
«`html
Retrieval Augmented Generation (RAG) в сфере искусственного интеллекта
Retrieval Augmented Generation (RAG) представляет собой передовое достижение в области искусственного интеллекта, особенно в обработке естественного языка (NLP) и информационном поиске (IR). Эта техника разработана для улучшения возможностей крупных языковых моделей (LLM), интегрируя контекстуально значимую, своевременную и предметно-специфичную информацию в их ответы. Интеграция позволяет LLM более точно и эффективно выполнять задачи, особенно там, где важна собственная или актуальная информация. RAG привлек внимание, так как он решает потребность в более точных, контекстно осознанных выводах в системах, основанных на искусственном интеллекте. Это требование становится все более важным с увеличением сложности задач и запросов пользователей.
Основные преимущества методологии RAG:
- Улучшение точности и контекстной релевантности ответов
- Интеграция актуальной информации в ответы LLM
- Решение проблемы синтеза информации из больших и разнообразных наборов данных
- Повышение эффективности поиска информации в системах, основанных на искусственном интеллекте
Практические решения и ценность:
- Использование метаданных и синтетических вопросов и ответов для улучшения запросов пользователей
- Увеличение точности и полноты поиска информации
- Снижение издержек и возможность масштабирования решения для различных областей знаний
Новый подход к информационному поиску
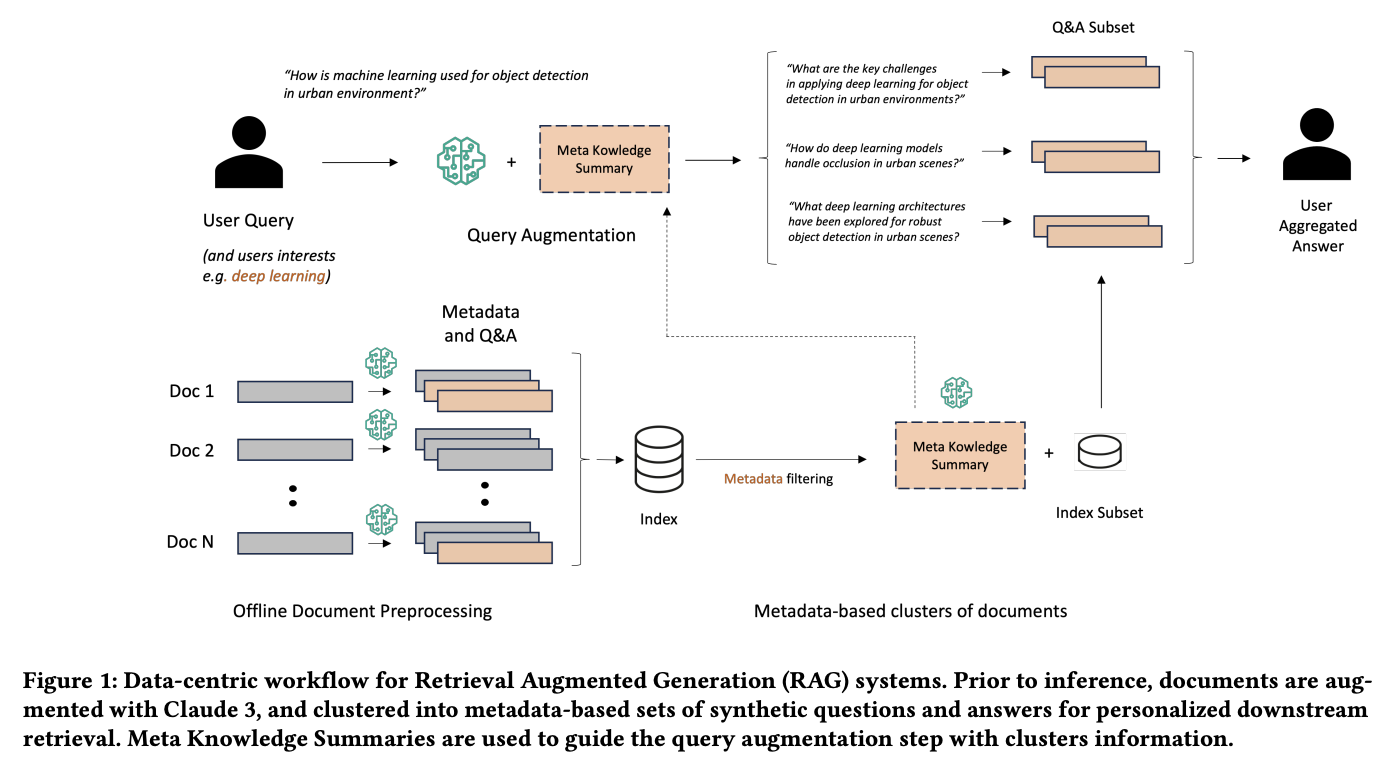
Команда исследователей Amazon Web Services представила новый метод информационного поиска, который значительно улучшает традиционные системы RAG. Этот подход включает в себя генерацию метаданных и синтетических вопросов и ответов для каждого документа, а также внедрение концепции Мета-краткого знания (MK Summary). MK Summary позволяет кластеризовать документы на основе метаданных, обеспечивая более персонализированное улучшение запросов пользователей и более точный информационный поиск по базе знаний.
Практические решения и ценность:
- Генерация метаданных и синтетических вопросов и ответов для каждого документа
- Кластеризация документов для улучшения информационного поиска
- Увеличение точности и релевантности ответов
Оценка нового подхода
