
«`html
CS-Bench: Оценка производительности LLM в области информатики
Область искусственного интеллекта значительно изменилась с появлением больших языковых моделей (LLM), показавших огромный потенциал в различных областях. Тем не менее, задача эффективного использования знаний компьютерных наук и более эффективного обслуживания человечества остается ключевой проблемой для LLM. Существующие исследования охватывают множество областей, включая информатику, однако недостаточно всесторонней оценки, сосредоточенной именно на производительности LLM в информатике. Этот пробел не учитывает важность тщательной оценки области и руководства развитием LLM для улучшения их возможностей в информатике.
Практические решения и ценность
Недавние исследования изучали потенциал LLM в различных отраслях и научных областях. Однако изучение LLM в информатике можно разделить на две основные категории: широкие оценочные бенчмарки, где информатика составляет лишь небольшую долю, и изучение конкретных приложений LLM в информатике. Ни один из подходов не обеспечивает всестороннюю оценку фундаментальных знаний и способностей рассуждения LLM в этой области. Хотя отдельные способности, такие как математика, программирование и логическое мышление, хорошо изучены, исследования их интегрированного применения и взаимосвязей остаются редкими.
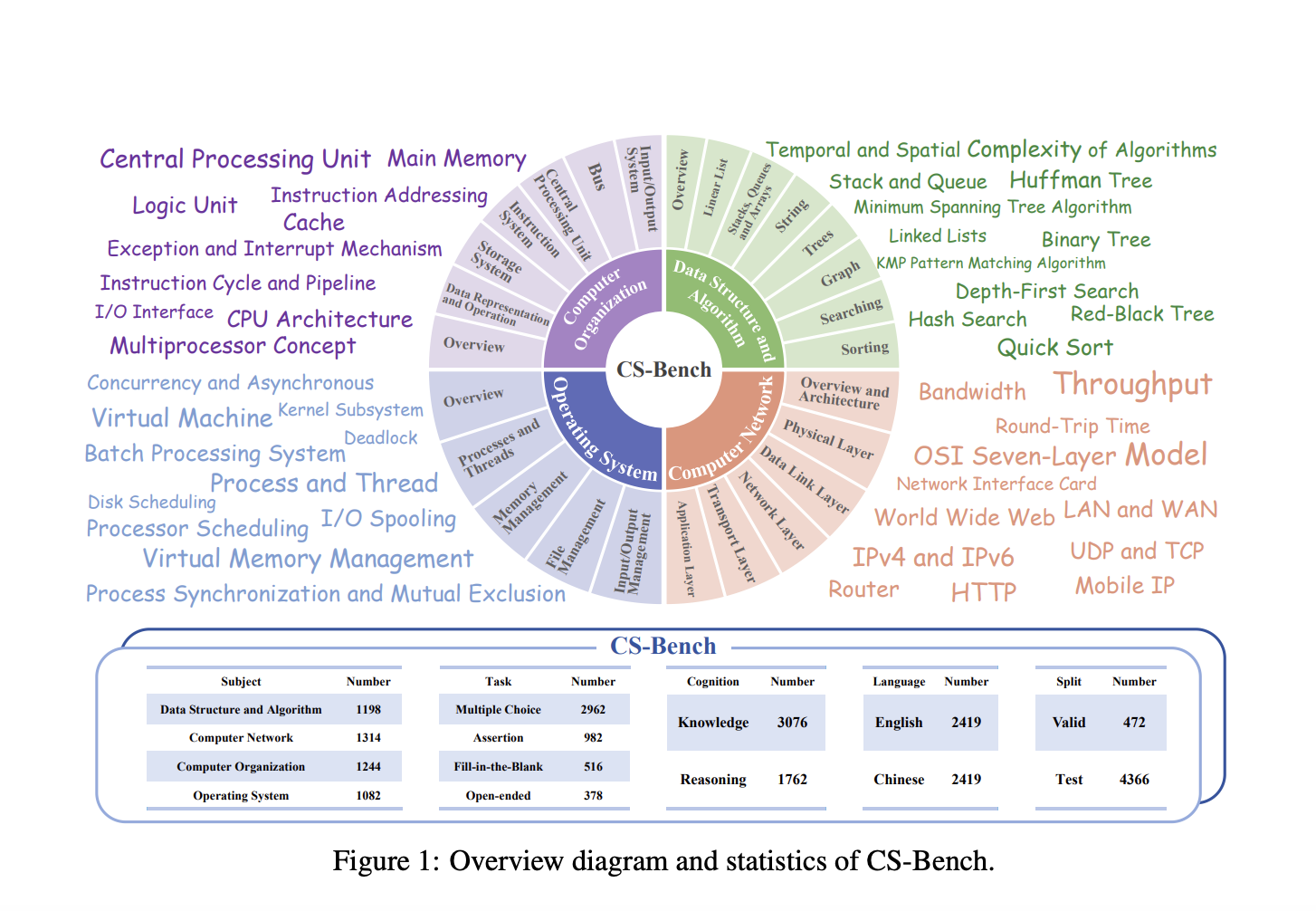
Исследователи из Пекинского университета почты и телекоммуникаций предлагают CS-Bench, первый бенчмарк, посвященный оценке производительности LLM в информатике. CS-Bench включает высококачественные разнообразные формы задач, различные емкости и двуязычную оценку. Он включает около 5 000 тщательно отобранных тестов, охватывающих 26 разделов в 4 ключевых областях информатики. Бенчмарк включает в себя вопросы с выбором ответа, утверждения, заполнение пропусков и открытые вопросы для лучшего имитации реальных сценариев и оценки устойчивости LLM к различным форматам задач. CS-Bench оценивает как вопросы типа знания, так и типа рассуждения, поддерживая двуязычную оценку на китайском и английском языках.
