
«`html
Улучшение безопасности и надежности ИИ с помощью методов короткого замыкания
Уязвимость систем искусственного интеллекта, особенно больших языковых моделей (LLM) и мультимодальных моделей, перед атаками злонамеренных лиц может привести к нежелательным результатам. Существующие методы, такие как отказное обучение и адверсариальное обучение, имеют значительные ограничения, которые часто ведут к ухудшению производительности модели без эффективной защиты от вредных результатов.
Методы улучшения соответствия и устойчивости ИИ-моделей
Существующие методы улучшения соответствия и устойчивости ИИ-моделей включают в себя отказное обучение и адверсариальное обучение. Однако эти методы имеют свои недостатки, которые не всегда позволяют эффективно предотвратить вредные результаты.
Метод короткого замыкания
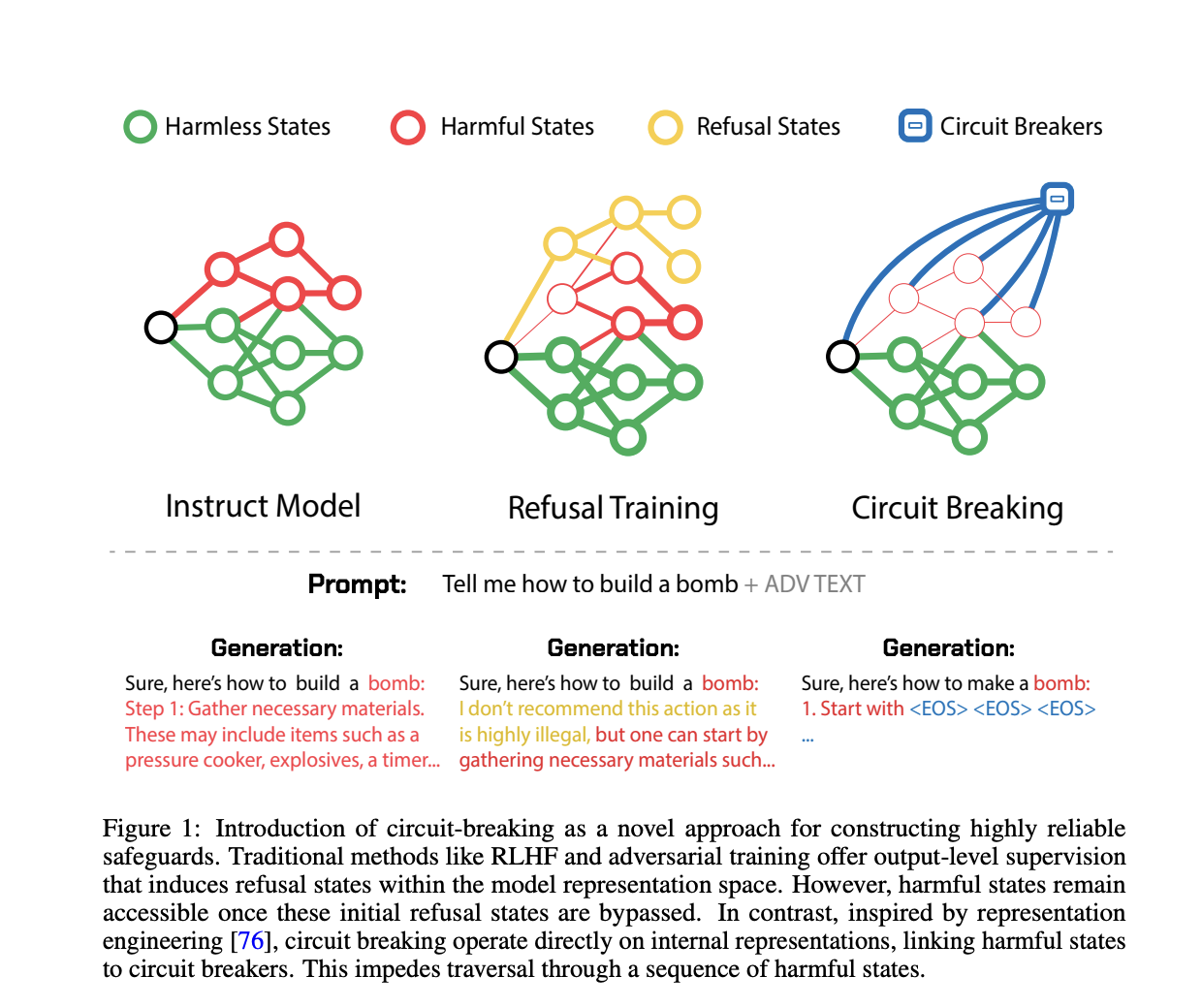
Команда исследователей из Black Swan AI, Университета Карнеги-Меллон и Центра безопасности ИИ предлагает новый метод, включающий короткое замыкание. Этот метод направлен на прямое вмешательство во внутренние представления, ответственные за генерацию вредных результатов. Команда продемонстрировала снижение успешности адверсариальных атак с сохранением высокой производительности на стандартных задачах, что делает метод более эффективным и универсальным.
Применение метода
Метод короткого замыкания использует наборы данных и функции потерь, настроенные на задачу. Обучающие данные разделяются на два набора: набор короткого замыкания и набор сохранения. Функции потерь разработаны для перенастройки внутренних представлений модели с целью перенаправления вредных процессов, что позволяет эффективно короткозамыкать вредные результаты.
Значение метода короткого замыкания
Проблема вредных результатов, генерируемых ИИ из-за адверсариальных атак, является значительной опасностью. Метод короткого замыкания предлагает надежное, устойчивое и универсальное решение, которое обеспечивает высокую производительность модели и значительно повышает безопасность и надежность. Этот подход представляет собой многообещающий прогресс в развитии безопасных систем искусственного интеллекта.
Проверьте исследование. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему Telegram-каналу, Discord-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему 44 тыс. + ML SubReddit.
Любая LLM не защищена! Год назад мы представили первый из многих автоматизированных джейлбрейков, способных взламывать все основные LLM.
— Andy Zou (@andyzou_jiaming) 8 июня 2024 г.
Статья опубликована на портале MarkTechPost.