
«`html
Продвижение этичного ИИ: Предпочтительное согласование обучения с подкреплением от обратной связи человека (RLHF) для согласования LLM с человеческими предпочтениями
Большие языковые модели (LLM), такие как ChatGPT-4 и Claude-3 Opus, отличаются в задачах, таких как генерация кода, анализ данных и рассуждения. Их растущее влияние на принятие решений в различных областях делает важным согласование их с человеческими предпочтениями, чтобы обеспечить справедливость и звуковые экономические решения. Человеческие предпочтения сильно различаются из-за культурного контекста и личного опыта, и LLM часто проявляют предвзятость, выражающую предпочтение доминирующих точек зрения и часто встречающихся элементов. Если LLM не точно отражают эти разнообразные предпочтения, предвзятые выводы могут привести к несправедливым и экономически невыгодным результатам.
Предложение практических решений и ценности:
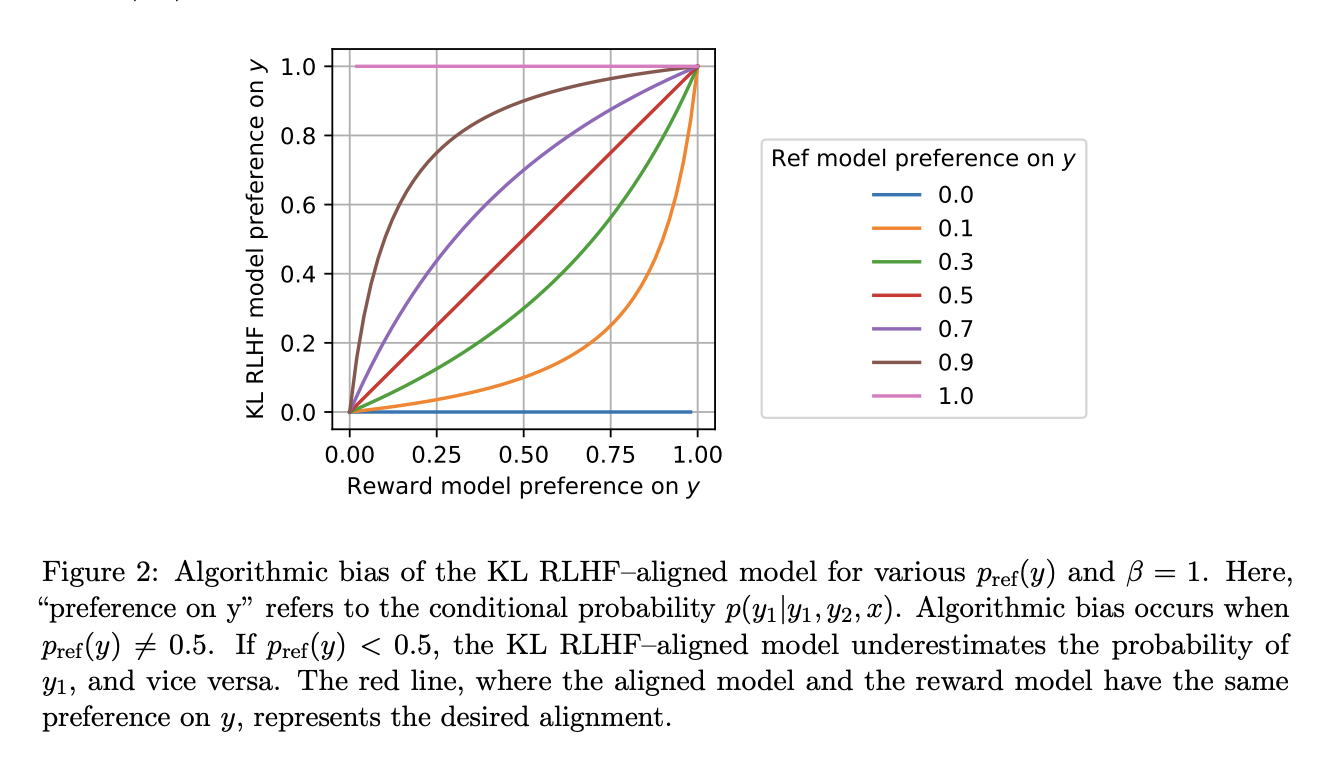
Исследователи представили новаторский подход, предпочтительное согласование обучения с подкреплением от обратной связи человека (Preference Matching RLHF), направленный на смягчение алгоритмической предвзятости и эффективное согласование LLM с человеческими предпочтениями. В центре этого инновационного метода лежит предпочтительный регуляризатор, полученный путем решения обыкновенного дифференциального уравнения. Этот регуляризатор обеспечивает баланс между диверсификацией ответов и максимизацией вознаграждения, улучшая способность модели точно отражать человеческие предпочтения. Предпочтительное согласование RLHF обеспечивает надежные статистические гарантии и эффективно устраняет предвзятость, присущую традиционным подходам RLHF. Экспериментальная проверка предпочтительного согласования RLHF на моделях OPT-1.3B и Llama-2-7B показала значительные улучшения в согласовании LLM с человеческими предпочтениями. Результаты подчеркивают потенциал предпочтительного согласования RLHF в продвижении исследований в области ИИ к более этичным и эффективным процессам принятия решений.
Практическая ценность:
Предпочтительное согласование RLHF вносит значительный вклад в борьбу с алгоритмической предвзятостью и улучшение согласования LLM с человеческими предпочтениями. Этот прогресс может улучшить процессы принятия решений, способствовать справедливости и уменьшить предвзятые выводы LLM, продвигаясь в области исследований в области ИИ.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 43 тыс. подписчиков. Также ознакомьтесь с нашей платформой для событий по ИИ.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















