
«`html
Мультимодальные модели больших языков (MLLM) в искусственном интеллекте
Мультимодальные модели больших языков (MLLM) представляют собой передовую область искусственного интеллекта, в которой модели интегрируют визуальную и текстовую информацию для понимания и генерации ответов. Эти модели развиваются из больших языковых моделей (LLM), которые отличались в понимании и генерации текста, и теперь также обрабатывают и понимают визуальные данные, значительно расширяя свои общие возможности.
Основная проблема
Основная проблема, рассматриваемая в данном исследовании, заключается в необходимости более полного использования визуальной информации в текущих MLLM. Несмотря на прогресс в обработке языка, визуальный компонент часто требует расширения до высокоуровневых признаков, извлеченных замороженным визуальным кодировщиком. Это исследование стремится изучить, как использование более детальных визуальных признаков может улучшить производительность MLLM, устраняя проблему полного использования визуальных сигналов для лучшего мультимодального понимания.
Практические решения
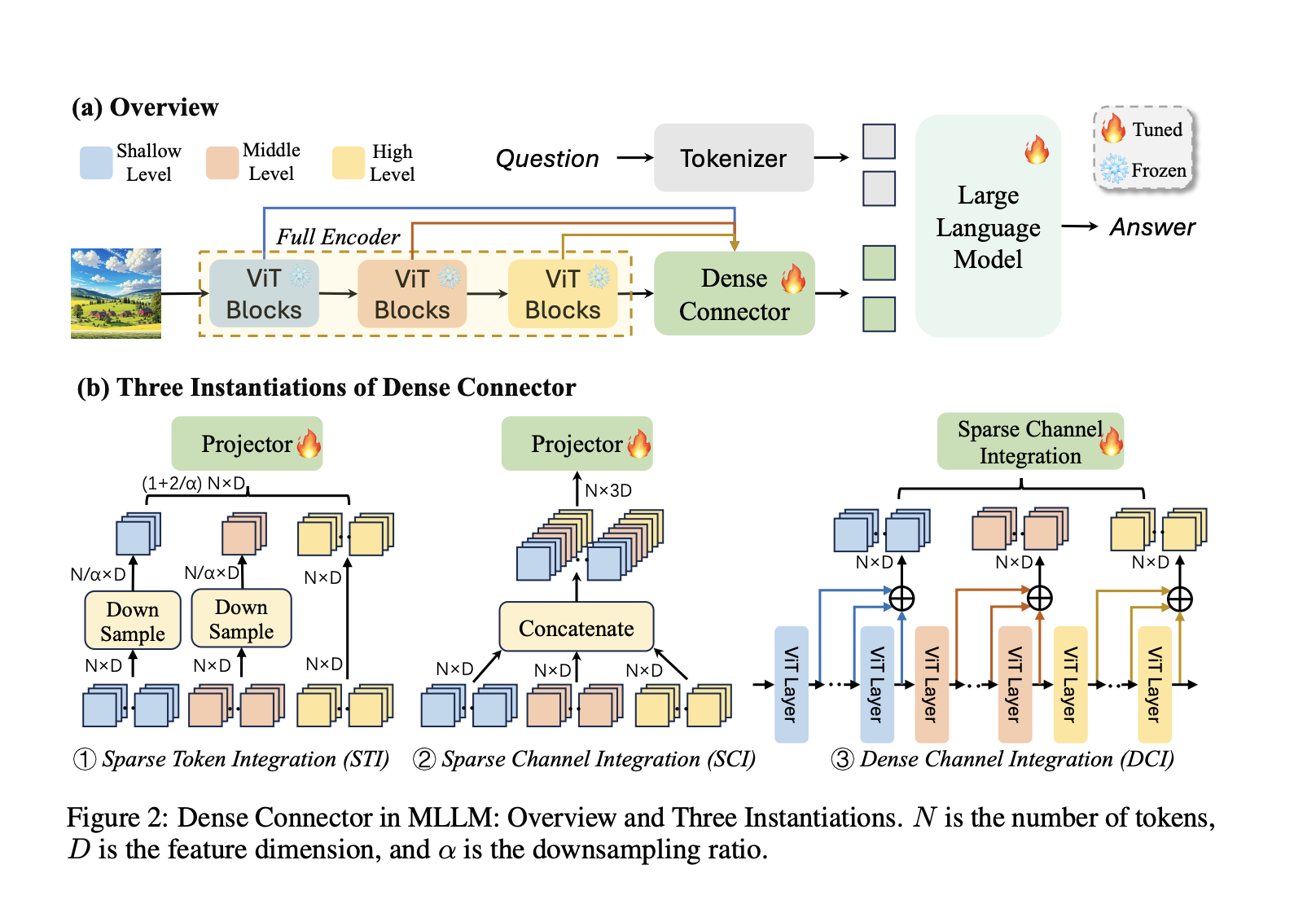
Текущие исследования включают различные рамки и модели для MLLM, такие как CLIP, SigLIP и Q-former, которые соединяют визуальные и языковые модели с использованием предварительно обученных визуальных кодировщиков и линейных проекций. Подходы, такие как LLaVA и Mini-Gemini, используют высокоразрешенные визуальные представления и настройку инструкций для повышения производительности. Методы, такие как Sparse Token Integration и Dense Channel Integration, эффективно используют многослойные визуальные признаки для улучшения устойчивости и масштабируемости MLLM по разнообразным наборам данных и архитектурам.
Исследователи из Университета Цинхуа, Baidu Inc., Университета Сиднея, Amazon Web Services и Китайского университета Гонконга представили Dense Connector, коннектор визуальной информации и языка, который улучшает MLLM, используя многослойные визуальные признаки. Этот инновационный коннектор решает ограничения текущих MLLM, предоставляя более полное интегрирование визуальных данных в языковую модель.
Далее Dense Connector продемонстрировал замечательные возможности в понимании видео и достиг значительных результатов на 19 бенчмарках изображений и видео. Он был протестирован с различными визионными кодировщиками, разрешениями изображений и размерами LLM, подтверждая его универсальность и масштабируемость. Экспериментальные результаты подчеркнули способность Dense Connector значительно улучшать визуальные представления в MLLM с минимальной вычислительной стоимостью.
В заключение, данное исследование представляет Dense Connector, новый метод, который улучшает MLLM путем эффективного использования многослойных визуальных признаков. Этот подход преодолевает ограничения текущих MLLM, где визуальная информация часто ограничивается высокоуровневыми признаками. Dense Connector предлагает несколько вариантов, каждый из которых интегрирует визуальные данные из различных слоев визуального кодировщика, улучшая качество визуальной информации, подаваемой в LLM без значительных вычислительных затрат.
Подробнее ознакомьтесь с статьей. Все авторские права на это исследование принадлежат исследователям данного проекта.
Не забудьте следить за нами в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наш рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit и ознакомиться с нашей платформой для событий по ИИ.