
«`html
Улучшение текстовых вложений в малых языковых моделях: подход к контрастному донастройке с MiniCPM
LLM мастерски владеют пониманием естественного языка, но требуют много ресурсов, что ограничивает их доступность. Более компактные модели, такие как MiniCPM, обладают лучшей масштабируемостью, но часто требуют целенаправленной оптимизации для достижения высокой производительности. Текстовые вложения, векторные представления, которые охватывают семантическую информацию, являются важными для задач, таких как классификация документов и поиск информации. В то время как LLM, такие как GPT-4, LLaMA и Mistral, достигают высокой производительности благодаря обширному обучению, более компактные модели, такие как Gemma, Phi и MiniCPM, требуют специфической оптимизации для устранения разрыва в производительности и поддержания эффективности.
Исследование университета Цинхуа
Исследователи Университета Цинхуа изучили способы улучшения более компактных языковых моделей путем усовершенствования их текстовых вложений. Они сосредоточились на трех моделях — MiniCPM, Phi-2 и Gemma — и применили контрастную донастройку с использованием набора данных NLI. Исследование показало, что этот метод значительно улучшил качество текстовых вложений по различным критериям, дав заметный прирост производительности у MiniCPM на уровне 56,33%. Это исследование решает проблему недостаточного внимания к более компактным моделям и направлено на увеличение эффективности MiniCPM для приложений с ограниченными ресурсами, демонстрируя его потенциал наряду с другими моделями, такими как Gemma и Phi-2, после донастройки.
Текстовые вложения и их роль
Текстовые вложения — это низкоразмерные векторные представления текста, которые захватывают семантический смысл и поддерживают задачи, такие как информационный поиск, классификация и сопоставление похожести. Традиционные модели, такие как SBERT и Sentence T5, нацелены на обеспечение универсального кодирования текста, в то время как более новые методы, такие как Contriever и E5, улучшают вложения с помощью стратегий многозначностного обучения. Контрастное обучение представлений, включающее техники, такие как триплет-потери и InfoNCE, направлено на обучение эффективных представлений путем