
«`html
Искусственный интеллект (ИИ) и его практическое применение
Искусственный интеллект (ИИ) значительно продвинулся благодаря разработке крупных языковых моделей (LLM), которые следуют инструкциям пользователя. Эти модели направлены на предоставление точных и актуальных ответов на запросы человека, часто требующих настройки для улучшения их производительности в различных областях, таких как обслуживание клиентов, поиск информации и генерация контента. Возможность точно инструктировать эти модели стала основой современного ИИ, расширяя границы того, что эти системы могут достичь в практических сценариях.
Преодоление проблемы длинного ответа
Одной из проблем в разработке и оценке моделей, следующих за инструкциями, является врожденный длинный ответ. Этот биас возникает потому, что человеческие оценщики и алгоритмы обучения предпочитают длинные ответы, что приводит к созданию моделей, генерирующих излишне длинные выводы. Это предпочтение усложняет оценку качества модели и ее эффективности, поскольку длинные ответы иногда бывают более информативными или точными. Следовательно, вызов заключается в разработке моделей, способных понимать инструкции и генерировать ответы соответствующей длины.
Практические решения
Текущие методы для преодоления длинного ответа включают в себя внедрение штрафов за длину в оценочные бенчмарки. Например, AlpacaEval и MT-Bench интегрировали эти штрафы для компенсации склонности моделей к генерации длинных ответов. Кроме того, различные методы настройки, такие как обучение с подкреплением с обратной связью от человека (RLHF), используются для оптимизации моделей для лучшей возможности следовать инструкциям. Эти методы направлены на улучшение способности моделей генерировать краткие, но полные ответы, балансируя длину и качество вывода.
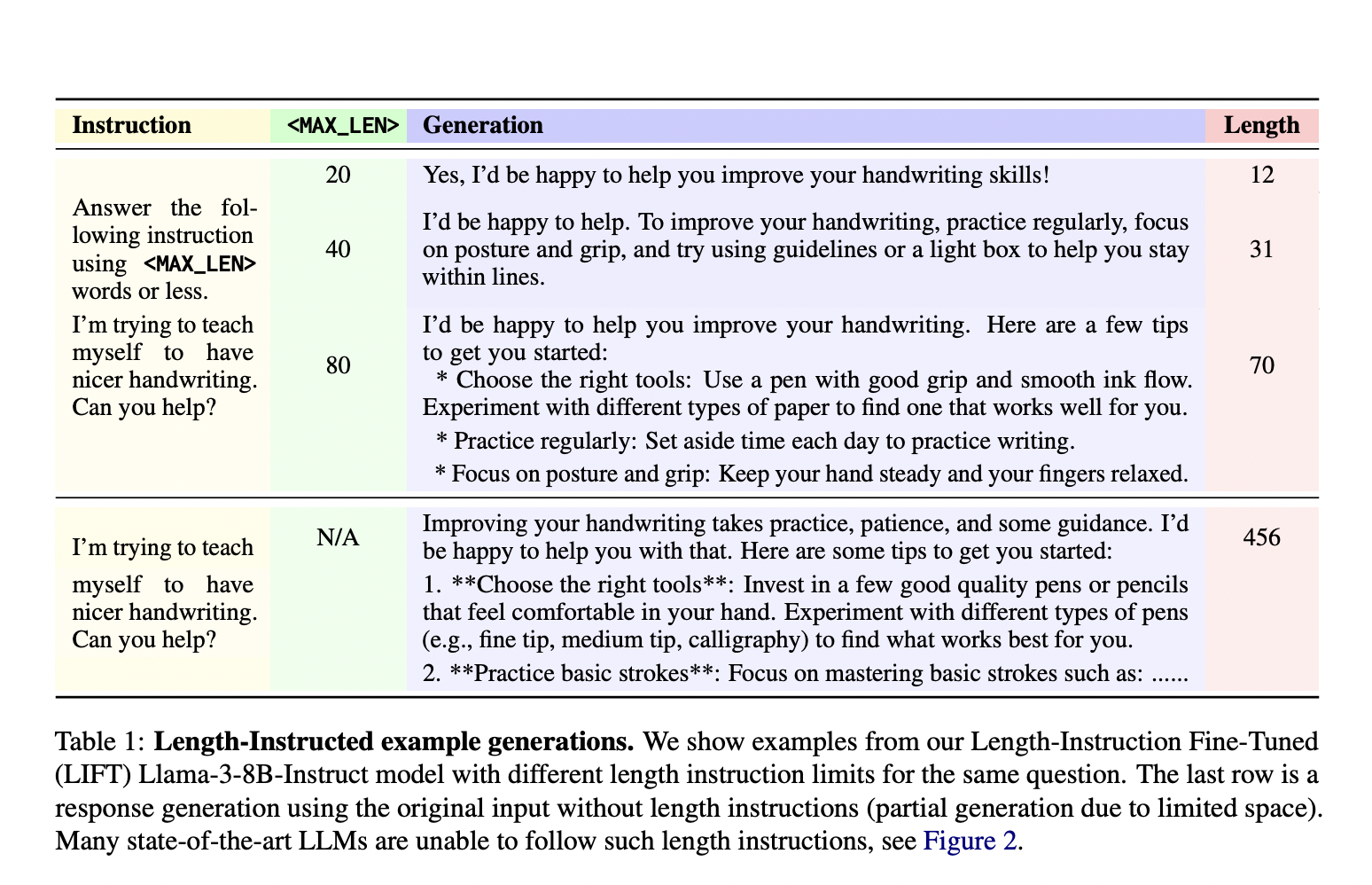
Исследователи из Meta FAIR и Нью-Йоркского университета представили новый подход под названием Length-Instruction Fine-Tuning (LIFT), который включает дополнение обучающих данных явными инструкциями по длине. Этот метод позволяет контролировать модели во время вывода, чтобы соблюдать заданные ограничения по длине. Команда исследователей, включая участников Meta FAIR и Нью-Йоркского университета, разработала этот подход для уменьшения длинного ответа и улучшения соблюдения моделями инструкций по длине. Модели учатся уважать эти ограничения в реальных приложениях, включая детальные инструкции в обучающие данные.
