
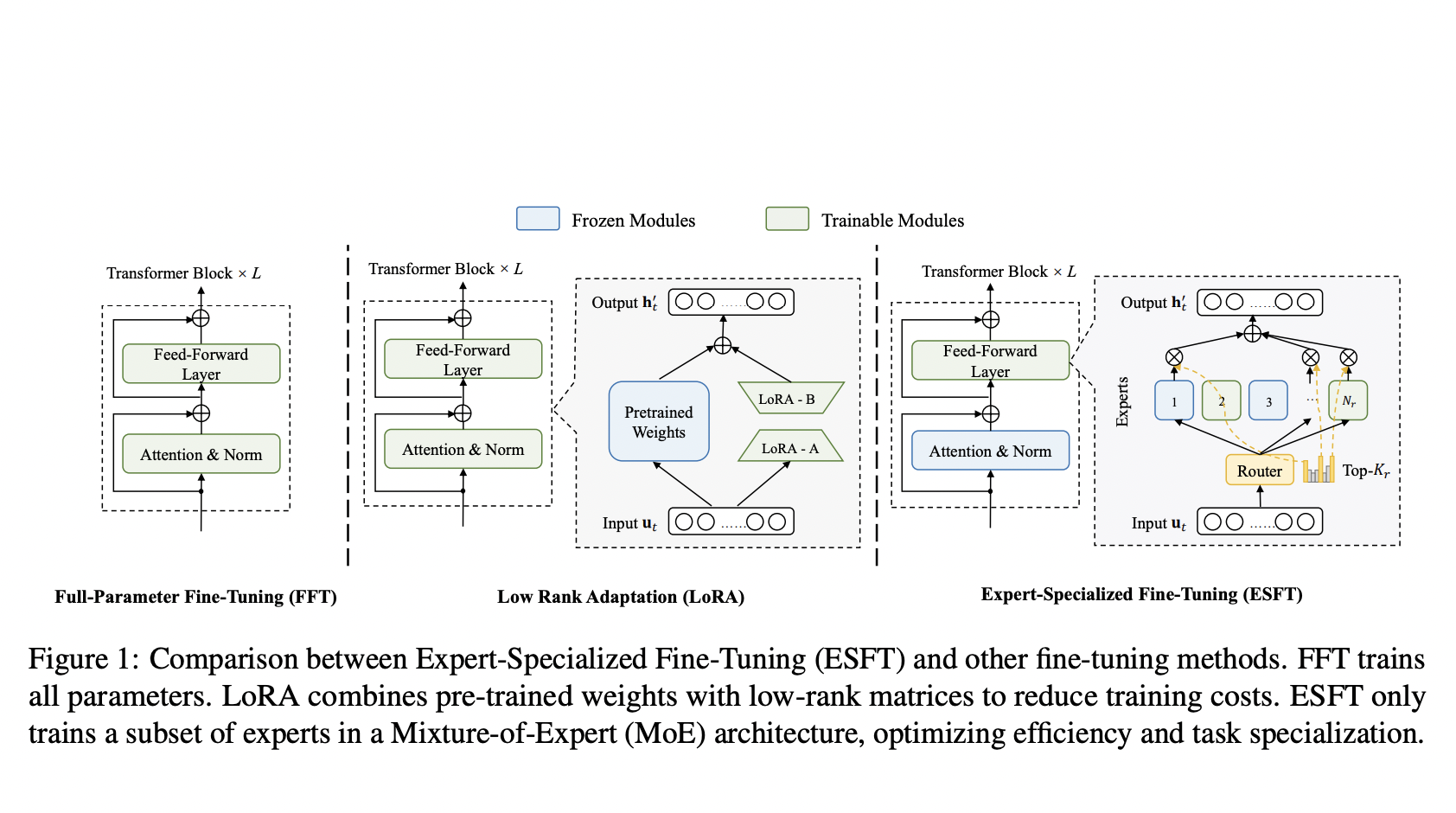
«`html
Эксперты DeepSeek AI предлагают метод ESFT для снижения использования памяти на 90% и времени на 30%
Обработка естественного языка развивается быстро, с акцентом на оптимизацию крупных языковых моделей (LLM) для конкретных задач. Цель — разработать эффективные методы для настройки этих моделей на конкретные задачи без излишних вычислительных затрат.
Проблема настройки LLM
Одна из основных проблем — ресурсоемкость настройки LLM для конкретных задач. Традиционные методы обновляют все параметры модели, что приводит к высоким вычислительным затратам и переобучению. Для оптимизации производительности при управлении вычислительной нагрузкой требуются более эффективные методы настройки.
Метод ESFT
DeepSeek AI и исследователи Университета Нортвестерн предложили новый метод под названием Expert-Specialized Fine-Tuning (ESFT) для LLM с разреженной архитектурой, особенно с использованием архитектуры mixture-of-experts (MoE). Этот метод позволяет настраивать только наиболее релевантных экспертов для конкретной задачи, что повышает эффективность настройки и сохраняет специализацию экспертов.
ESFT значительно снижает вычислительные затраты на настройку, уменьшая требования к хранилищу на 90% и время обучения на 30% по сравнению с полной настройкой параметров. При этом ESFT не уступает в общей производительности модели, как показывают экспериментальные результаты.
Применение метода
ESFT превзошел традиционные методы настройки в различных задачах, таких как математика и кодирование. Способность эффективно настраивать подмножество экспертов, выбранных на основе их релевантности для задачи, подчеркивает его эффективность. ESFT сохраняет общую производительность задач лучше, чем другие методы настройки LLM, делая его мощным инструментом для настройки крупных языковых моделей.
Заключение
ESFT представляет собой перспективный подход для развития настройки крупных языковых моделей, обеспечивая оптимальные результаты при снижении вычислительных затрат. Этот метод использует специализированную архитектуру разреженных LLM для достижения выдающихся результатов с уменьшенными вычислительными затратами.
Подробнее ознакомиться с работой можно в Paper и на GitHub.
Вся заслуга за это исследование принадлежит исследователям проекта. Также не забудьте следить за нами в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наша newsletter.
Не забудьте присоединиться к нашему сообществу в Reddit.
Источник: MarkTechPost
«`




















