
Практическое применение Scaling Laws and Model Comparison в машинном обучении
Переход к центрированной на масштабирование парадигме
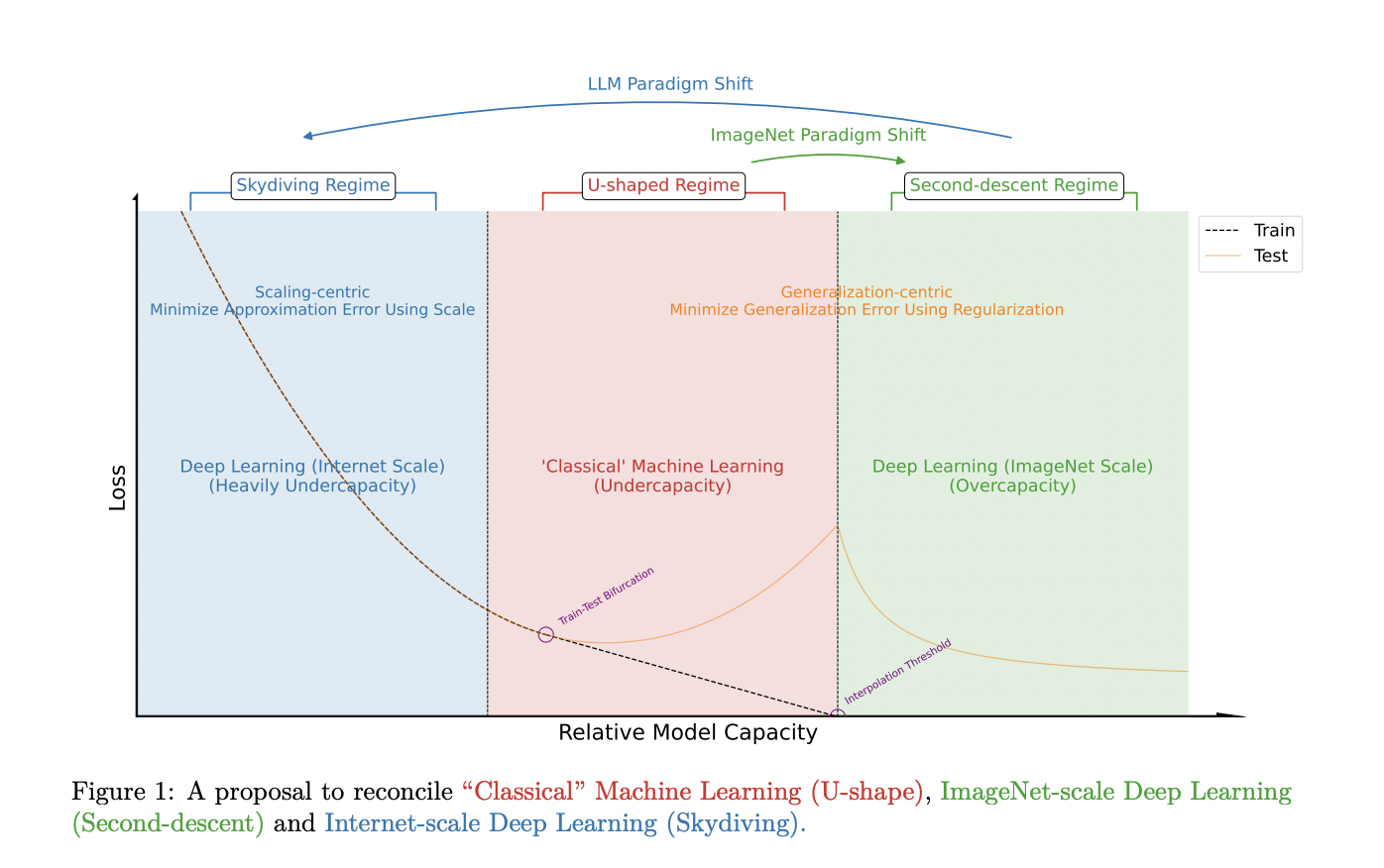
Переход от общей парадигмы к масштабирующей в машинном обучении требует пересмотра традиционных подходов. Это вызывает необходимость разработки новых принципов и методологий для оптимизации производительности моделей на невиданных масштабах, где проведение множества экспериментов часто невозможно.
Архитектурные особенности модели
Метод предлагает использовать архитектуру декодера на основе трансформера, обученную на наборе данных C4 с использованием кодовой базы NanoDO. Ключевые архитектурные особенности включают в себя вращающееся позиционное вложение, QK-Norm для вычисления внимания, а также независимые веса для голов и вложений. Модель использует активацию Gelu с F = 4D, где D — размер модели, а F — скрытое измерение MLP. Головы внимания настроены с размерностью 64, а длина последовательности установлена на 512.
Оптимизация и регуляризация
Для оптимизации метод использует AdamW с параметрами β1 = 0,9, β2 = 0,95, ϵ = 1e-20 и связанным весовым уменьшением λ = 0,1. Этот набор архитектурных решений и стратегий оптимизации направлен на улучшение производительности модели в масштабирующей парадигме.
Регуляризация в масштабирующей парадигме
Традиционные методы регуляризации пересматриваются на эффективность в масштабирующей парадигме. В контексте больших языковых моделей и масштабирующей парадигмы вопрос необходимости этих методов регуляризации ставится под сомнение. Переход к масштабированию требует исследования альтернативных подходов, более подходящих для данной парадигмы.


















