
«`html
Большие языковые модели (LLM) в области извлечения информации
Большие языковые модели (LLM) сделали значительные успехи в области извлечения информации (IE). Извлечение информации — это задача в обработке естественного языка (NLP), которая включает в себя идентификацию и извлечение конкретных фрагментов информации из текста. LLM продемонстрировали великолепные результаты в области IE, особенно при совмещении с инструкционной настройкой. Через инструкционную настройку эти модели обучаются аннотировать текст в соответствии с предварительно определенными стандартами, что улучшает их способность обобщения на новые наборы данных. Это указывает на то, что даже с неизвестными данными люди могут успешно выполнять задачи IE, следуя инструкциям.
Трудности LLM в работе с языками с ограниченными ресурсами
Однако, даже с этими улучшениями, LLM по-прежнему сталкиваются с многими трудностями при работе с языками с ограниченными ресурсами. Эти языки лишены как неразмеченного текста, необходимого для предварительного обучения, так и размеченных данных, необходимых для настройки моделей. Из-за отсутствия данных для LLM сложно достичь хорошей производительности в этих языках.
TransFusion: решение для преодоления трудностей
Для преодоления этой проблемы команда исследователей из Института технологии Джорджии представила фреймворк TransFusion. В TransFusion модели настраиваются на работу с данными, переведенными из языков с ограниченными ресурсами на английский. С помощью этого метода оригинальный текст на языке с ограниченными ресурсами и его английский перевод обеспечивают информацию, которую модели могут использовать для создания более точных прогнозов.
Этапы реализации TransFusion
Фреймворк включает три основных этапа:
- Перевод в процессе вывода: преобразование данных на языке с ограниченными ресурсами на английский, чтобы модель с ограниченными ресурсами могла проаннотировать их.
- Слияние аннотированных данных: в модели, обученной использовать оба типа данных, слияние оригинального текста на языке с ограниченными ресурсами с аннотированными английскими переводами.
- Создание цепочки рассуждения TransFusion, которая интегрирует как аннотацию, так и слияние в один проход авторегрессивного декодирования.
GoLLIE-TF и улучшение производительности
Команда также представила GoLLIE-TF — инструкционно настроенную LLM, специально предназначенную для задач интернет-эксплорера. Цель TransFusion и GoLLIE-TF состоит в увеличении эффективности LLM при работе с языками с ограниченными ресурсами.
Результаты экспериментов
Эксперименты на двенадцати многоязычных наборах данных по извлечению информации, включающих пятьдесят языков, показали, что GoLLIE-TF работает хорошо. В сравнении с базовой моделью результаты демонстрируют, что GoLLIE-TF обладает более эффективным нулевым переносом через языки без дополнительных данных для обучения, что позволяет ему более эффективно применять свои умения к новым языкам.
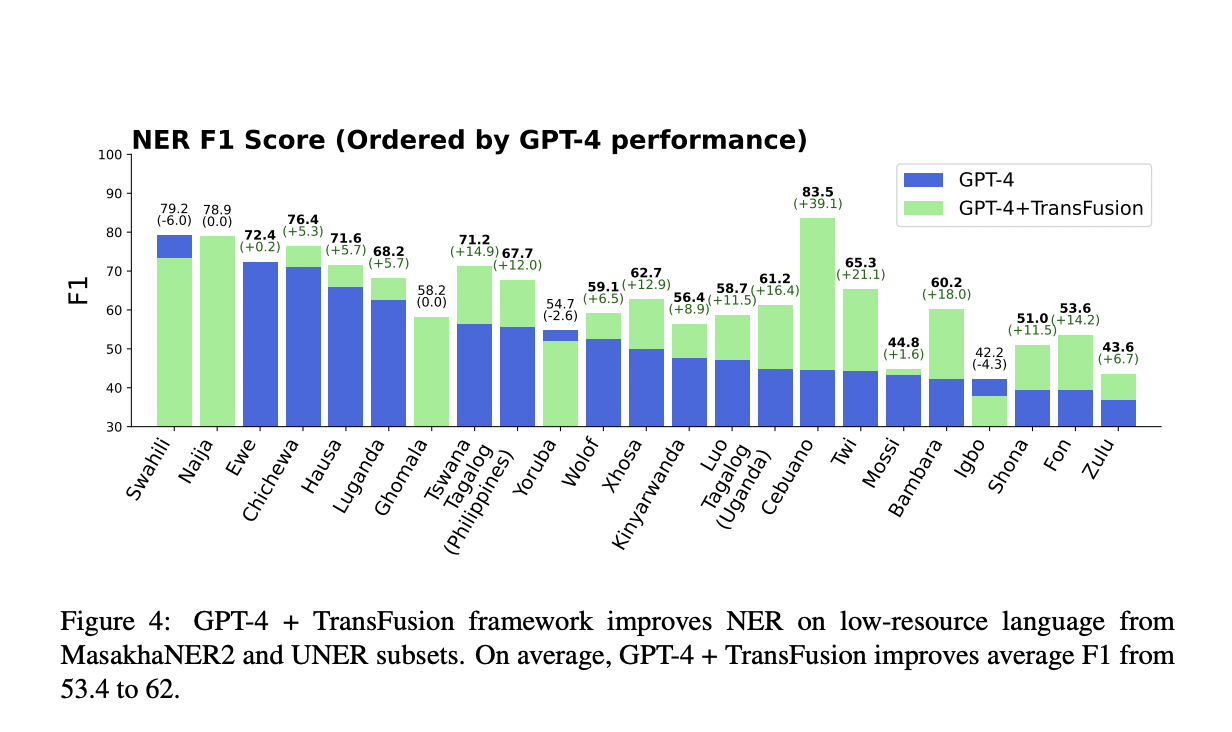
Практическое применение TransFusion
Применение TransFusion к собственным моделям, таким как GPT-4, значительно улучшает производительность распознавания именованных сущностей (NER) в языках с ограниченными ресурсами. Использование запросов привело к увеличению производительности GPT-4 на 5 F1-пунктов. Дополнительные улучшения были получены путем настройки различных типов языковых моделей с использованием фреймворка TransFusion: архитектуры только декодеров улучшились на 14 F1-пунктов, в то время как архитектуры только кодировщиков улучшились на 13 F1-пунктов.
Заключение
TransFusion и GoLLIE-TF вместе предоставляют мощное решение для улучшения задач IE в языках с ограниченными ресурсами. Это показывает значительные улучшения по многим моделям и наборам данных, помогая уменьшить разрыв в производительности между языками с высокими и ограниченными ресурсами путем использования английских переводов и настройки моделей для слияния аннотаций.
Подробнее о работе можно узнать в статье. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится и наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit с 45 тыс. подписчиков.
«`


















