
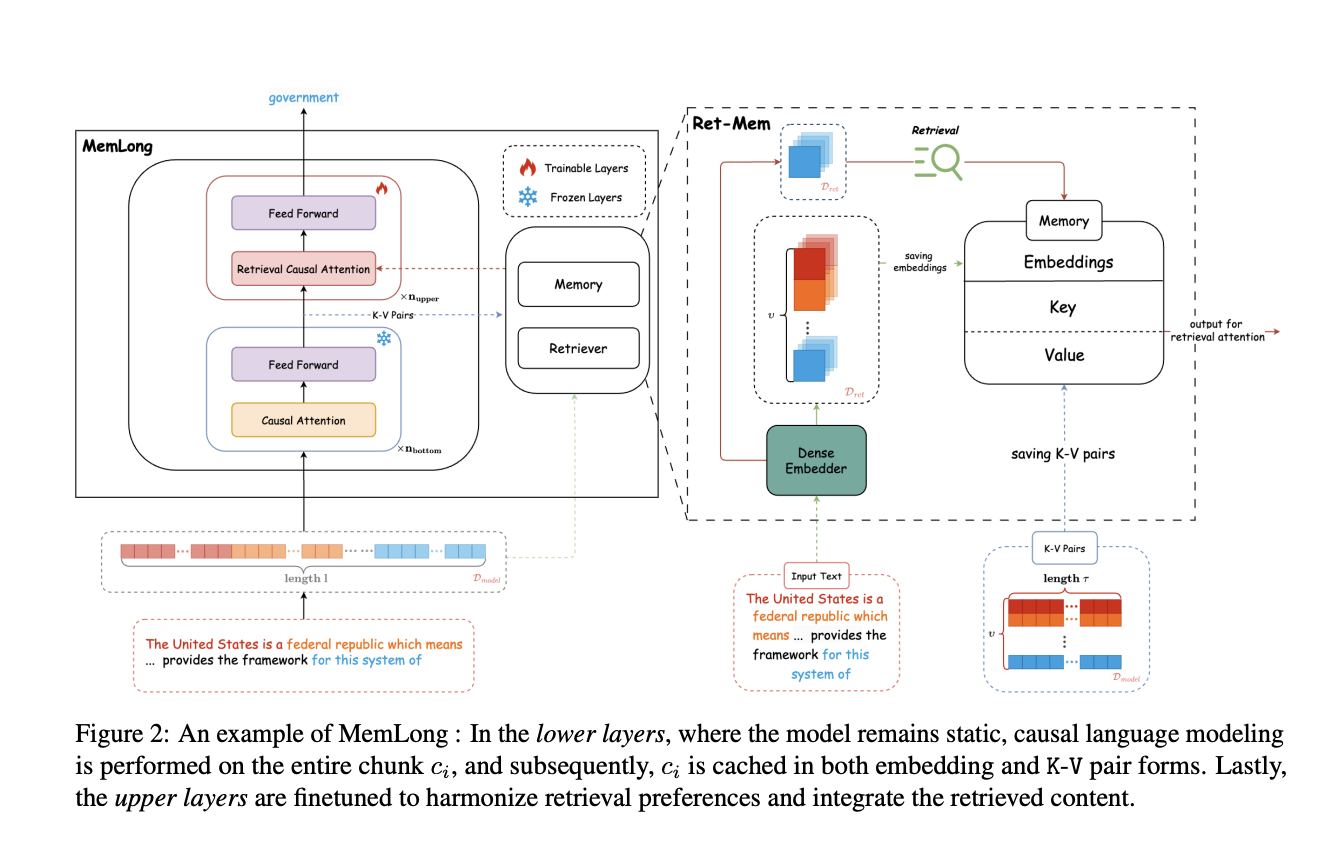
«`html
MemLong: Революционное улучшение моделирования длинных контекстов с помощью памятью-усиленного поиска
Статья «MemLong: Memory-Augmented Retrieval for Long Text Modeling» решает критическое ограничение в области моделей больших языковых моделей (LLM) — способность обрабатывать длинные контексты. Авторы предлагают новое решение, MemLong, которое интегрирует внешний механизм поиска для улучшения моделирования длинных контекстов. Это позволяет значительно расширить длину контекста, которую могут обрабатывать LLM, что повышает их применимость в задачах, таких как резюмирование длинных документов и многоходовой диалог.
Практические решения и ценность
MemLong хранит прошлые контексты в неподдающейся обучению памяти, что позволяет эффективно извлекать ключевые пары (K-V) во время генерации текста. Модель состоит из двух основных компонентов: механизма поиска и компонента памяти. MemLong может извлекать соответствующую историческую информацию на основе текущего ввода, тем самым расширяя доступный контекст для модели. Модель также обеспечивает динамическую систему управления памятью, которая умно обновляет хранимую информацию на основе частоты извлечения, обеспечивая приоритет наиболее актуальных данных и удаление устаревшей информации.
Результаты показывают, что MemLong превосходит другие современные LLM, включая OpenLLaMA, особенно в задачах изучения контекста с учетом извлечения. Архитектура MemLong позволяет эффективно интегрировать как локальный, так и исторический контекст, улучшая общую производительность в обработке длинных текстов.
Заключение
Исследование, представленное в статье «MemLong: Memory-Augmented Retrieval for Long Text Modeling», предлагает убедительное решение для преодоления вызовов, с которыми сталкиваются LLM при обработке длинных контекстов. MemLong эффективно расширяет длину контекста, сохраняя вычислительную эффективность и производительность модели. Этот инновационный подход адресует ограничения предыдущих методов и предоставляет прочную основу для будущих разработок в области моделирования длинных текстов и приложений с усилением поиска.
Проверьте статью. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и LinkedIn. Присоединяйтесь к нашему Telegram-каналу.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit.
Попробуйте AI Sales Bot от itinai.ru — этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
«`





















