в Google Colab
В этом руководстве мы создадим приложение OCR, которое будет работать без проблем в Google Colab, используя такие инструменты, как OpenCV для обработки изображений, Tesseract-OCR для распознавания текста, NumPy для манипуляций с массивами и Matplotlib для визуализации. В конце этого руководства вы сможете загрузить изображение, предварительно обработать его, извлечь текст и скачать результаты, все это в рамках ноутбука Colab.
Настройка окружения OCR
Для настройки окружения OCR в Google Colab сначала необходимо установить Tesseract-OCR, используя apt-get. Также мы установим необходимые библиотеки Python, такие как pytesseract (для взаимодействия с Tesseract), OpenCV (для обработки изображений), NumPy (для числовых операций) и Matplotlib (для визуализации).
Импорт необходимых библиотек
Далее мы импортируем необходимые библиотеки для обработки изображений и задач OCR. OpenCV (cv2) используется для чтения и предварительной обработки изображений, в то время как pytesseract предоставляет интерфейс к движку Tesseract для извлечения текста. NumPy (np) помогает с манипуляциями с массивами, а Matplotlib (plt) визуализирует обработанные изображения.
Загрузка изображения для обработки
Чтобы обработать изображение для OCR, сначала необходимо загрузить его в Google Colab. Функция files.upload() из модуля файлов Google Colab позволяет пользователям выбрать и загрузить файл изображения из своей локальной системы.
Предварительная обработка изображения
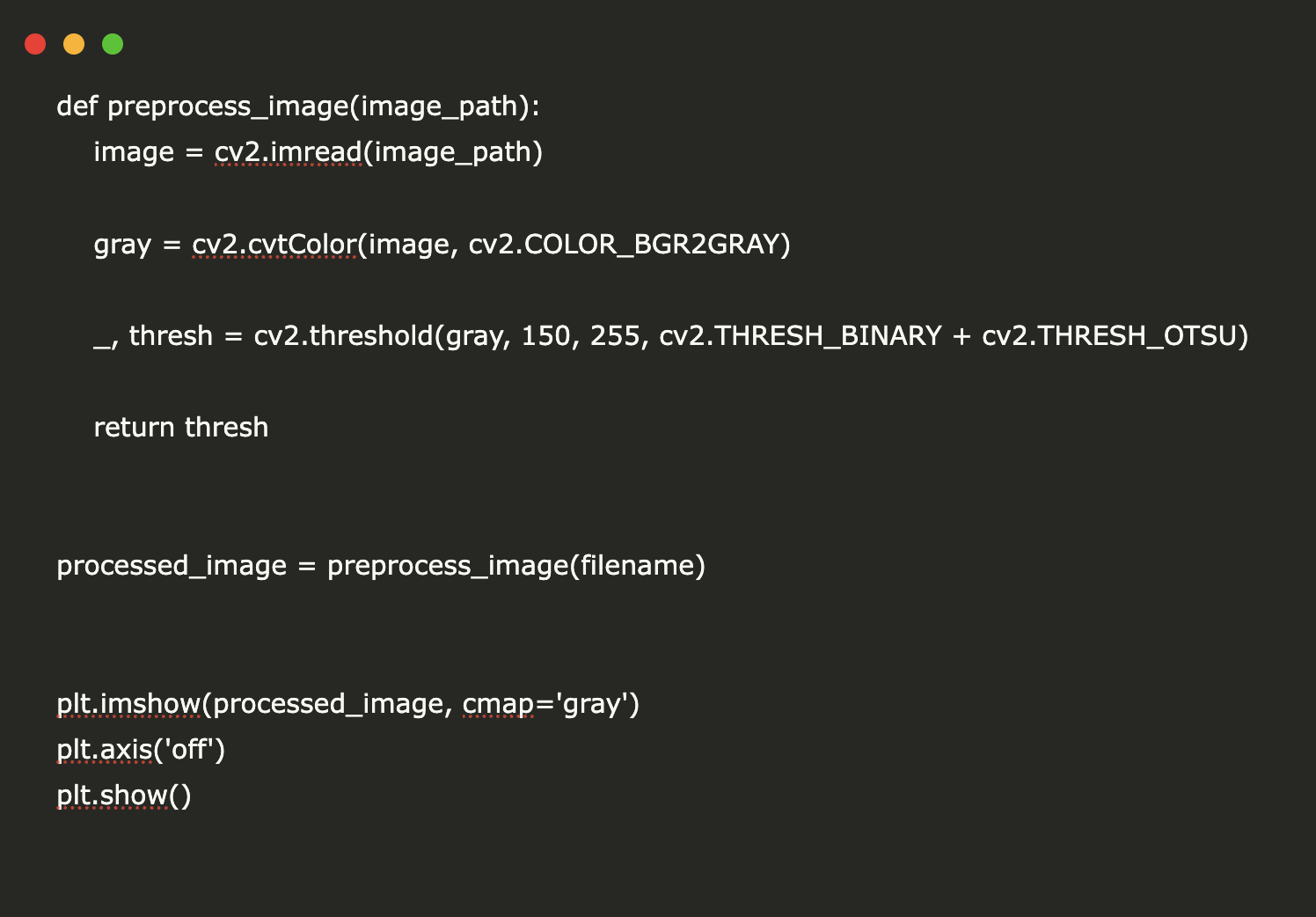
Для улучшения точности OCR мы применяем функцию предварительной обработки, которая улучшает качество изображения для извлечения текста. Функция preprocess_image() считывает загруженное изображение с помощью OpenCV и конвертирует его в оттенки серого, что более эффективно для OCR. Затем мы применяем бинарное пороговое значение с помощью метода Оцу, что помогает отличить текст от фона.
Извлечение текста
Функция extract_text() выполняет OCR на предварительно обработанном изображении. Поскольку Tesseract-OCR требует формат изображения PIL, мы сначала конвертируем массив NumPy в изображение PIL, а затем передаем это изображение в pytesseract для извлечения текста.
Сохранение и скачивание результатов
Чтобы обеспечить легкий доступ к извлеченному тексту, мы сохраняем его в текстовом файле с помощью встроенного управления файлами Python. После сохранения файла мы используем files.download() для предоставления автоматической ссылки на скачивание.
Заключение
Интегрируя OpenCV, Tesseract-OCR, NumPy и Matplotlib, мы успешно создали приложение OCR, которое может обрабатывать изображения и извлекать текст в Google Colab. Этот рабочий процесс предоставляет простой и эффективный способ преобразования сканированных документов, печатного текста или рукописного контента в цифровой текстовый формат.
Как искусственный интеллект может трансформировать ваш бизнес
Изучите, как технологии искусственного интеллекта могут изменить ваш подход к работе. Найдите процессы, которые можно автоматизировать, и определите моменты взаимодействия с клиентами, где искусственный интеллект может добавить наибольшую ценность. Выберите инструменты, которые соответствуют вашим потребностям и позволяют настраивать их в соответствии с вашими целями.
Контактная информация
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Практический пример решения на базе ИИ
Посмотрите на пример решения на базе ИИ: бот для продаж, разработанный для автоматизации взаимодействия с клиентами круглосуточно и управления взаимодействиями на всех этапах клиентского пути.




