Исследовательская команда продемонстрировала, что их новый подход значительно превосходит традиционные системы RAG по нескольким ключевым метрикам. Улучшенные запросы с использованием синтетических вопросов и ответов и MK Summaries достигли более высокой точности, полноты, специфичности и общего качества ответов. Например, уровень полноты увеличился с 77,76% в традиционных системах до 88,39% при использовании их метода, а ширина поиска увеличилась более чем на 20%. Способность системы генерировать более релевантные и конкретные ответы была улучшена, и оценки релевантности достигли 90,22%, по сравнению с более низкими показателями в традиционных методах.
Практические решения и ценность:
- Улучшение точности, полноты и релевантности ответов
- Повышение качества информационных систем на основе искусственного интеллекта
- Предложение масштабируемого и экономически эффективного решения для различных областей знаний
Заключение
Инновационный подход исследовательской команды к Retrieval Augmented Generation решает ключевые проблемы, связанные с традиционными системами RAG, особенно с проблемами сегментации документов и недостаточной спецификацией запросов. Путем использования метаданных и синтетических вопросов и ответов их методология, ориентированная на данные, значительно улучшает информационный поиск, обеспечивая более точные, релевантные и полные ответы. Это улучшение повышает качество информационных систем на основе искусственного интеллекта и предлагает экономически эффективное и масштабируемое решение, применимое в различных областях знаний. По мере развития искусственного интеллекта такие инновационные подходы будут крайне важны для обеспечения того, чтобы крупные языковые модели могли удовлетворить растущие требования к точности и контекстной релевантности в информационном поиске.
Источник изображения
Источник: [Image Source]
Источник
Полный текст исследования доступен по ссылке: [Paper]
Вся заслуга за это исследование принадлежит его авторам.
Подписывайтесь на нас
Не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе в LinkedIn.
Присоединяйтесь к нам
Не забудьте присоединиться к нашему сообществу в Reddit.
Будущие вебинары по искусственному интеллекту
Посмотрите расписание предстоящих вебинаров по искусственному интеллекту.
Оригинальная статья: AWS Enhancing Information Retrieval in Large Language Models: A Data-Centric Approach Using Metadata, Synthetic QAs, and Meta Knowledge Summaries for Improved Accuracy and Relevancy
«`



















