
«`html
Использование Искусственного Интеллекта для Оптимизации Производительности Моделей с Использованием Speculative Decoding: MagicDec и Adaptive Sequoia Trees
Спецификация декодирования в режиме спекуляции для повышения производительности на больших объемах длинных контекстов
Speculative decoding становится важной стратегией для увеличения пропускной способности вывода с длинным контекстом, особенно в свете растущей потребности в выводе с использованием больших языковых моделей (LLM) во многих приложениях. Исследование Together AI по speculative decoding направлено на решение проблемы увеличения пропускной способности вывода для LLM, обрабатывающих длинные входные последовательности и большие размеры пакетов. Это исследование предоставляет важные идеи для преодоления узких мест в памяти во время вывода, особенно при работе с длинными контекстами.
Контекст и Проблемы Длинных Контекстов При Выводе
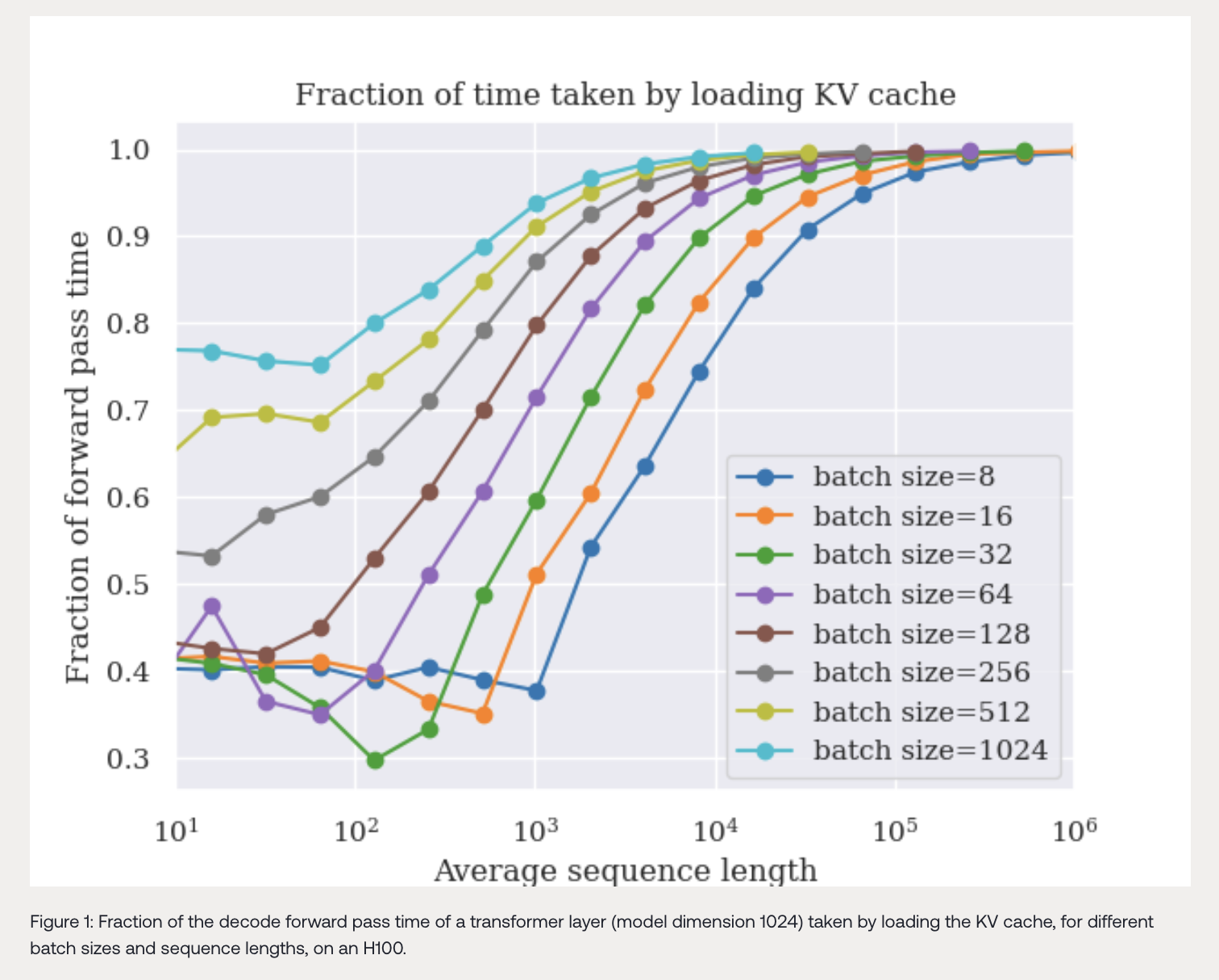
При увеличении использования LLM модели сталкиваются с обработкой более длинных контекстов. Приложения, такие как извлечение информации из больших наборов документов, генерация синтетических данных для настройки, продолжительные разговоры с пользователем и рабочие процессы агентов, требуют обработки последовательностей, охватывающих тысячи токенов. Это требование нагрузки на обработку длинных контекстов представляет техническую сложность, в значительной степени из-за обширных требований к памяти для хранения кэша ключ-значение (KV). Этот кэш необходим для обеспечения эффективного воспоминания моделью предыдущих частей длинных входных последовательностей.