Метод LIFT включает в себя применение Direct Preference Optimization (DPO) для настройки моделей с использованием обогащенных инструкциями по длине наборов данных. Этот процесс начинается с дополнения обычного набора данных, следующего за инструкциями, добавлением ограничений длины в подсказки. Метод создает пары предпочтений, отражающие как ограничения длины, так и качество ответа. Эти дополненные наборы данных затем используются для настройки моделей, таких как Llama 2 и Llama 3, обеспечивая их способность обрабатывать запросы с и без инструкций по длине. Этот систематический подход позволяет моделям учиться на различных инструкциях, улучшая их способность генерировать точные и адекватно краткие ответы.
Предложенные модели LIFT-DPO продемонстрировали превосходную производительность в соблюдении ограничений длины по сравнению с существующими передовыми моделями, такими как GPT-4 и Llama 3. Например, исследователи обнаружили, что модель GPT-4 Turbo нарушала ограничения длины почти в 50% случаев, выявляя значительный недостаток в ее конструкции. В отличие от этого, модели LIFT-DPO проявили существенно более низкие уровни нарушений. В частности, модель Llama-2-70B-Base, подвергнутая стандартному обучению DPO, показала уровень нарушений 65.8% на AlpacaEval-LI, который драматически снизился до 7.1% при обучении LIFT-DPO. Аналогично, уровень нарушений модели Llama-2-70B-Chat уменьшился с 15.1% при стандартном DPO до 2.7% при LIFT-DPO, демонстрируя эффективность метода в контроле длины ответа.
Более того, модели LIFT-DPO сохраняли высокое качество ответов, соблюдая ограничения по длине. Уровень побед значительно улучшился, указывая на то, что модели могут генерировать высококачественные ответы в рамках указанных ограничений по длине. Например, уровень побед для модели Llama-2-70B-Base увеличился с 4.6% при стандартном DPO до 13.6% при LIFT-DPO. Эти результаты подчеркивают успех метода в балансировании контроля длины и качества ответа, обеспечивая надежное решение для оценки, связанной с длинным ответом.
Выводы и рекомендации
Исследование решает проблему длинного ответа в моделях, следующих за инструкциями, представляя метод LIFT. Этот подход улучшает управляемость и качество ответов модели путем включения ограничений по длине в процесс обучения. Результаты указывают на то, что модели LIFT-DPO превосходят традиционные методы, предоставляя более надежное и эффективное решение для следования инструкциям с ограничением по длине. Сотрудничество между Meta FAIR и Нью-Йоркским университетом значительно улучшило разработку моделей ИИ, способных генерировать краткие ответы высокого качества, устанавливая новый стандарт для возможностей следования инструкциям в исследованиях по ИИ.
Подробнее о статье можно узнать здесь. Вся заслуга за это исследование принадлежит исследователям проекта. Также не забудьте следить за нами в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вы полюбите нашу рассылку новостей.
Не забудьте присоединиться к нашему сообществу более чем 46 000 специалистов по машинному обучению на Reddit.
Статья была опубликована на портале MarkTechPost.
«`



















