
«`html
Модели машинного обучения для прогнозирования эффективности основного редактирования
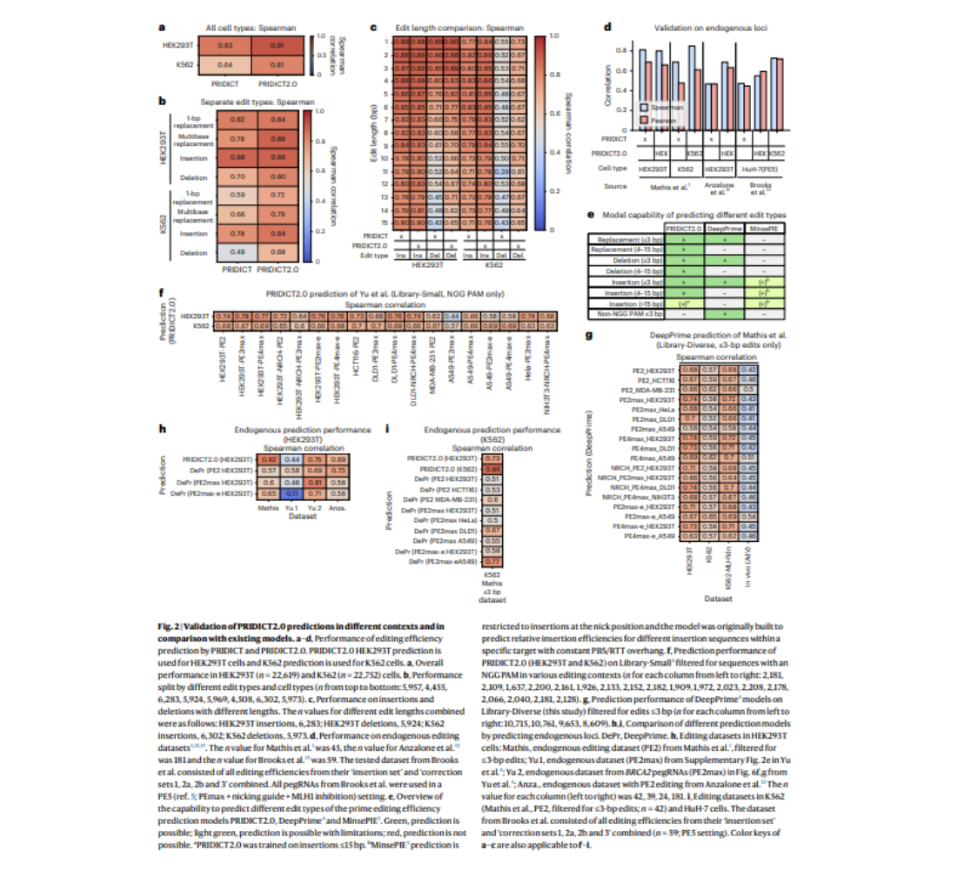
Успех основного редактирования в значительной степени зависит от конструкции направляющей РНК основного редактирования (pegRNA) и местоположения цели. Для решения этой проблемы исследователи разработали две взаимодополняющие модели машинного обучения — PRIDICT2.0 и ePRIDICT — для прогнозирования эффективности основного редактирования при различных типах изменений и хроматиновых контекстах. PRIDICT2.0, усовершенствованная версия предыдущей модели PRIDICT1, оценивает производительность pegRNA для изменений до 15 пар оснований (bp) в клеточных линиях с дефицитом и без дефицита системы ремонта несоответствий (MMR). В то же время ePRIDICT количественно оценивает, как местные хроматиновые среды влияют на скорость основного редактирования. Используя разнообразную библиотеку pegRNA в клетках HEK293T (с дефицитом MMR) и K562 (без дефицита MMR), исследование показало, что PRIDICT2.0 значительно превосходит своего предшественника, особенно при многозначных заменах и удалениях. Устойчивость модели была подтверждена через обширную валидацию, показав сильные корреляции между экспериментальными повторами и улучшенную производительность по сравнению с предыдущими моделями.
