
Улучшение работы больших языковых моделей
Улучшение обработки сложных задач рассуждения большими языковыми моделями (LLMs) при низких вычислительных затратах представляет собой вызов. Генерация нескольких шагов рассуждения и выбор наилучшего ответа увеличивает точность, но требует много памяти и вычислительных ресурсов. Обработка длинных цепочек рассуждений или больших партий данных является дорогостоящей и замедляет модели, что делает их неэффективными при ограниченных вычислительных ресурсах.
Текущие методы и их ограничения
В настоящее время методы улучшения рассуждений в больших языковых моделях основываются на генерации нескольких шагов рассуждения и выборе лучшего ответа с использованием таких техник, как голосование большинством и обученные модели вознаграждения. Эти методы повышают уровень точности, но требуют больших вычислительных систем, что делает их неподходящими для обработки больших объемов данных.
Предложенные решения
Исследователи из Университета Женевы, Together AI, Корнеллского университета, EPFL, Университета Карнеги-Меллона, Cartesia.ai, META и Принстонского университета предложили метод дистилляции для создания субквадратных моделей с сильными способностями рассуждения, что улучшает эффективность при сохранении этих способностей. Дистиллированные модели показали лучшие результаты по задачам MATH и GSM8K, достигая аналогичной точности при 2.5-кратном снижении времени вывода.
Структура моделей
Фреймворк включает два типа моделей: чистые модели Mamba (Llamba) и гибридные модели (MambaInLlama). Llamba использует метод дистилляции MOHAWK, выравнивая матрицы, сопоставляя скрытые состояния и передавая веса. MambaInLlama сохраняет слои внимания Transformer, заменяя другие на слои Mamba, используя обратное KL-распределение для дистилляции.
Оценка и результаты
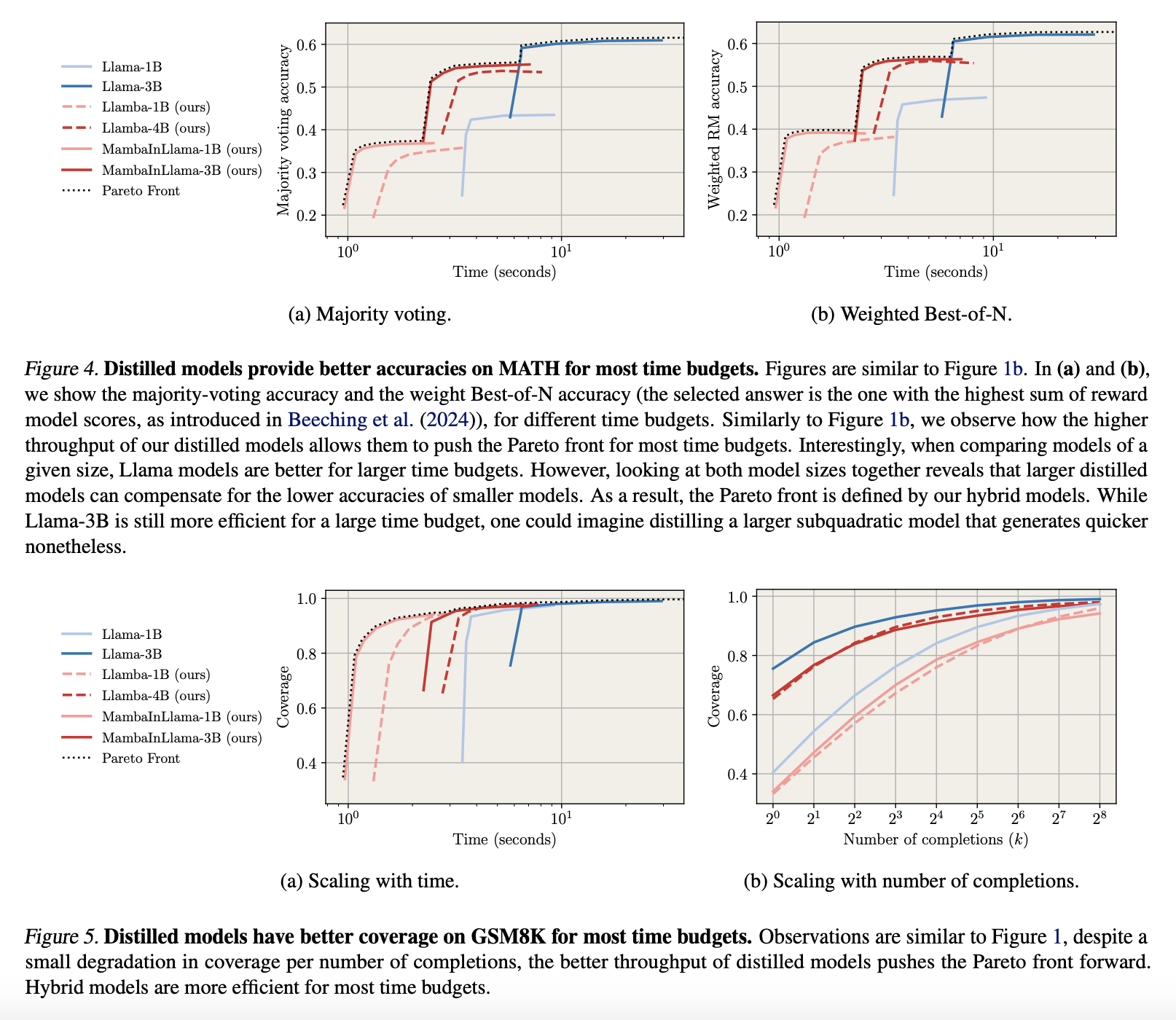
Исследователи оценили дистиллированные модели для генерации нескольких цепочек мысли (CoTs) при решении математических задач, сосредоточившись на сохранении инструкций. Они измеряли охват с помощью pass@k и оценивали точность через голосование большинством и выбор Best-of-N с моделью вознаграждения на основе Llama-3.1 8B. Результаты показали, что дистиллированные модели работают до 4.2 раза быстрее, чем модели Llama, сохраняя сопоставимый охват.
Выводы и будущее
В заключение, предложенные дистиллированные модели Mamba повысили эффективность рассуждений, сохранив точность и сократив время вывода и потребление памяти. Эти модели подходят для масштабируемого вывода и могут служить основой для будущих исследований в области обучения хороших моделей рассуждений и улучшения методов дистилляции.
Практические рекомендации
Изучите, как технологии искусственного интеллекта могут трансформировать ваш подход к работе. Найдите процессы, которые можно автоматизировать, и моменты взаимодействия с клиентами, где ИИ может добавить максимальную ценность. Определите ключевые показатели эффективности (KPI), чтобы убедиться, что ваши инвестиции в ИИ положительно сказываются на бизнесе.
Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ в своей работе. Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru.
Посмотрите практический пример решения на базе ИИ: бот для продаж от itinai.ru/aisales, предназначенный для автоматизации взаимодействий с клиентами круглосуточно и управления взаимодействиями на всех этапах клиентского пути.
«`



















