
«`html
Обработка речи с помощью искусственного интеллекта (ИИ)
Обработка речи направлена на разработку систем анализа, интерпретации и генерации человеческой речи. Эти технологии включают в себя такие приложения, как автоматическое распознавание речи, верификация диктора, перевод речи в текст и диаризация диктора. С увеличением зависимости от виртуальных ассистентов, транскрипционных сервисов и многоязычных коммуникационных инструментов эффективная и точная обработка речи стала неотъемлемой. Исследователи все чаще обращаются к методам машинного обучения и техникам самообучения для решения сложностей человеческой речи с целью улучшить производительность системы на разных языках и в различных средах.
Основные проблемы и решения
Одной из основных проблем в этой области является вычислительная неэффективность существующих моделей самообучения. Многие из этих моделей, хотя и эффективны, требовательны к ресурсам из-за использования методов, таких как кластеризация речи и ограниченная подвыборка. Это часто приводит к более быстрой обработке и более высоким вычислительным затратам. Кроме того, эти модели часто испытывают трудности в различении дикторов в многодикторной среде или в выделении основного диктора из фонового шума, что часто встречается в реальных приложениях. Решение этих проблем крайне важно для создания более быстрых и масштабируемых систем, которые могут быть развернуты в различных практических сценариях.
Несколько моделей в настоящее время доминируют в области самообучения речи. Например, Wav2vec-2.0 использует контрастное обучение, в то время как HuBERT полагается на прогностический подход с использованием кластеризации по методу k-средних для генерации целевых токенов. Несмотря на их успех, эти модели имеют существенные ограничения, включая высокие вычислительные требования и более медленные времена вывода из-за их архитектуры. Их производительность в задачах, специфичных для дикторов, таких как диаризация диктора, затруднена из-за их ограниченной способности явно разделять одного диктора от другого, особенно в шумных средах или при наличии нескольких дикторов.
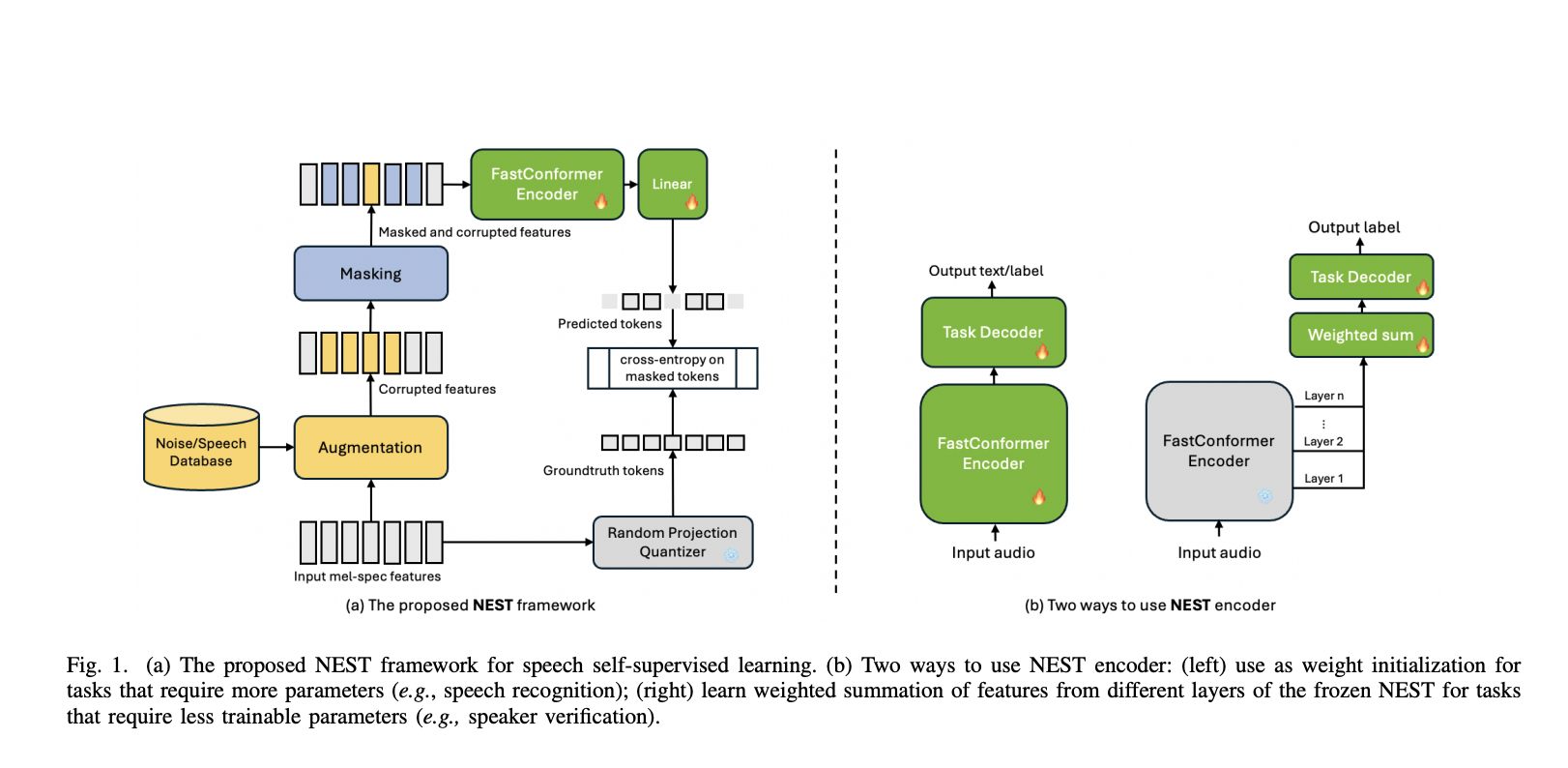
Исследователи из NVIDIA представили новое решение — кодировщик NeMo для задач речи (NEST), которое решает эти проблемы. NEST построен на архитектуре FastConformer, предлагая эффективную и упрощенную структуру для самообучения в области обработки речи. В отличие от предыдущих моделей, NEST имеет скорость подвыборки 8x, что делает его более быстрым, чем архитектуры, такие как Transformer и Conformer, которые обычно используют длины кадров 20 мс или 40 мс. Это сокращение длины последовательности значительно снижает вычислительную сложность модели, улучшая ее способность обрабатывать большие наборы речи при сохранении высокой точности.