Выводы о хроматиновом контексте и эффективности редактирования
Одним из ключевых достижений этого исследования является включение хроматинового контекста как фактора, влияющего на эффективность основного редактирования. ePRIDICT была разработана для прогнозирования результатов редактирования, учитывая локус-специфические хроматиновые особенности, добавляя новый уровень точности к прогнозам редактирования. Анализ объяснений аддитивной важности Шэпли (SHAP) показал, что такие особенности, как длина изменения, наличие последовательностей полиТ и длина RTT-свеса, были высоко актуальны в клетках HEK293T, в то время как позиция, температура плавления и содержание G+C играли решающую роль в клетках K562. Исследование также показало, что образцы редактирования в клетках с дефицитом MMR напоминали те, что в клетках K562 с подавленными путями MMR, что дополнительно подчеркивает важность учета хроматинового контекста для точных прогнозов. Благодаря этим выводам модели предлагают ценные инструменты для улучшения конструкции pegRNA и максимизации эффективности основного редактирования в различных биологических контекстах.
Роль хроматина в эффективности редактирования генома
Для изучения влияния хроматина на редактирование генома клетки были обработаны ABE8e, BE4max и Cas9, что показало сильные корреляции в эффективности редактирования, особенно между ABE8e и BE4max. Активные хроматиновые особенности, такие как ATAC-последовательность и H3K4me3, положительно коррелировали с эффективностью редактирования, в то время как подавляющие метки (H3K9me3, H3K27me3) были связаны с более низкой эффективностью. Анализ UMAP выявил градиент хроматина, влияющий на редактирование. Модель ‘ePRIDICT’ на основе XGBoost, обученная на хроматиновых данных, эффективно прогнозировала результаты редактирования. Комбинирование ее с PRIDICT2.0 улучшило точность, особенно в областях с более низкой доступностью хроматина, подтверждая решающую роль хроматина в результатах редактирования.
Клонирование и конструкция pegRNA
Библиотека плазмид TRIP, использованная в исследованиях хроматинового контекста, была создана в соответствии с определенным протоколом. Для валидации pegRNA на эндогенных мишенях было выбрано 20 геномных сайтов из предыдущего скрининга — 10 сайтов с высокой и 10 с низкой эффективностью редактирования. PegRNA были разработаны для достижения различных генетических модификаций: замены 1 пары оснований, вставки 4 пар оснований и удаления 4 пар оснований. PegRNA были выбраны на основе их прогнозируемой эффективности редактирования и конкретного наличия нуклеотидов в их целевых окнах. Кроме того, было разработано и клонировано еще 90 pegRNA, нацеленных на интронные и межгенные области, с использованием определенного вектора. sgRNA были введены в плазмиду через одноэтапную реакцию клонирования, затем трансформированы в компетентные бактериальные клетки, произведена экстракция плазмиды и верификация.
Производство и скрининг вирусных векторов
Лентивирусные и псевдотипированные векторы AAV9 были произведены путем трансфекции клеток HEK293T необходимыми плазмидами и очистки векторов через серию осаждения и центрифугирования. Также был произведен отдельный вирусный вектор, содержащий компонент основного редактирования. Библиотека pegRNA, разработанная для включения патогенных вариантов и мутаций в некодирующих областях, была заказана у коммерческого поставщика. Различные клеточные линии, включая HEK293T, HepG2 и K562, поддерживались в определенных условиях и подвергались трансфекции или электропорации для редактирования. Скрининг включал трансдукцию клеток лентивирусом и выбор отредактированных клеток с использованием антибиотиков. Для in vivo исследований векторы вводились в мышей, которых затем усыпляли для изоляции гепатоцитов. Геномная ДНК из этих экспериментов была изолирована и проанализирована с использованием техник секвенирования высокого пропускания.
Анализ библиотеки и эффективности редактирования
Последовательности чтения были обрезаны и отфильтрованы для обеспечения точности, удалив ~34% чтений в клетках HEK293T и K562 и ~60% в гепатоцитах мыши. Эффективность редактирования была рассчитана путем сравнения последовательностей чтения с диким типом и отредактированными последовательностями, корректируя фоновые частоты. PegRNA были валидированы с использованием конкретных критериев и усреднены по повторам, что привело к нескольким наборам данных. Для библиотеки TRIP тагментация была последована ПЦР-усилением и секвенированием. Эффективность редактирования была проанализирована с помощью настраиваемых сценариев и перекрестно-ссылочных с хроматиновыми данными из ENCODE. Модели машинного обучения, включая PRIDICT2.0, были обучены и валидированы с использованием различных наборов данных, а их производительность оценивалась путем перекрестной проверки и анализа важности признаков.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Кроме того, не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему ML SubReddit
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ: «SAM 2 для видео: как настроить на ваши данные» (Ср, 25 сентября, 4:00 — 4:45 EST)
Этот пост был опубликован на сайте MarkTechPost.