
«`html
tinyBenchmarks: революционное изменение оценки LLM с кураторскими наборами из 100 примеров, сокращая затраты на 98%, сохраняя высокую точность
Большие языковые модели (LLM) продемонстрировали выдающиеся возможности в области обработки естественного языка (NLP), выполняя задачи, такие как перевод, резюмирование и вопросно-ответное взаимодействие. Эти модели играют важную роль в развитии способов взаимодействия машин с человеческим языком, но оценка их производительности остается значительным вызовом из-за огромных вычислительных ресурсов, необходимых для этого.
Проблемы оценки LLM
Одной из основных проблем оценки LLM является высокая стоимость использования обширных наборов данных для проведения бенчмаркинга. Традиционные бенчмарки, такие как HELM и AlpacaEval, содержат тысячи примеров, что делает процесс оценки вычислительно сложным и финансово затратным. Например, оценка одной LLM на HELM может стоить более 4000 часов работы GPU, что эквивалентно более чем $10,000. Эти высокие затраты ограничивают возможность частой оценки и улучшения LLM, особенно при увеличении их размера и сложности.
Решение: tinyBenchmarks
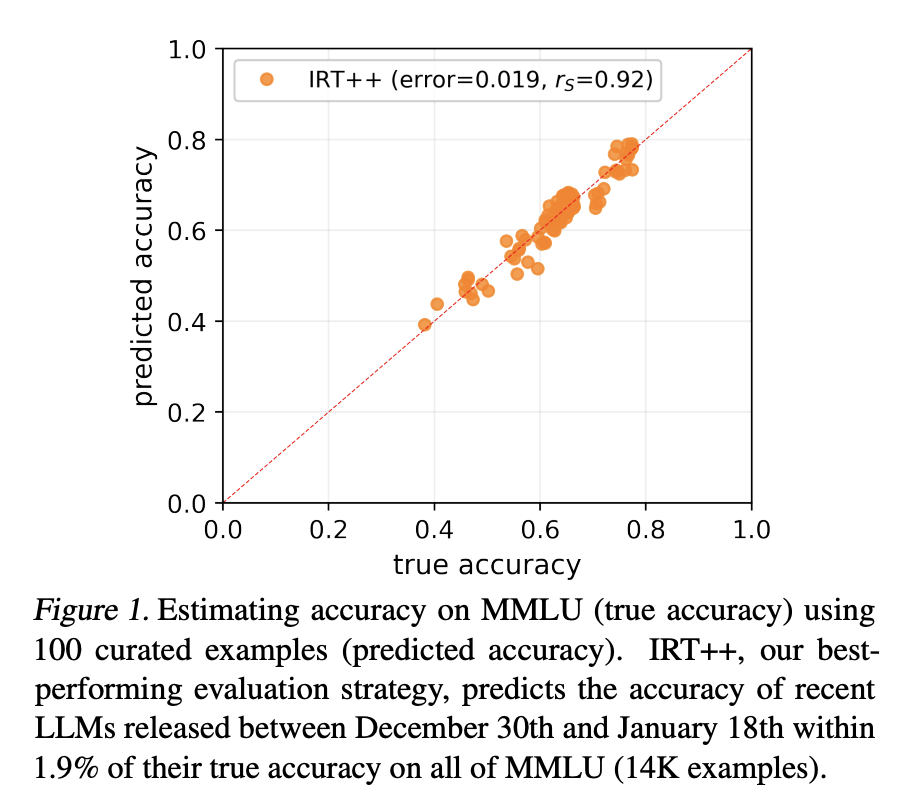
Для решения этой проблемы исследователи предложили концепцию «tinyBenchmarks». Они предложили разработку наборов надежных кураторских примеров, используя только 100 примеров из более крупных бенчмарков, что позволяет предсказывать производительность LLM с ошибкой менее 2%. Этот подход существенно снижает необходимые ресурсы для оценки, сохраняя при этом точность результатов.
Примененные методы
Для создания tinyBenchmarks исследователи использовали различные стратегии, такие как стратифицированная случайная выборка, объединение на основе уверенности модели и применение теории отклика элементов. Эти методы позволили создать надежные наборы для оценки, которые можно было эффективно использовать для предсказания производительности моделей.
Практическое применение
Тестирование показало, что рассмотренные tinyBenchmarks эффективно работают с различными наборами данных, что дает надежные оценки производительности LLM с погрешностью в 2%. Эта значительная экономия приводит к существенному уменьшению вычислительных и финансовых затрат.
tinyBenchmarks были валидированы и официально предоставлены командой исследователей для дальнейшего использования другими специалистами в данной области.
Использование ИИ для бизнеса
Использование подобных технологий в бизнесе может привести к значительным улучшениям. Постепенное внедрение ИИ-решений с последующим анализом результатов позволяет эффективно оптимизировать процессы и достигать поставленных целей.
«`




















