
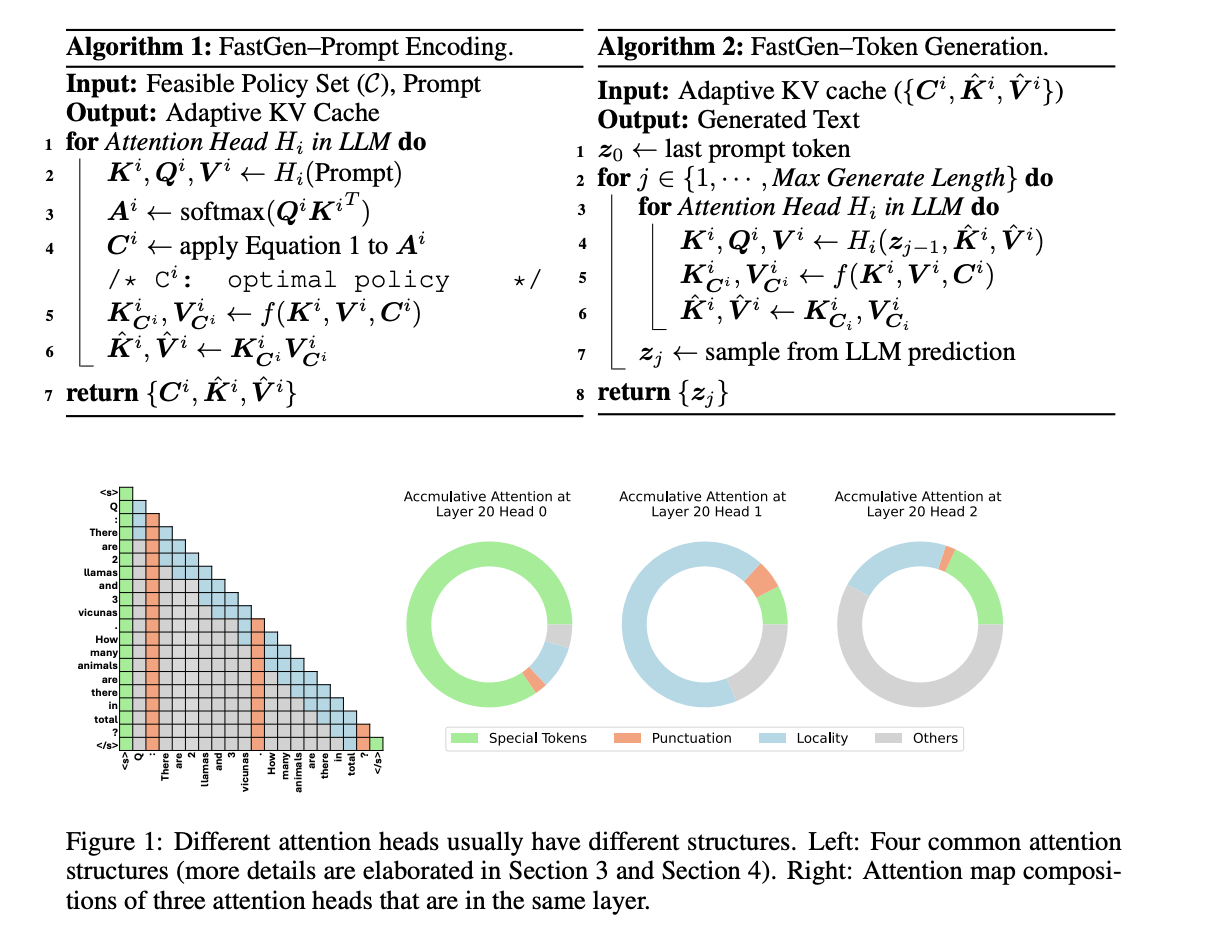
«`html
Авторегрессивные языковые модели (ALM)
Авторегрессивные языковые модели (ALM) доказали свою способность в машинном переводе, генерации текста и других областях. Однако эти модели сталкиваются с проблемами, такими как вычислительная сложность и использование памяти GPU. Несмотря на большой успех в различных приложениях, существует срочная необходимость найти эффективный способ обслуживания этих моделей. Применение генеративного вывода больших языковых моделей (LLM) использует механизм KV-кеша для улучшения скорости генерации. Однако увеличение размера модели и длины генерации приводит к увеличению использования памяти KV-кеша. Когда использование памяти превышает емкость GPU, генеративный вывод LLM прибегает к переносу.
Решение и его ценность:
Исследователи из Университета Иллинойса в Урбане-Шампейне и Microsoft предложили FastGen — высокоэффективную технику для повышения эффективности вывода LLM без видимых потерь в качестве, используя профилирование легких моделей и адаптивное кэширование ключ-значение. FastGen способен снизить использование памяти GPU с незначительной потерей качества генерации.
Применение адаптивного кэширования KV:
Адаптивное сжатие KV-кеша, предложенное исследователями, уменьшает занимаемую память генеративным выводом LLM. Для моделей 30B FastGen превосходит все методы неадаптивного сжатия KV и достигает более высокого коэффициента сжатия KV-кеша с увеличением размера модели, сохраняя качество модели неизменным. Например, FastGen достигает коэффициента стрижки 44,9% на Llama 1-65B, по сравнению с коэффициентом стрижки 16,9% на Llama 1-7B, что является 45% выигрышем. Кроме того, проведен анализ чувствительности FastGen при выборе различных гиперпараметров, который показал, что изменение гиперпараметров не влияет на качество генерации.
Вывод:
FastGen — новая техника для повышения эффективности вывода LLM без потерь в качестве, используя профилирование легких моделей и адаптивное кэширование ключ-значение. Адаптивное сжатие KV-кеша, внедренное с помощью FastGen, уменьшает объем занимаемой памяти генеративным выводом для LLM. Будущая работа включает интеграцию FastGen с другими методами сжатия моделей, такими как квантизация и дистилляция, групповое внимание, и др.
Подробнее в статье. Вся благодарность за это исследование исследователям этого проекта. Также, не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, чату в Discord, и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш newsletter. Также присоединяйтесь к нашему сообществу в ML SubReddit.
Приложение AI в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте FastGen: Cutting GPU Memory Costs Without Compromising on LLM Quality. Проанализируйте, как ИИ может изменить вашу работу, определите, где возможно применение автоматизации, и подберите подходящее решение. Внедряйте ИИ решения постепенно, начиная с малого проекта, и анализируйте результаты и KPI.
Если вам нужны советы по внедрению ИИ, пишите нам в [https://t.me/itinai](https://t.me/itinai). Присоединяйтесь к нашему Телеграм-каналу [t.me/itinainews](t.me/itinainews) или в Twitter [https://twitter.com/itinairu45358](https://twitter.com/itinairu45358).
Попробуйте AI Sales Bot [https://itinai.ru/aisales](https://itinai.ru/aisales). Этот AI ассистент в продажах поможет вам отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab [itinai.ru](https://itinai.ru). Будущее уже здесь!
«`





