Ключевые Инновации: MagicDec и Adaptive Sequoia Trees
Together AI представляет два важных алгоритмических достижения в speculative decoding: MagicDec и Adaptive Sequoia Trees, разработанные для увеличения пропускной способности при длинных контекстах и больших размерах пакетов.
1. MagicDec: Основное узкое место при выводе с длинным контекстом и большими пакетами — это загрузка KV кэша. MagicDec решает эту проблему, используя фиксированное окно контекста в черновой модели, что позволяет черновой модели функционировать быстрее, чем целевая модель. За счет фиксированного размера окна контекста KV кэш черновой модели значительно меньше, чем у целевой модели, что ускоряет спекулятивный процесс. Интересно, что такой подход также позволяет использовать очень большую и мощную черновую модель. Использование полной целевой модели в качестве черновой становится возможным в этом режиме, поскольку узким местом уже не является загрузка параметров модели.
2. Adaptive Sequoia Trees: Еще одно важное открытие из исследования Together AI заключается в том, что длина входных последовательностей влияет на то, насколько вывод становится связанным с памятью. Другими словами, чем длиннее последовательность, тем больше вывод зависит от загрузки и поддержания KV кэша. Adaptive Sequoia Trees адаптируются к этой ситуации, выбирая количество спекулированных токенов в зависимости от длины последовательности.
Память и Вычислительные Компромиссы в Speculative Decoding
Одна из фундаментальных проблем, с которой сталкивается Together AI, заключается в понимании баланса требований к памяти и вычислительным требованиям во время вывода. В процессе декодирования выполняются два типа операций: операции, связанные с параметрами модели, и операции, связанные с KV кэшем. По мере увеличения длины последовательностей операции, связанные с KV кэшем, становятся определяющим фактором в потреблении памяти, и, таким образом, вывод становится связанным с памятью.
Эмпирические результаты
Исследователи проверяют свои теоретические модели через эмпирический анализ, показывая, что speculative decoding может существенно улучшить производительность. Например, их результаты показывают, что при определенных условиях speculative decoding может достигать ускорения до 2 раз для моделей, таких как LLaMA-2-7B-32K и 1,84 раз для LLaMA-3.1-8B, обе на 8 A100 GPU. Эти результаты являются значительными, поскольку показывают, что speculative decoding может быть высокоэффективным, даже в масштабе, где большие размеры пакетов и длинные последовательности обычно делают вывод медленнее и требовательнее к памяти.
Выводы
Исследование Together AI по speculative decoding для вывода с длинным контекстом и высокой пропускной способности переосмысливает понимание того, как LLM можно оптимизировать для реальных масштабных приложений. Фокусируясь на узкие места памяти, а не только на вычислительных ограничениях, это исследование демонстрирует, что speculative decoding может значительно увеличить пропускную способность модели и снизить задержку, особенно для приложений, работающих с длинными входными последовательностями. Благодаря таким инновациям, как MagicDec и Adaptive Sequoia Trees, speculative decoding готов стать ключевым методом для улучшения производительности LLM в сценариях с длинным контекстом. Это важно для будущих приложений, зависящих от работы с масштабным выводом.
Источники
- https://www.together.ai/blog/speculative-decoding-for-high-throughput-long-context-inference
- https://arxiv.org/pdf/2408.11049
Если ваша компания заинтересована в оптимизации производительности с помощью искусственного интеллекта, свяжитесь с нами для консультации и внедрения инновационных решений. Мы поможем вам найти подходящие решения и постепенно внедрить их для улучшения результатов вашего бизнеса.
При возникновении вопросов по внедрению искусственного интеллекта, обращайтесь к нам по ссылке https://t.me/itinai или следите за новостями в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Ознакомьтесь с AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах поможет вам обработать запросы клиентов, генерировать контент для отдела продаж и снизить нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`





