сопоставления похожих и различных точек данных. Легкие языковые модели, такие как Phi, Gemma и MiniCPM, решают проблему ресурсозатратности крупных моделей, предлагая более эффективные альтернативы. Методы донастройки, такие как модули адаптеров и LoRA, позволяют проводить специфическую адаптацию предварительно обученных моделей сниженными вычислительными затратами.
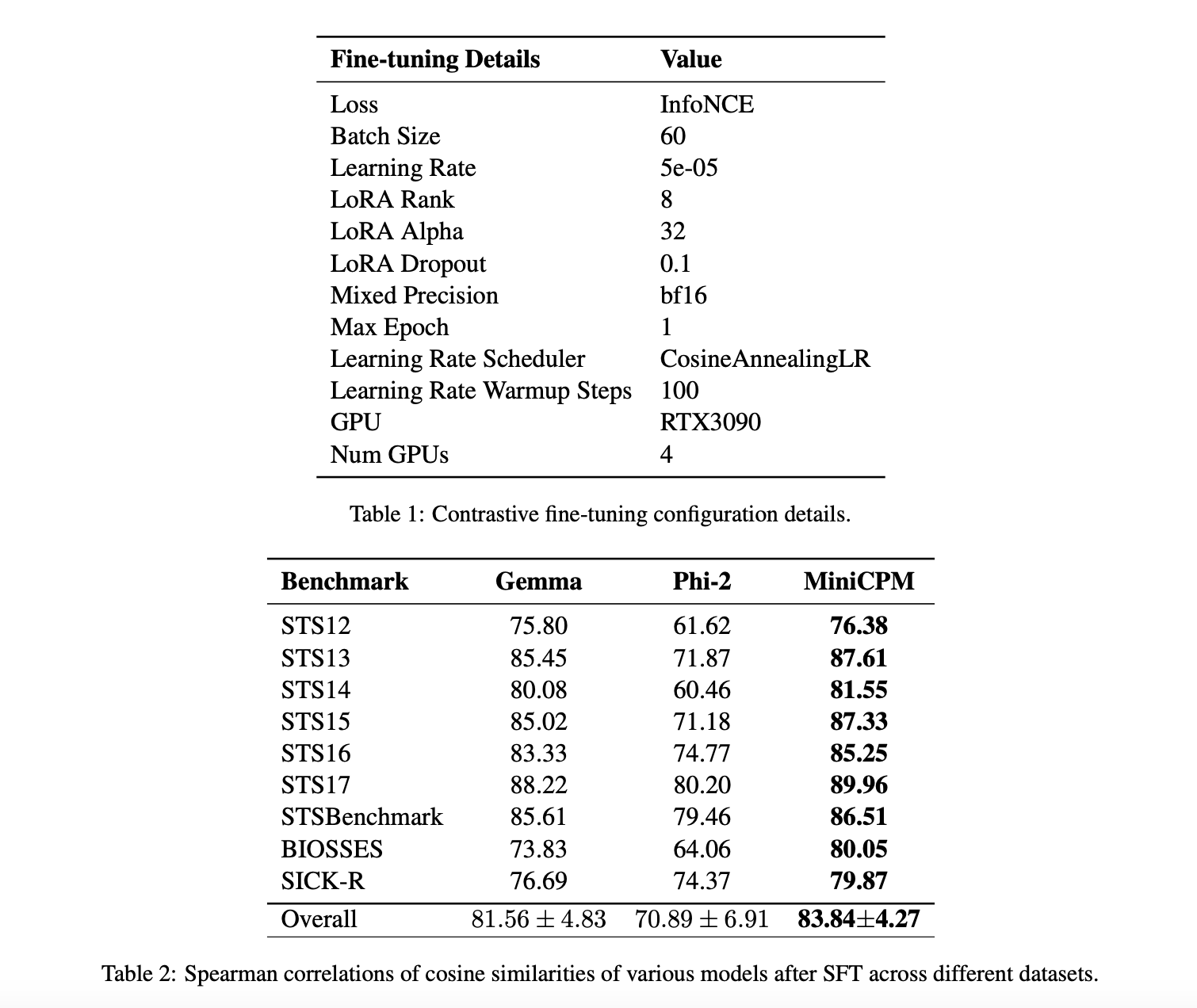
Практические результаты исследования
Эксперименты фокусировались на измерении сходства вложений для пар предложений с использованием косинусного сходства и корреляций Спирмена. MiniCPM, Gemma и Phi-2 оценивались по девяти критериям, включая STS12-17, STSBenchmark, BIOSSES и SICK-R. Результаты показали, что MiniCPM последовательно превосходит другие модели, достигая наивысших коэффициентов корреляции Спирмена по всем наборам данных. Донастройка с использованием LoRA значительно улучшает производительность, и MiniCPM показывает улучшение на 56 пунктов. Исследования абляции показали влияние скорости обучения, подсказок и жестких отрицательных значений на производительность, указывая на высокую эффективность контрастной донастройки и штрафов за жесткие отрицательные значения для MiniCPM.
Заключение
Исследование успешно улучшило возможности текстовых вложений MiniCPM с помощью контрастной донастройки на наборе данных NLI. Донастройка привела к заметному улучшению производительности на уровне 56,33%, позволяя MiniCPM опережать другие модели, такие как Gemma и Phi-2, по девяти критериям STS. Были проведены множественные исследования абляции для изучения влияния настройки подсказок, эффективности обучения и включения жестких отрицательных значений. Исследование повышает надежность и устойчивость текстовых вложений в масштабируемых и ресурсоэффективных альтернативах крупных моделей с сохранением высокой производительности в задачах понимания естественного языка.
Посмотреть статью и репозиторий на GitHub можно по ссылке: Paper and GitHub. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit. Также здесь вы можете найти предстоящие вебинары о ИИ.
Arcee AI выпустила DistillKit: открытый инструмент для модельного дистилляции, который упрощает создание эффективных малых языковых моделей.
«`
















