
«`html
Оценка возможностей извлечения и рассуждения больших языковых моделей (LLM) в крайне длинных контекстах, расширяющихся до 1 миллиона токенов
Эффективная обработка длинных текстов критически важна для извлечения актуальной информации и принятия точных решений на основе обширных данных.
Текущие методы оценки возможностей LLM в длинных контекстах
Существующие методы оценки LLM в длинных контекстах имеют ограничения, такие как недостаточная оценка LLM на уровне 1 миллиона токенов и фокус на отдельных задачах извлечения.
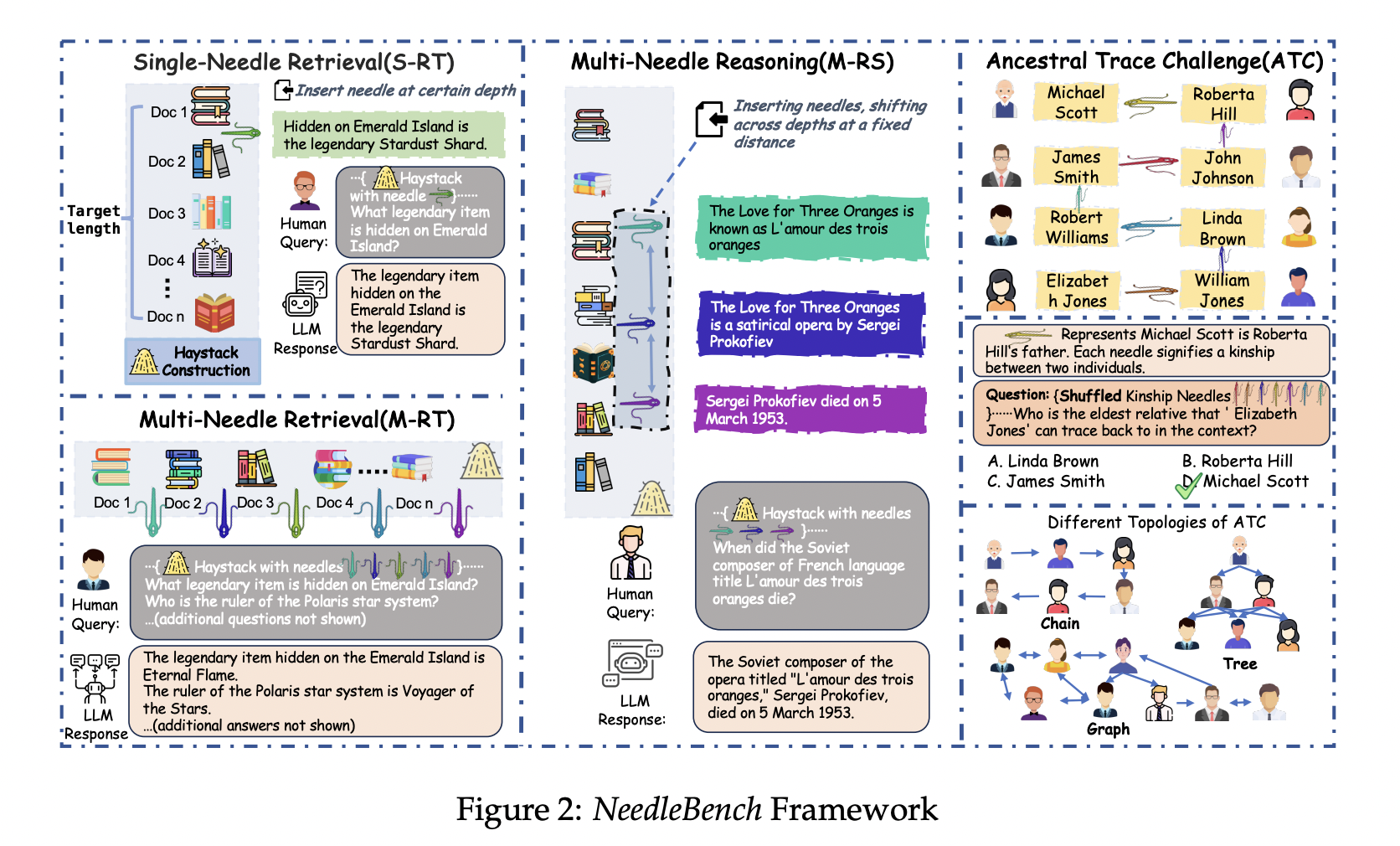
NeedleBench: новый подход к оценке возможностей LLM
NeedleBench представляет собой новую систему оценки возможностей LLM в длинных контекстах, включающую задачи извлечения и рассуждения на различных уровнях длины текста.
Результаты и применение
Результаты оценки показывают значительный потенциал для улучшения практического применения LLM в длинных контекстах. Это открывает новые возможности для применения ИИ в реальных сценариях с длинными текстами.
Подробнее ознакомиться с исследованием можно здесь.
Подписывайтесь на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
«`





















