
Улучшение обучения без учителя с помощью автоматической курирования данных: подход иерархического K-средних
Современное машинное обучение тесно связано с самообучаемыми признаками, которые обычно требуют обширных усилий человека для сбора и курирования данных, аналогично обучению с учителем. Самообучение (SSL) позволяет обучать модели без участия человека, обеспечивая масштабируемость данных и моделей. Однако усилия по масштабированию порой приводили к недостаточной производительности из-за проблем, таких как долгохвостое распределение концепций в неотсортированных наборах данных. Успешные применения SSL включают тщательное курирование данных, такое как фильтрация интернет-данных для соответствия высококачественным источникам, например Википедии, для языковых моделей, или балансировка визуальных концепций для моделей изображений. Это курирование повышает устойчивость и производительность в последующих задачах.
Автоматическое курирование данных в самообучающем обучении
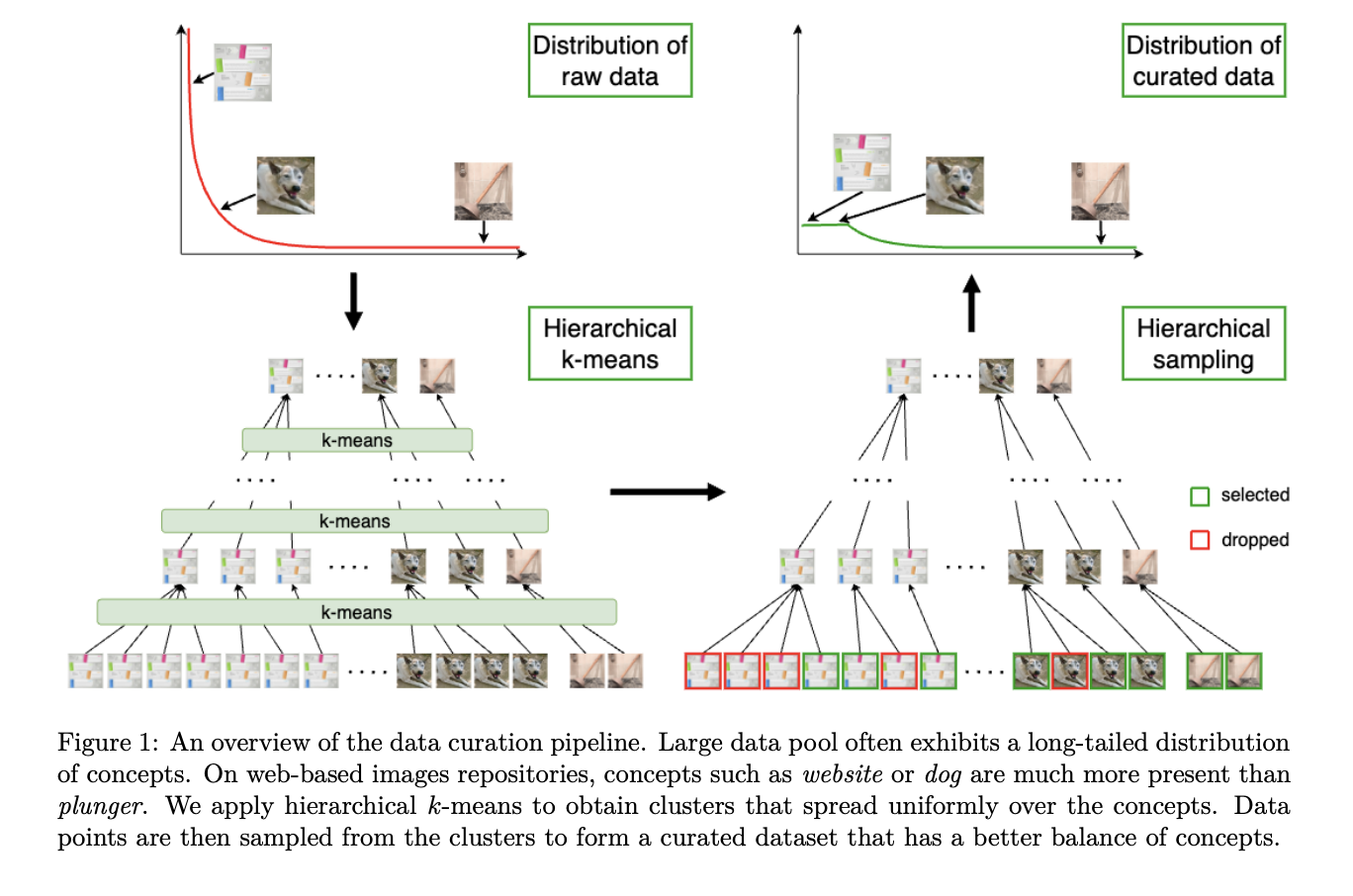
Исследователи из FAIR в Meta, INRIA, Université Paris Saclay и Google предлагают кластерный подход к автоматическому созданию крупных, разнообразных и сбалансированных наборов данных для предварительного обучения без учителя. Этот метод включает иерархическую кластеризацию k-средних на обширном репозитории данных и сбалансированную выборку из этих кластеров. Эксперименты с веб-изображениями, спутниковыми изображениями и текстом показывают, что признаки, обученные на этих отсортированных наборах данных, превосходят те, которые обучены на неотсортированных данных, соответствуя или превосходя вручную сортированные данные. Такой подход решает проблему балансировки наборов данных для улучшения производительности моделей в самообучающем обучении.
