
«`html
STARK: Новый бенчмарк для оценки систем поиска на базе текстовых и реляционных баз знаний
Представьте, что вы ищете идеальный подарок для своего ребенка – веселый и безопасный трехколесный велосипед, который соответствует всем требованиям. Вы можете задать запрос вроде «Помогите мне найти толкающий трехколесный велосипед от Radio Flyer, который будет веселым и безопасным для моего ребенка?» Звучит довольно конкретно, верно? Но что, если поисковая система могла бы понимать текстовые требования («веселый» и «безопасный для детей»), а также реляционный аспект («от Radio Flyer»)?
Практические решения и ценность
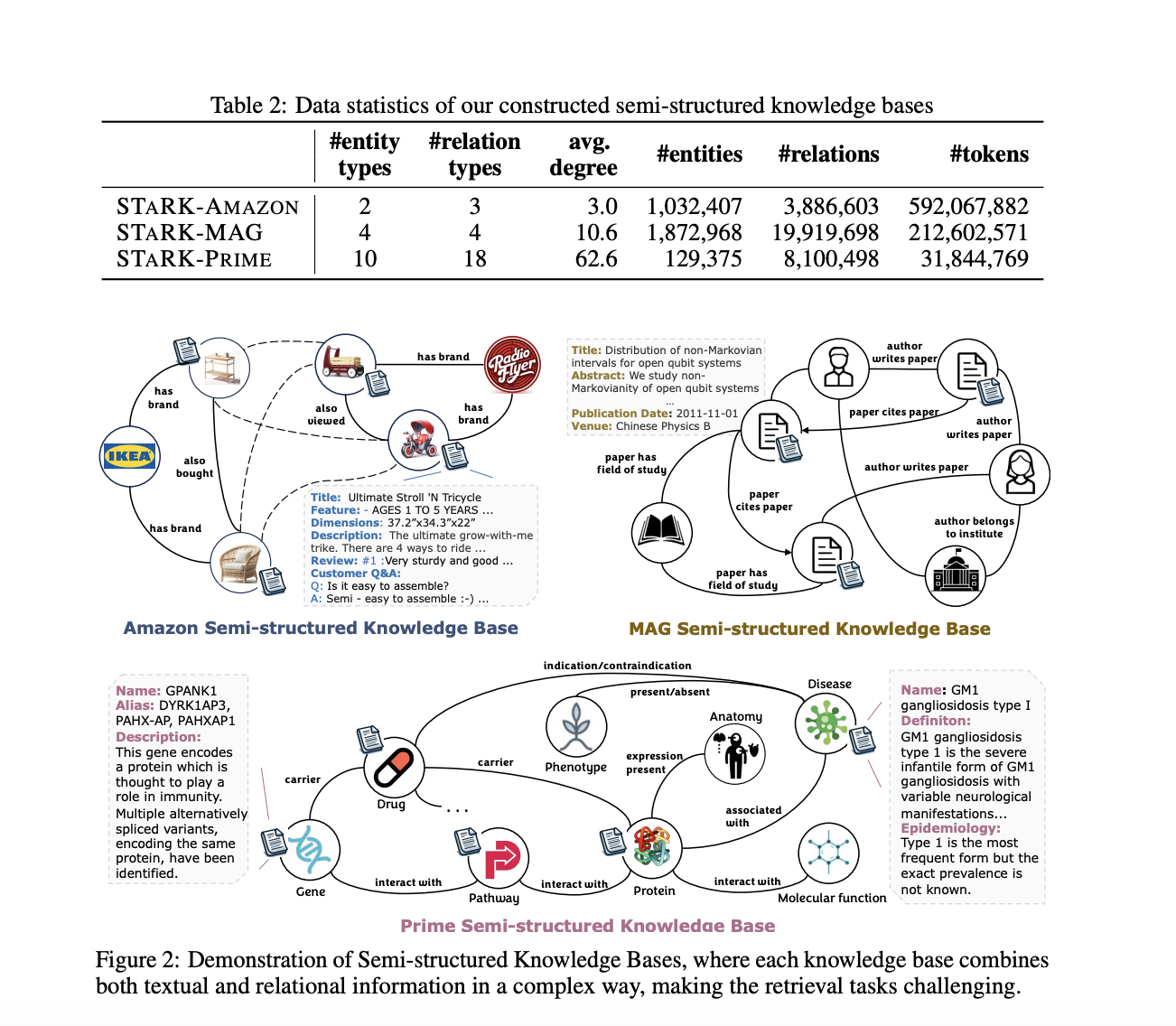
Это сложная задача мультимодального поиска, которую исследователи пытались решить с помощью STARK (Semi-structured Retrieval on Textual and Relational Knowledge Bases). Для создания бенчмарка они сначала построили три полуструктурированные базы знаний из общедоступных наборов данных: об одном о продуктах Amazon, об академических статьях и авторах, а также о биомедицинских сущностях, таких как болезни, лекарства и гены. Эти базы знаний содержали миллионы сущностей и связей между ними, а также текстовые описания для многих сущностей.
