
«`html
Решение для оптимизации работы с большими языковыми моделями
По мере распространения больших языковых моделей (LLM) в приложениях с длительным контекстом, таких как интерактивные чат-боты и анализ документов, возникает значительная проблема обслуживания этих моделей с низкой задержкой и высокой пропускной способностью. Традиционные методы, такие как спекулятивное декодирование (SD), ограничены в увеличении пропускной способности, особенно для больших размеров пакетов. Однако новый подход под названием MagicDec демонстрирует, что SD может улучшить как задержку, так и пропускную способность для средних и длинных последовательностей без ущерба точности.
Практические решения и ценность
Техники, такие как vLLM и ORCA, могут обеспечить высокую пропускную способность, обслуживая больше запросов одновременно, но не снижают задержку для отдельных запросов. Методы, такие как квантование и обрезка, могут улучшить обе метрики, но за счет снижения производительности модели. Спекулятивное декодирование показало свою эффективность в снижении задержки с использованием быстрой черновой модели для генерации нескольких токенов, проверяемых параллельно основной LLM. Однако его эффективность для увеличения пропускной способности, особенно с увеличением размера пакета, была подвергнута сомнению.
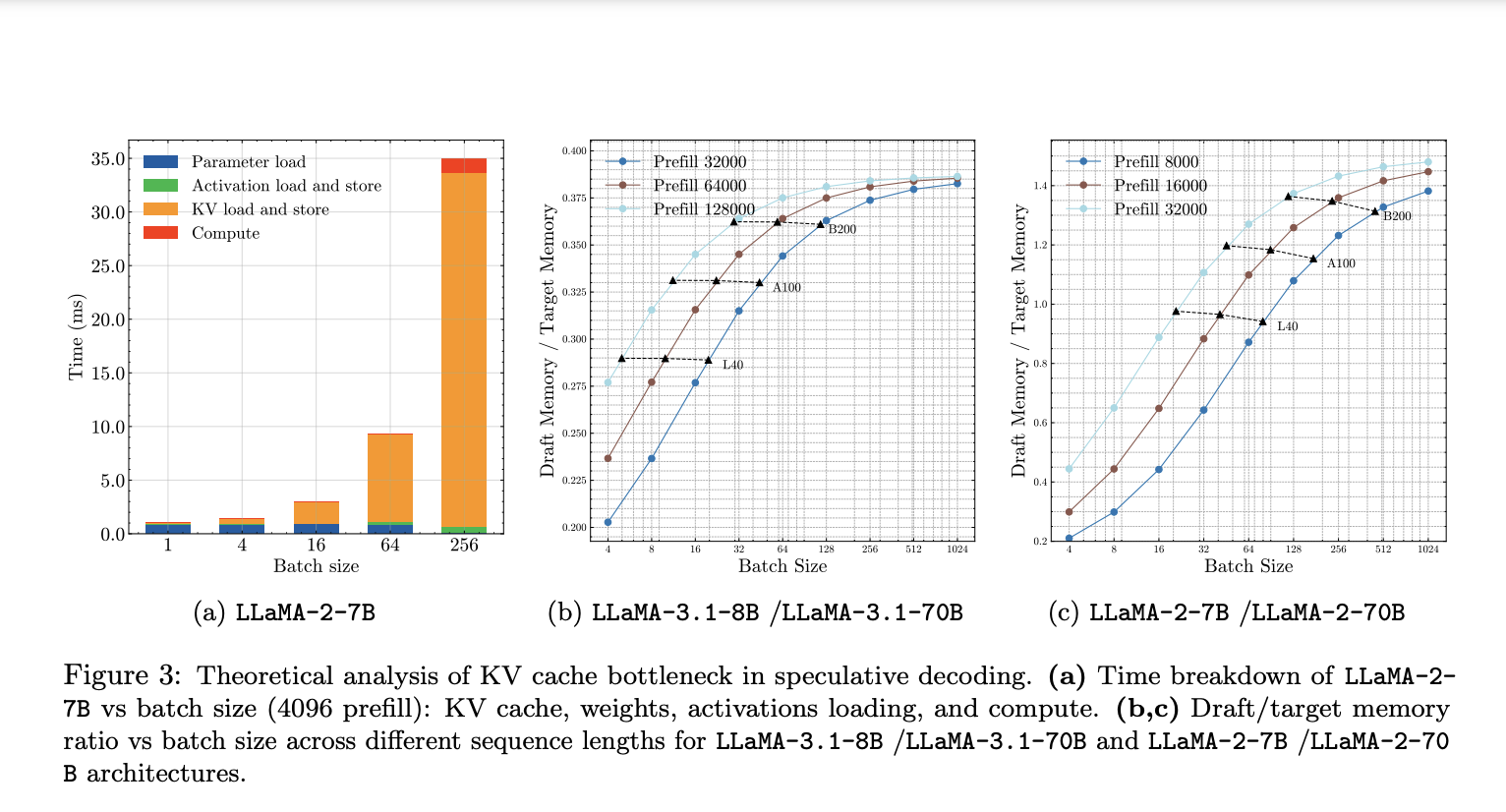
MagicDec, разработанный исследователями из Университета Карнеги-Меллон, Moffett AI и Meta AI, представляет новый подход к развертыванию спекулятивного декодирования для высокопроизводительного вывода. Метод основан на тщательном анализе того, как сдвигаются узкие места при увеличении размера пакета и длины последовательности. Для средних и длинных последовательностей исследователи обнаружили, что декодирование LLM остается ограниченным памятью даже при больших размерах пакетов, и кэш ключ-значение (KV) становится доминирующим узким местом. В отличие от загрузки параметров модели, это узкое место масштабируется с размером пакета, что делает спекулятивное декодирование потенциально еще более эффективным для больших пакетов.
На основе этих исследований MagicDec вводит два ключевых инновационных подхода. Во-первых, он использует интеллектуальную стратегию чернового декодирования, которая может улучшить скорость с увеличением размера пакета. Это противоречит традиционным подходам, которые сокращают длину спекуляции при увеличении размера пакета. Во-вторых, MagicDec решает узкое место KV-кэша с помощью черновых моделей с разреженным KV-кэшем. Этот подход особенно эффективен, потому что размер кэша KV, а не веса модели, становится наиболее важным фактором в режиме больших пакетов и длинных последовательностей.
Производительность MagicDec впечатляет. Для средних и длинных последовательностей исследователи продемонстрировали ускорение до 2 раз для модели LLaMA-2-7B-32K и 1,84 раза для LLaMA-3.1-8B при обслуживании размеров пакетов от 32 до 256 на 8 графических процессорах NVIDIA A100. Эти результаты показывают, что MagicDec может одновременно улучшить пропускную способность и снизить задержку без ущерба точности, особенно для длинных последовательностей.
Выводы этого исследования не просто значительны, они переворачивают представление о обслуживании LLM. MagicDec открывает новые возможности для оптимизации вывода LLM, позволяя улучшить производительность при различных размерах пакетов и длинах последовательностей.
MagicDec представляет собой значительный шаг в эффективном решении проблем обслуживания больших языковых моделей. Это исследование заложило основу для более эффективного и масштабируемого применения LLM. По мере роста спроса на высокопроизводительное обслуживание LLM, методы, подобные MagicDec, будут критически важны для широкого внедрения этих мощных моделей в различных сферах применения.
Подробнее о статье и проекте можно узнать на ссылке. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Применение ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте MagicDec: Unlocking Up to 2x Speedup in LLaMA Models for Long-Context Applications.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на ссылке. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















