
Значение и практические решения для искусственного интеллекта
Искусственный интеллект оперирует большими массивами данных из глобальных интернет-ресурсов, таких как социальные сети, новостные источники и другие, чтобы обеспечивать алгоритмы, оказывающие влияние на множество аспектов современной жизни.
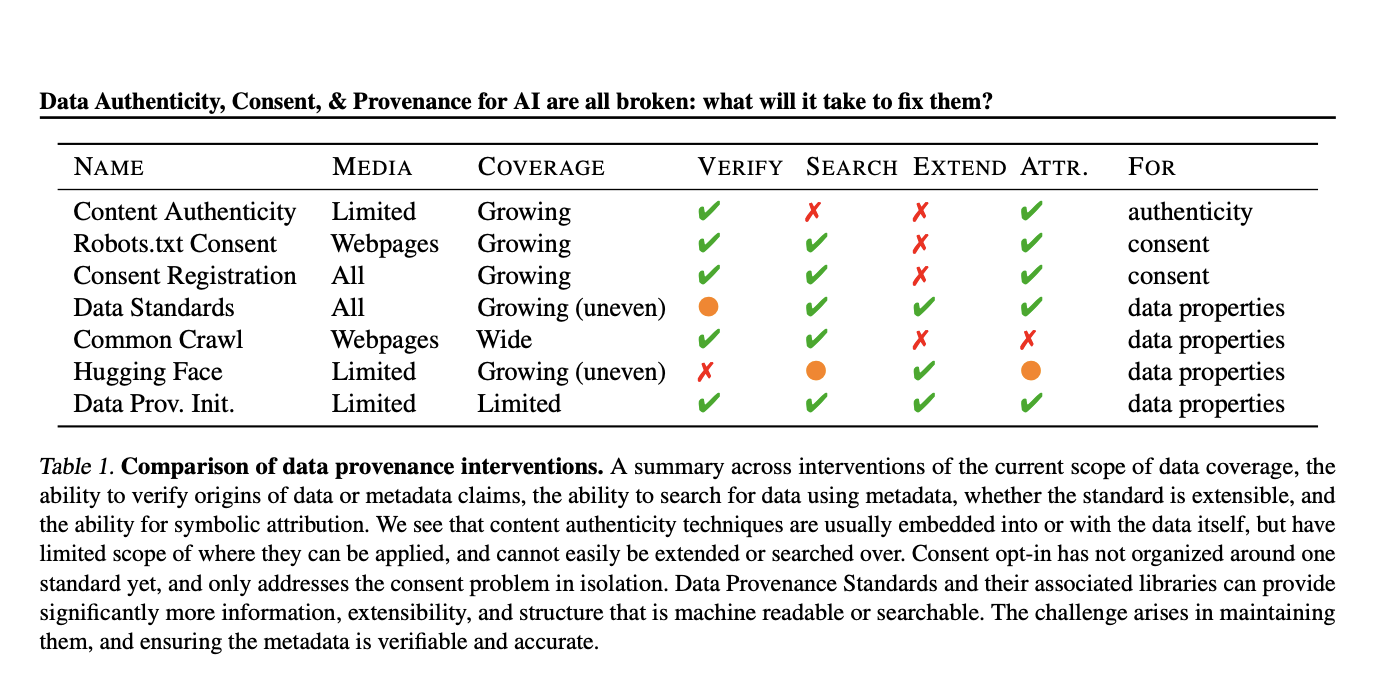
Тренировка и проблема данных
Тренировка генеративных моделей, таких как GPT-4, Gemini, Cluade и других, зависит от часто недостаточно задокументированных и проверенных данных. Наличие неструктурированных и малоописанных данных создает серьезные проблемы в поддержании целостности данных и этических стандартов.
Решение проблемы
Ученые из Медиа-лаборатории Массачусетского технологического института, Центра конструктивного общения МИТ и Гарвардского университета предлагают новый, стандартизированный подход к доказательствам происхождения данных. Эта система направлена на создание прозрачной среды, где разработчики искусственного интеллекта могут ответственно использовать данные, поддерживаемые четкими и проверяемыми механизмами согласия.
Эта работа доступна в формате PDF
Мы также доступны в социальных сетях: Твиттер, Телеграм, Дискорд, LinkedIn.
Подпишитесь на нашу рассылку, чтобы быть в курсе новостей.



















