
«`html
Токенизация в LLM: проблема и решение
Проблема токенизации в LLM
Токенизация является ключевым элементом в вычислительной лингвистике, особенно в обучении и функционировании больших языковых моделей (LLM). Этот процесс включает в себя разделение текста на управляемые части или токены, что является основой для обучения и работы модели. Однако неэффективная токенизация может существенно снизить производительность модели, особенно если токены в словаре модели недостаточно представлены или отсутствуют в обучающих наборах данных, что приводит к появлению так называемых «запутанных токенов». При обработке новых входных данных эти токены могут дестабилизировать модель и приводить к непредсказуемым результатам.
Решение проблемы
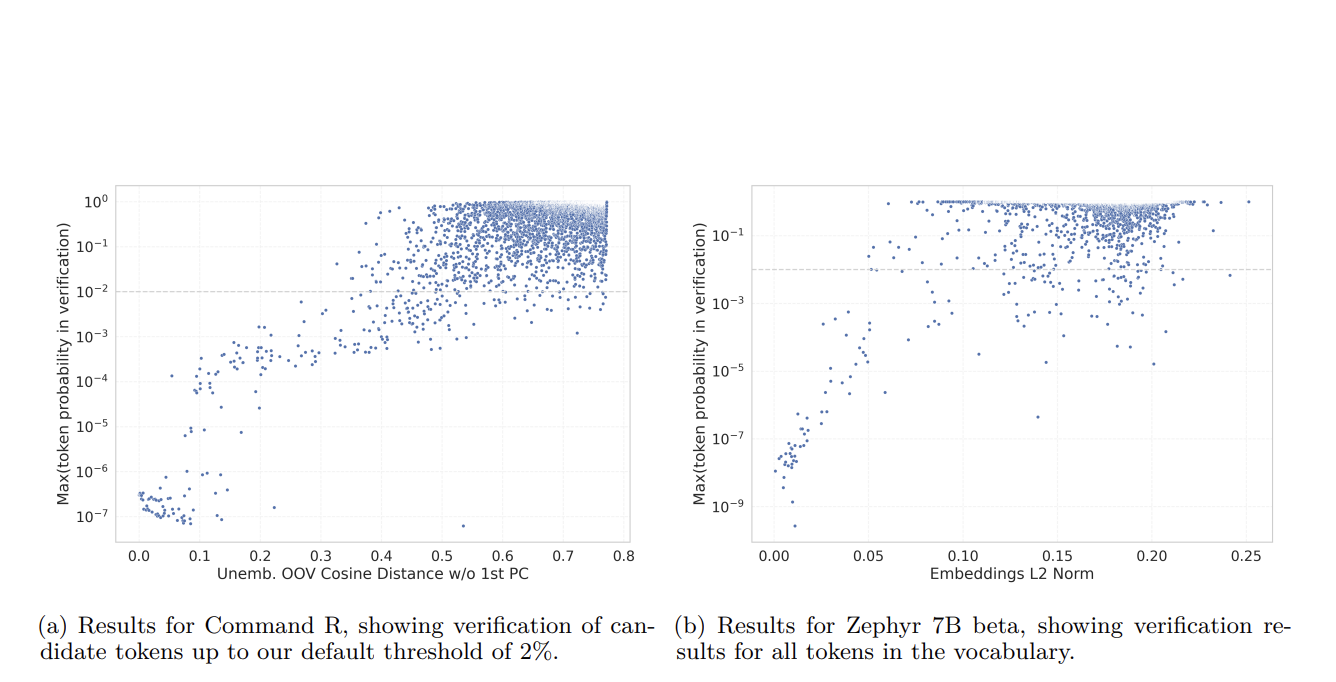
Исследователи из Cohere представляют новый подход, который использует веса вложения модели для автоматизации и масштабирования обнаружения недообученных токенов. Они разработали метод анализа этих весов для выявления аномалий, указывающих на недостаточное обучение. Этот метод предоставляет систематический способ выявления запутанных токенов путем расчета дисперсии и распределения весов вложения и их сравнения с нормативной моделью должным образом обученных токенов.
Исследование продемонстрировало эффективность этого нового метода при его применении к нескольким известным моделям, включая варианты BERT от Google и серию GPT от OpenAI. Анализ позволил выявить значительный процент словаря токенизатора, до 10% в некоторых случаях, как недообученные. Эти токены часто являются специализированными или редко используемыми словами, которые проявляют наибольшие расхождения в образцах весов вложения.
Значение и практическое применение
Это исследование имеет значительные последствия для разработки и поддержки LLM. Путем использования автоматизированных методов для обнаружения и устранения недообученных токенов разработчики могут улучшить точность и надежность языковых моделей. Этот прогресс критически важен, поскольку LLM все чаще используются в различных приложениях, от автоматизированных средств письменной поддержки до сложных разговорных агентов.
В заключение, это исследование выделяет критическую уязвимость в обучении LLM и предлагает масштабируемое решение для устранения этой проблемы. Внедрение автоматизированных методов для обнаружения недообученных токенов позволяет обеспечить более надежные процессы обучения, гарантируя, что все токены в словаре модели должным образом подготовлены для работы в реальных приложениях. Это исследование улучшает эффективность и надежность языковых моделей, открывая путь к более надежным и эффективным инструментам обработки естественного языка.
Подробнее о исследовании можно узнать здесь.
Авторы исследования: Cohere.
Следите за нами в Twitter.
Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Подпишитесь на нашу рассылку.
Присоединяйтесь к нашему сообществу в Reddit.