Методология NEST включает несколько инновационных подходов для оптимизации и улучшения обработки речи. Одной из ключевых особенностей является его метод квантования на основе случайной проекции, который заменяет вычислительно затратные методы кластеризации, используемые моделями, такими как HuBERT. Этот более простой метод значительно сокращает время и ресурсы, необходимые для обучения, при этом достигая современной производительности. NEST включает обобщенную технику аугментации шумной речи. Эта аугментация улучшает способность модели отделять основного диктора от фонового шума или других дикторов путем случайного вставления речевых сегментов из нескольких дикторов во входные данные. Этот подход обеспечивает модель надежным обучением в разнообразных реальных звуковых средах, улучшая производительность в задачах идентификации и разделения дикторов.
Архитектура модели NEST разработана для максимизации эффективности и масштабируемости. Она применяет сверточную подвыборку к входным признакам Мел-спектрограмм перед их обработкой слоями FastConformer. Этот шаг сокращает длину входной последовательности, что приводит к более быстрым временам обучения без потери точности. Кроме того, метод квантования на основе случайной проекции использует фиксированный кодовый словарь с 8192 словарными единицами и 16-мерными признаками, дополнительно упрощая процесс обучения и обеспечивая захват основных характеристик входной речи. Исследователи также внедрили механизм маскирования по блокам, случайно выбирая входные сегменты для маскирования во время обучения, что стимулирует модель к изучению устойчивых представлений речевых характеристик.
Результаты испытаний, проведенных исследовательской группой NVIDIA, впечатляют. В различных задачах обработки речи NEST последовательно превосходит существующие модели, такие как WavLM и XEUS. Например, в задачах диаризации диктора и автоматического распознавания речи NEST достиг современных результатов, превзойдя WavLM-large, который имеет в три раза больше параметров, чем NEST. В задаче диаризации диктора NEST достиг ошибки диаризации (DER) 2,28% по сравнению с 3,47% у WavLM, что является значительным улучшением точности. Кроме того, в задачах распознавания фонем NEST сообщил о частоте ошибок фонем (PER) 1,89%, демонстрируя его способность решать разнообразные задачи обработки речи.
Более того, производительность NEST в задачах многоязычного распознавания речи впечатляет. Модель была оценена на наборах данных по четырем языкам: английскому, немецкому, французскому и испанскому. Несмотря на то, что она была в основном обучена на английских данных, NEST достигла снижения частоты ошибок слов (WER) на всех четырех языках. Например, на немецком языке в тесте распознавания речи NEST зафиксировала WER 7,58%, превзойдя несколько более крупных моделей, таких как Whisper-large и SeamlessM4T. Эти результаты подчеркивают способность модели обобщаться на разные языки, что делает ее ценным инструментом для задач многоязычного распознавания речи.
В заключение, архитектура NEST представляет собой значительный прорыв в области обработки речи. Благодаря упрощенной архитектуре и инновационным техникам, таким как квантование на основе случайной проекции и обобщенная аугментация шумной речи, исследователи из NVIDIA создали модель, которая не только более быстрая и эффективная, но также высокоточная в различных задачах обработки речи. Производительность NEST в задачах, таких как автоматическое распознавание речи, диаризация диктора и распознавание фонем, подчеркивает ее потенциал как масштабируемого решения для реальных задач обработки речи.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Кроме того, не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему 50-тысячному ML SubReddit.
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИИ: «SAM 2 для видео: как настроить под ваши данные» (ср, 25 сентября, 4:00 — 4:45 EST)
Этот пост описывает исследование NVIDIA по созданию NEST: быстрой и эффективной самообучающей модели для обработки речи, представленное на MarkTechPost.
«`





