CS-Bench охватывает четыре ключевых области: Структуры данных и алгоритмы (DSA), Организация компьютеров (CO), Компьютерные сети (CN) и Операционные системы (OS). Он включает 26 подробных подобластей и разнообразные формы задач для обогащения измерений оценки и имитации реальных сценариев. Данные для CS-Bench берутся из различных источников, включая общедоступные онлайн-каналы, адаптированные блог-статьи и авторизованные учебные материалы. Обработка данных включает команду выпускников информатики, которые анализируют вопросы и ответы, помечают типы вопросов и обеспечивают качество через тщательные ручные проверки. Бенчмарк поддерживает двуязычную оценку с общим числом 4 838 примеров различных форматов задач.
Результаты оценки показывают, что общие баллы моделей варьируются от 39,86% до 72,29%. GPT-4 и GPT-4o представляют самый высокий стандарт на CS-Bench, будучи единственными моделями, превысившими профессиональный уровень более 70%. Открытые модели, такие как Qwen1.5-110B и Llama3-70B, превзошли ранее сильные закрытые модели. Новые модели демонстрируют значительные улучшения по сравнению с предыдущими версиями. Все модели показывают худшие результаты в рассуждениях по сравнению с знаниями, что указывает на большие трудности в рассуждениях. LLM в целом лучше всего проявляют себя в области структур данных и алгоритмов и хуже всего в операционных системах. Сильные модели демонстрируют лучшую способность использовать знания для рассуждений и проявляют большую устойчивость к разным форматам задач.
Это исследование представляет CS-Bench для предоставления ценных идей о производительности LLM в информатике. Даже лучшие модели, такие как GPT-4o, имеют значительные возможности для улучшения. Бенчмарк подчеркивает тесные взаимосвязи между информатикой, математикой и навыками программирования в LLM. Эти результаты предлагают направления для улучшения LLM в этой области и предоставляют ценные идеи о их кросс-способностях и применениях, открывая путь для будущих достижений в области ИИ и информатики.
Проверьте статью и репозиторий на GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу из более чем 45 тысяч подписчиков на Reddit.
Источник: MarkTechPost
Применение ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте CS-Bench: A Bilingual (Chinese-English) Benchmark Dedicated to Evaluating the Performance of LLMs in Computer Science.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь, какие ключевые показатели эффективности (KPI) вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















