
«`html
µFormer: A Deep Learning Framework for Efficient Protein Fitness Prediction and Optimization
Инженерный белок необходим для разработки белков с определенными функциями, но сложный ландшафт фитнеса мутации белка представляет существенные трудности при поиске оптимальных последовательностей. Аналитика нулевого подхода, который предсказывает мутационные эффекты без использования гомологов или множественных выравниваний последовательностей (MSA), уменьшает некоторые зависимости, но недостаточно предсказывает различные свойства белка.
Решение
Microsoft Research AI for Science представил µFormer, глубокую систему обучения, которая интегрирует предварительно обученную языковую модель белка с специализированными модулями оценки для предсказания мутационных эффектов белка. µFormer предсказывает высокоуровневые мутанты, моделирует эпистатические взаимодействия и обрабатывает вставки. С помощью обучения с подкреплением µFormer эффективно исследует обширные мутационные пространства для проектирования улучшенных вариантов белков. Модель предсказала мутантов с увеличением скорости роста бактерий в 2000 раз, вызванное улучшенной ферментативной активностью. Успех µFormer простирается на сложные сценарии, включая многоточечные мутации, и его прогнозы подтверждены сухопольными экспериментами, что подчеркивает его потенциал для оптимизации дизайна белков.
Преимущества
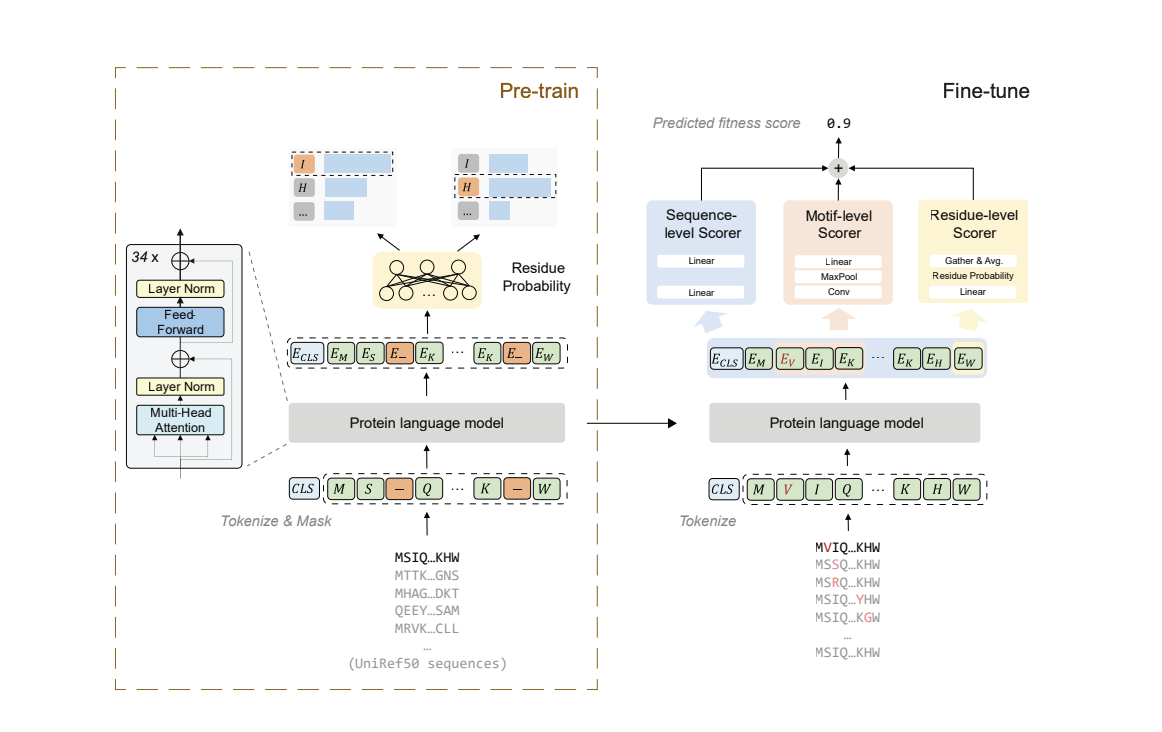
Модель µFormer предназначена для предсказания приспособленности мутированных последовательностей белков. Она работает в два этапа: сначала путем предварительного обучения маскированной языковой модели белка (PLM) на большом наборе неразмеченных последовательностей белка, а затем путем прогнозирования оценок приспособленности с использованием трех интегрированных в предварительно обученную модель модулей оценки. Эти модули — уровень остатков, уровень мотивов и уровень последовательностей — воспринимают различные аспекты последовательности белка и объединяют свои выводы для генерации окончательной оценки приспособленности. Модель обучается с использованием известных данных о приспособленности, минимизируя ошибки между предсказанными и фактическими оценками.
Заключение
Ранее проведенные исследования показали потенциал моделей языка, основанных на последовательности белка, в задачах, таких как предсказание функции фермента и разработка антител. Модель µFormer, основанная на последовательности с тремя модулями оценки, была разработана для обобщения различных свойств белков. Она достигла передовых показателей в задачах предсказания приспособленности, включая сложные мутации и эпистас. µFormer также продемонстрировала способность оптимизировать активность фермента, особенно в прогнозировании вариантов TEM-1 против цефотаксима. Несмотря на свой успех, улучшения могут быть внесены путем включения структурных данных, разработки моделей с учетом фенотипа и создания моделей, способных обрабатывать более длинные последовательности белков для достижения лучшей точности.
Проверьте статью. Все заслуги за это исследование принадлежат его исследователям. Также не забудьте подписаться на наши аккаунты в Twitter и LinkedIn. Присоединяйтесь к нашему каналу в Telegram.
Если вам нравится наша работа, вам понравится наша рассылка.
«`




