Ключевое значение самообучающего обучения в современном машинном обучении
Самообучение имеет ключевое значение в современном машинном обучении. В обработке естественного языка (NLP) языковое моделирование развивается от простых нейронных архитектур к масштабным моделям, значительно продвигая эту область. Аналогично самообучение в компьютерном зрении продвигается от предварительных задач к сложным совместным архитектурам вложения, используя методы, такие как контрастное обучение, кластеризация и дистилляция. Высококачественные данные важны для обучения современных моделей. Предлагаются автоматические техники курирования данных, такие как иерархическая кластеризация k-средних, для балансировки крупных наборов данных без требования меток, улучшая производительность моделей SSL в различных областях.
Эксперименты и результаты
Четыре эксперимента были проведены для изучения предложенного алгоритма. Вначале использовались моделированные данные, чтобы проиллюстрировать иерархическую кластеризацию k-средних, показывая более равномерное распределение кластеров, чем другие методы. Затем были отсортированы веб-изображения, что привело к набору данных из 743 миллионов изображений, и модель ViT-L была обучена и оценена на различных бенчмарках, продемонстрировав улучшенную производительность. Алгоритм затем был применен для курирования текстовых данных для обучения больших языковых моделей, что привело к значительным улучшениям по всем бенчмаркам. Наконец, спутниковые изображения были отсортированы для предсказания высоты кроны деревьев, улучшая производительность модели на всех оцененных наборах данных.
Заключение
Исследование представляет автоматический конвейер курирования данных, который генерирует крупные, разнообразные и сбалансированные наборы данных для самообучения признаков. Путем последовательного применения кластеризации k-средних и повторной выборки метод обеспечивает равномерное распределение кластеров среди концепций. Обширные эксперименты показывают, что этот подход улучшает обучение признаков для веб-изображений, спутниковых изображений и текстовых данных. Отсортированные наборы данных превосходят необработанные данные и ImageNet1k в устойчивости, но немного уступают тщательно отсортированному ImageNet22k по некоторым бенчмаркам. Данный подход подчеркивает важность курирования данных в самообучающем обучении и предлагает иерархический k-средних как ценную альтернативу в различных задачах, зависящих от данных. Дальнейшая работа должна рассматривать качество набора данных, зависимость от предварительно обученных признаков и масштабируемость. Автоматическое создание наборов данных предполагает риски, такие как укрепление предубеждений и нарушения конфиденциальности, которые здесь минимизированы путем размытия лиц и стремления к балансу концепций.
Подробнее см. Статью. Вся благодарность за этот исследовательский проект принадлежит исследователям. Также не забудьте подписаться на наш Telegram-канал, и следите за новостями о ИИ в нашем Twitter.
Применение искусственного интеллекта в вашем бизнесе
Если вы хотите развивать свою компанию с помощью искусственного интеллекта (ИИ) и оставаться в числе лидеров, грамотно используйте подход иерархического K-средних. Проанализируйте, как ИИ может изменить вашу работу и определите возможности автоматизации, которые могут принести выгоду вашим клиентам. Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ. Подберите подходящее решение среди разнообразных вариантов ИИ и внедряйте его постепенно, начиная с малого проекта и анализируя результаты и KPI. На основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter. Также рекомендуем попробовать AI Sales Bot — этот искусственный интеллект в продажах поможет вам в общении с клиентами, генерации контента и снижении нагрузки на первую линию.
Преобразование вашего бизнеса с помощью AI Lab itinai.ru
Узнайте, как искусственный интеллект может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!




