Далее они разработали новый пайплайн для автоматического создания запросов для своих бенчмарковых наборов данных. Пайплайн начинается с выборки реляционного требования, например «принадлежит бренду Radio Flyer» для продуктов. Затем извлекаются соответствующие текстовые свойства из сущности, удовлетворяющей это требование, например, описание велосипеда как «веселый и безопасный для детей.» Используя языковые модели, они объединяют реляционную и текстовую информацию в естественно звучащий запрос, например «Помогите мне найти толкающий трехколесный велосипед от Radio Flyer, который будет веселым и безопасным для моего ребенка?»
Они создают набор ответов на запросы, проверяя, удовлетворяют ли оставшиеся кандидаты сущностей (исключая ту, которая использовалась для извлечения текстовых свойств) все требования запроса с помощью нескольких языковых моделей. В финальный набор ответов попадают только сущности, прошедшие эту строгую проверку.
После генерации тысяч таких запросов по всем трем базам знаний и анализа распределения данных и оценки естественности, разнообразия и практичности запросов, исследователи обнаружили, что их бенчмарк охватывает широкий спектр стилей запросов и реальных сценариев.
При тестировании различных моделей поиска на бенчмарке STARK они обнаружили, что текущие подходы все еще испытывают трудности с точным извлечением соответствующих сущностей, особенно когда запросы включают рассуждения как о текстовой, так и о реляционной информации. Лучшие результаты были достигнуты путем комбинирования традиционных методов схожести векторов с языковыми моделями переранжировки, такими как GPT-4, но даже в этом случае производительность оставляла значительное пространство для улучшения. Традиционные методы векторизации лишены продвинутых рассуждений больших языковых моделей, а настройка LLM на эту задачу оказалась вычислительно сложной и трудной для согласования с текстовыми требованиями. На биомедицинском наборе данных, STARK-PRIME, лучший метод смог извлечь верный ответ на первом месте всего лишь в 18% случаев (измеряется метрикой Hit@1). Метрика Recall@20, оценивающая долю соответствующих элементов в топ-20 результатов, оставалась ниже 60% на всех наборах данных.
Исследователи подчеркивают, что STARK устанавливает новый бенчмарк для оценки систем поиска на базе структурированных баз знаний, предлагая ценные возможности для будущих исследований. Они предлагают, что снижение времени поиска и внедрение сильных рассуждающих способностей в процесс поиска являются перспективными направлениями для развития в этой области. Кроме того, они сделали свою работу открытой для общественности, способствуя дальнейшему изучению и развитию задач мультимодального поиска.
Ознакомьтесь с статьей. Вся заслуга за этим исследованием принадлежит ученым этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Применение искусственного интеллекта в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Researchers from Stanford and Amazon Developed STARK: A Large-Scale Semi-Structure Retrieval AI Benchmark on Textual and Relational Knowledge Bases.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
Релиз крупного бенчмарка поиска на базе LLM на полуструктурированных базах знаний
Если LLM превосходят в рассуждениях и семантическом поиске, они испытывают трудности с более сложными задачами. Особенно когда реальные пользовательские запросы требуют комбинации неструктурированных… twitter.com/ShirleyYXWu/status/112233445566778899
Исследователи из Стэнфорда и Amazon разработали STARK: крупный бенчмарк поиска на полуструктурированных базах знаний на текстовых и реляционных базах знаний.
Оригинальная статья опубликована на MarkTechPost.
«`





















