
Применение INT-FlashAttention для улучшения эффективности LLMs
Проблема с обработкой длинных последовательностей
Большие языковые модели (LLMs) сталкиваются с проблемой квадратичного роста сложности вычислений и использования памяти при увеличении длины последовательности. Это затрудняет масштабирование LLMs для приложений, требующих обработки длинных контекстов.
Решение: FlashAttention
FlashAttention ускоряет вычисления внимания и оптимизирует использование памяти, разделяя вычисления на более мелкие части, что позволяет эффективнее использовать память GPU. Это увеличивает масштабируемость механизма внимания, особенно для длинных последовательностей.
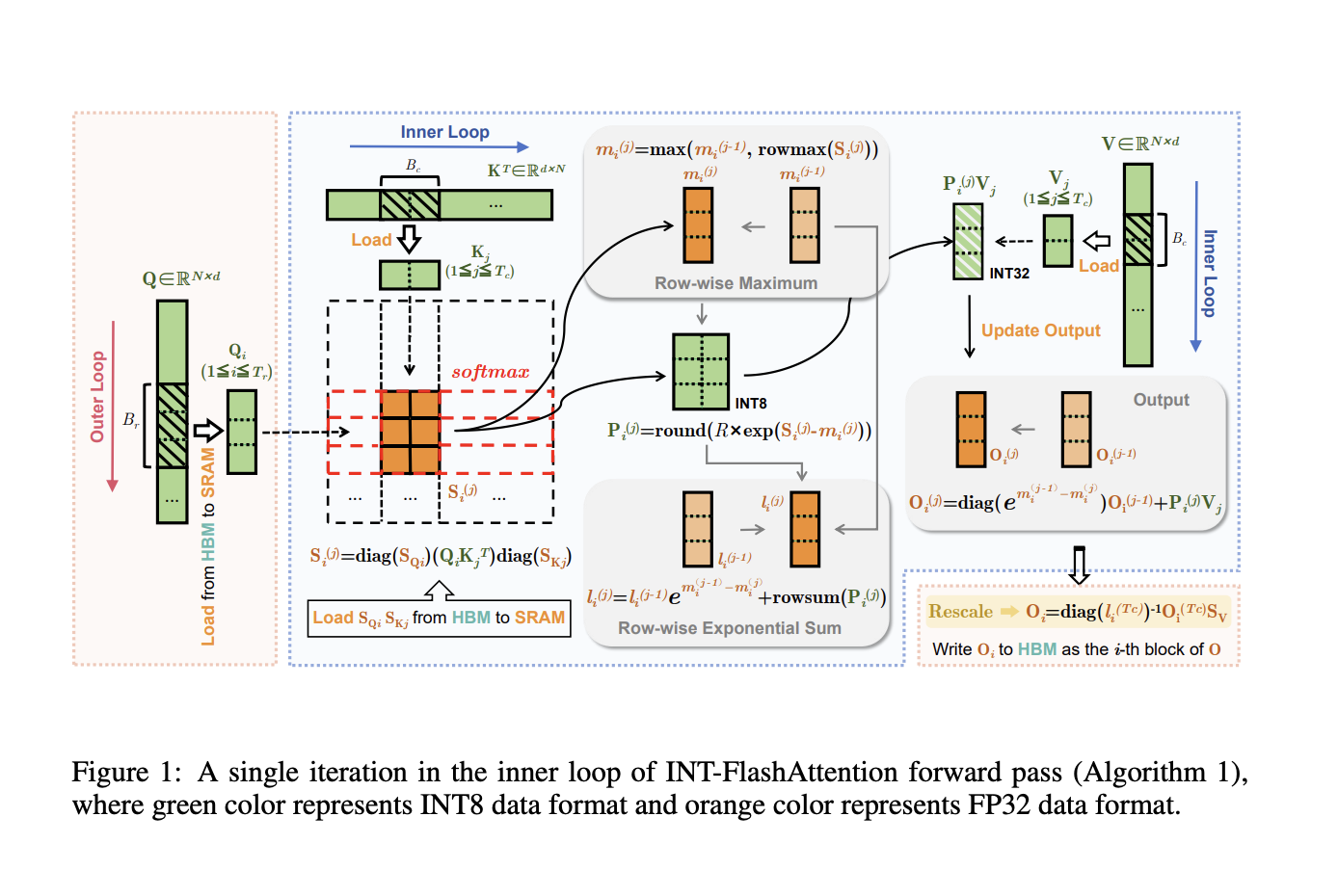
Квантование и INT-FlashAttention
Квантование вместе с FlashAttention позволяет использовать менее сложные числовые формы, такие как INT8, для ускорения обработки и снижения использования памяти. INT-FlashAttention интегрирует INT8 квантование с процессом FlashAttention, что значительно увеличивает скорость вывода и экономит энергию.
Преимущества INT-FlashAttention
INT-FlashAttention обрабатывает входные данные полностью в формате INT8, что позволяет сохранить точность при сниженной точности. Это увеличивает скорость вывода на 72% по сравнению с FP16 и уменьшает ошибку квантования на 82%, обеспечивая высокую точность.
Заключение
INT-FlashAttention значительно увеличивает эффективность LLMs на Ampere GPUs, обеспечивая быструю скорость вывода и точность. Это ключевой шаг к улучшению доступности высокопроизводительных LLMs для различных приложений.





















