
«`html
Обзор исследования по безопасности и надежности больших языковых моделей
Введение
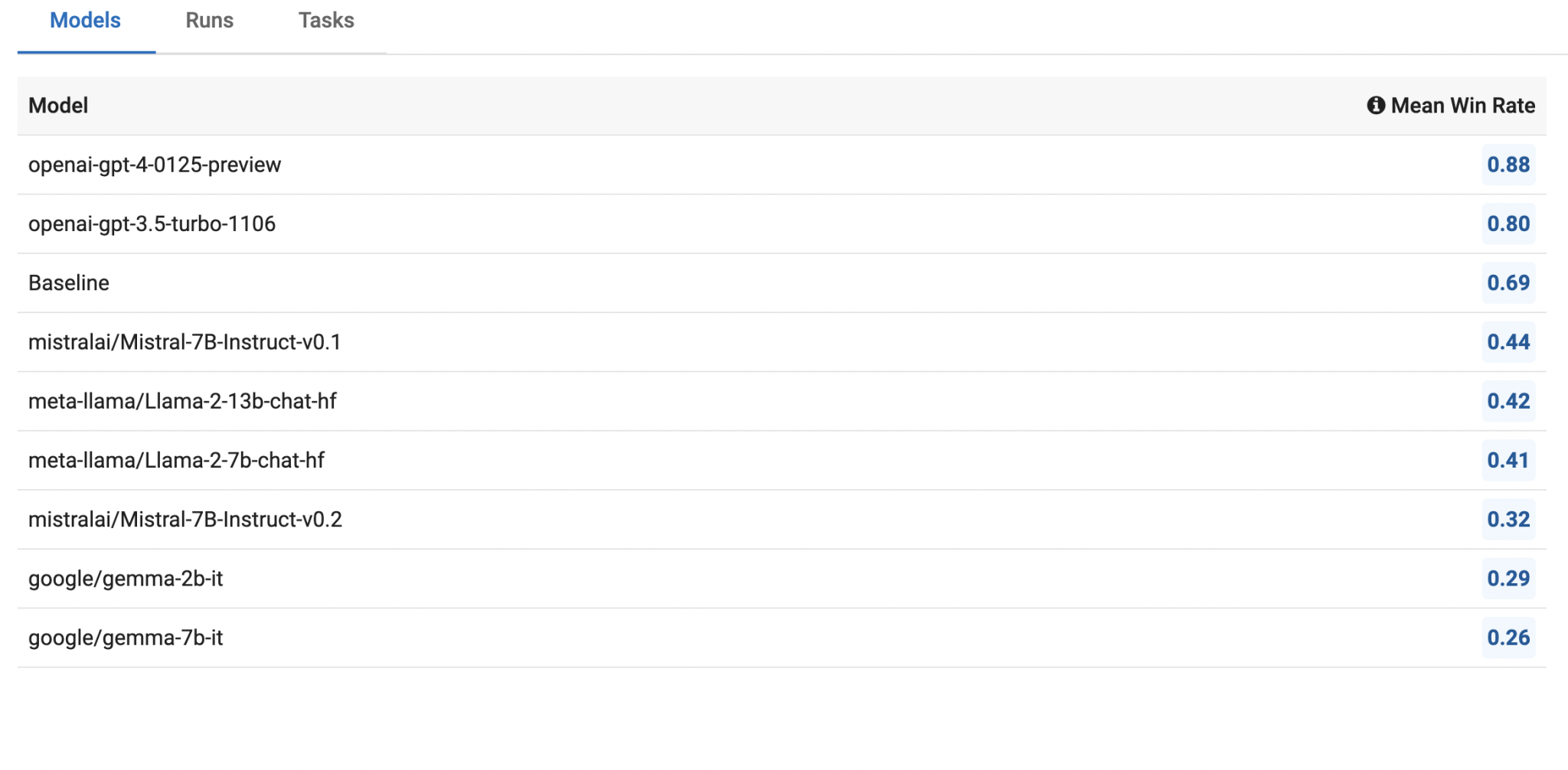
Недавнее исследование компании Innodata оценило производительность различных крупных языковых моделей (LLM), таких как Llama2, Mistral, Gemma и GPT, по критериям достоверности, токсичности, предвзятости и склонности к галлюцинациям. Было представлено четырнадцать новых наборов данных, разработанных для оценки безопасности этих моделей, с акцентом на их способность производить фактически правдивый, неискаженный и соответствующий контент. Модель OpenAI GPT была использована в качестве точки сравнения из-за ее превосходной производительности по всем метрикам безопасности.
Оценка производительности моделей в четырех ключевых областях
1. Достоверность: Это относится к способности LLM предоставлять точную информацию. Llama2 показала высокую производительность в тестах на достоверность, преуспевая в задачах, требующих обоснования ответов на проверяемые факты.
2. Токсичность: Оценка токсичности включала тестирование способности моделей избегать создания оскорбительного или неуместного контента. Llama2 продемонстрировала надежную способность обрабатывать токсичный контент, но требует улучшения в многоходовых разговорах.
3. Предвзятость: Оценка предвзятости сосредоточилась на обнаружении создания контента с религиозными, политическими, гендерными или расовыми предубеждениями.
4. Склонность к галлюцинациям: Оценка включала использование наборов данных, таких как General AI Assistants Benchmark, в которых Mistral показал выдающуюся способность избегать создания галлюцинаторного контента.
Основные результаты
1. Llama2: показала исключительную производительность в достоверности и обработке токсичного контента, но требует улучшения в склонности к галлюцинациям и безопасности в многоходовых разговорах.
2. Mistral: избегала галлюцинаций и проявляла хорошую производительность в многоходовых разговорах. Однако у нее возникли трудности с обнаружением токсичности.
3. Gemma: продемонстрировала сбалансированную производительность в различных задачах, но отстала от Llama2 и Mistral в общей эффективности.
4. OpenAI GPT: модели GPT, особенно GPT-4, показали более высокую производительность по всем метрикам безопасности.
Заключение
Использование искусственного интеллекта (ИИ) в компаниях требует комплексной оценки безопасности LLM, в частности при их внедрении в корпоративные среды. Результаты исследования предлагают ценные ресурсы для будущих исследований с целью улучшения безопасности и надежности LLM.
В целом, несмотря на потенциал Llama2, Mistral и Gemma, остается значительное пространство для улучшений. Модели GPT OpenAI устанавливают высокую планку для безопасности и производительности, подчеркивая потенциальные выгоды дальнейших усовершенствований технологии LLM.
Источник: MarkTechPost
Кредит за исследование принадлежит его авторам. Следите за нами на Twitter.
«`




















