
«`html
Retrieval-augmented generation (RAG) в обработке естественного языка
Техника retrieval-augmented generation (RAG) улучшает эффективность больших языковых моделей (LLM) в обработке обширных объемов текста. Она критически важна для задач обработки естественного языка, особенно в приложениях вроде вопросно-ответной системы, где сохранение контекста информации имеет решающее значение для генерации точных ответов.
Проблема существующих LLM
Одной из основных проблем существующих LLM является их сложность в управлении длинными контекстами. При увеличении длины контекста модели нуждаются в помощи для поддержания четкой фокусировки на актуальной информации, что может привести к существенному снижению качества их ответов. Эта проблема особенно заметна в задачах вопросно-ответной системы, где важна точность. Модели могут быть перегружены объемом информации, что приводит к извлечению нерелевантных данных и разбавлению точности ответов.
Описание метода OP-RAG
Исследователи из NVIDIA предложили метод order-preserve retrieval-augmented generation (OP-RAG) для решения этих проблем. OP-RAG заметно улучшает традиционные методы RAG за счет сохранения порядка текстовых фрагментов, извлекаемых для обработки. В отличие от существующих систем RAG, которые определяют приоритеты фрагментов на основе оценок релевантности, механизм OP-RAG сохраняет исходную последовательность текста, обеспечивая сохранение контекста и связности в процессе извлечения.
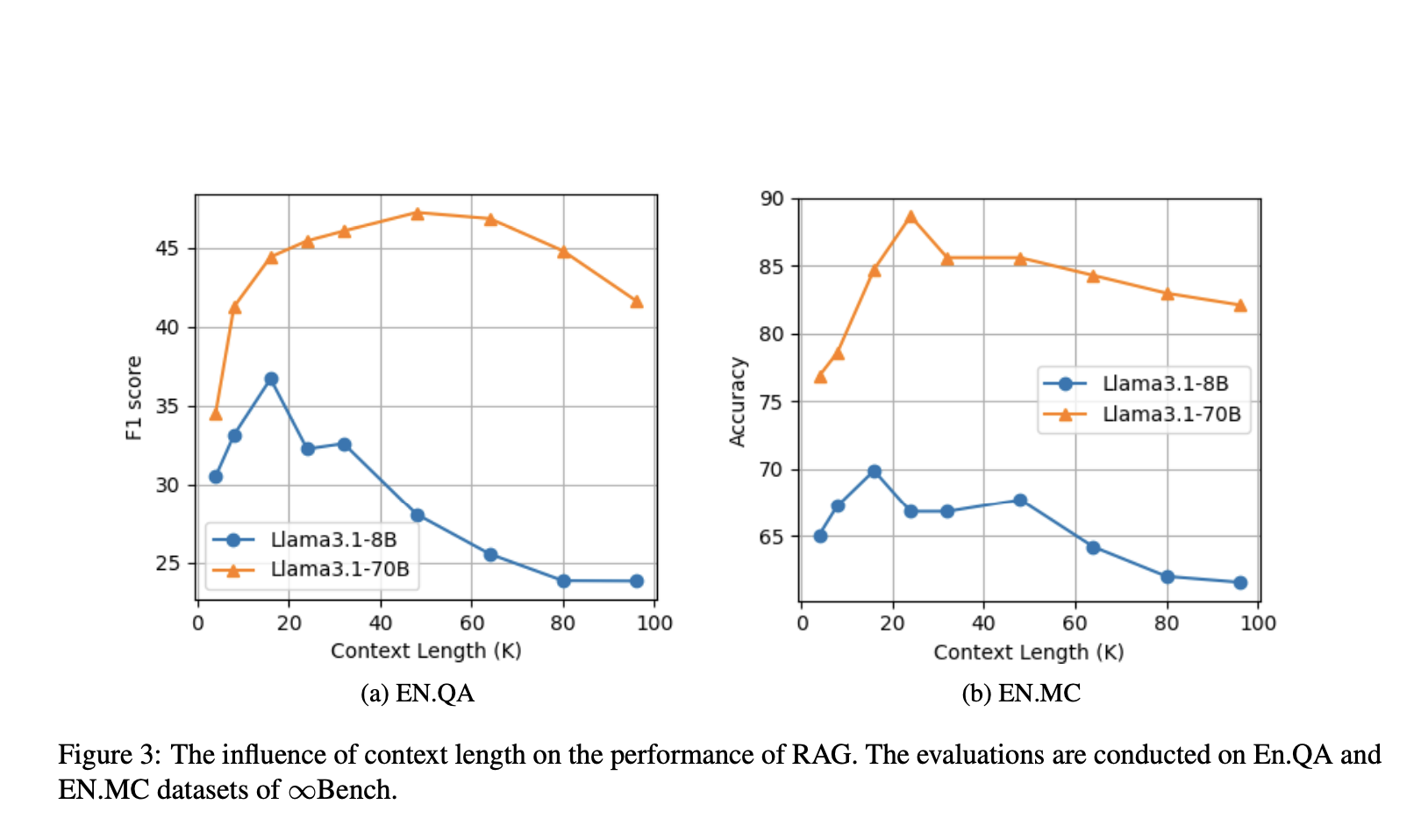
Результаты и преимущества
OP-RAG демонстрирует значительное улучшение качества генерации ответов, особенно в ситуациях с длинным контекстом, где важна связность. Метод был тщательно протестирован на публичных наборах данных и показал заметное улучшение как по точности, так и по эффективности по сравнению с традиционными длинно-контекстными LLM без RAG.
В заключение, OP-RAG представляет собой значительный прорыв в области retrieval-augmented generation, предлагая решение ограничений длинно-контекстных LLM. Путем сохранения порядка извлеченных текстовых фрагментов этот метод позволяет более связанную и контекстуально релевантную генерацию ответов, даже в задачах вопросно-ответной системы с обширными текстовыми данными.
Подробнее о работе вы можете прочитать в этом документе. Вся кредит за исследование принадлежит исследователям данного проекта.
«`





















