
«`html
Large Language Models (LLMs) and the Challenges of KV Cache Memory
Большие модели языков (LLM) с расширенными окнами контекста показали выдающийся потенциал в решении сложных задач, таких как длительные разговоры, суммирование документов и отладка кода. Однако их применение сталкивается с значительными препятствиями, в основном из-за огромного потребления памяти механизмом KV Cache. Эта проблема особенно ощутима в условиях аппаратного обеспечения с фиксированной памятью. Например, модель с 7 миллиардами параметров при скромном размере входной партии и длине последовательности может потребовать 64 ГБ памяти для KV Cache, что значительно превышает объем памяти, необходимый для самих весов модели. Эта узкое место памяти серьезно ограничивает практическое применение LLM в условиях ограниченных ресурсов.
Решения для преодоления проблемы
Исследователи разработали различные методы для решения проблемы памяти KV Cache в LLM. Подходы такие как H2O и Scissorhands исследуют разреженность в блоках внимания трансформатора для удаления ненужных токенов. Другие техники включают механизмы выбора обучаемых токенов и изменения структур внимания. Эффективные трансформеры нацелены на уменьшение сложности самовнимания с использованием методов, таких как дилатационные скользящие окна или комбинированные типы внимания. Исследование экстраполяции длины фокусируется на адаптации позиционных вложений для расширенных окон контекста. Однако эффективность этих методов в задачах реального мира с длинным контекстом может быть переоценена, если оценивать их только по метрикам, таким как перплексия.
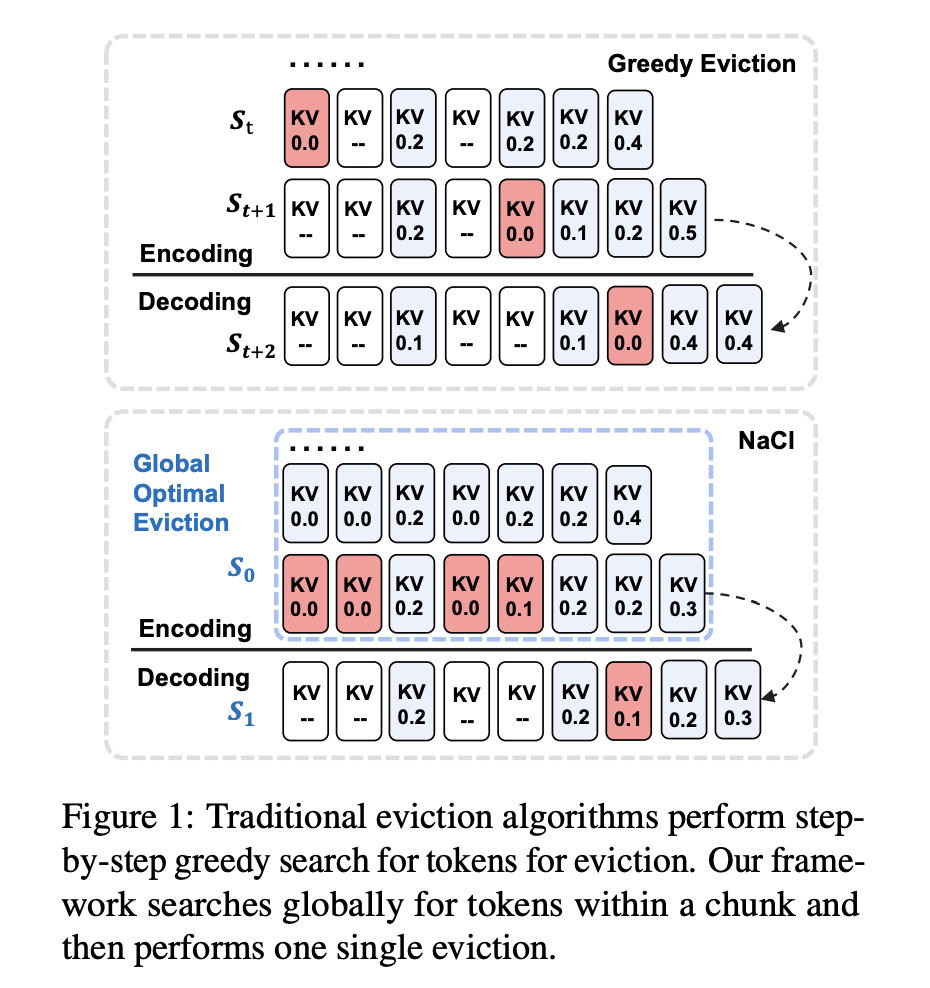
Исследователи из Института информационной инженерии, Китайской академии наук, Школы кибербезопасности, Университета Китайской академии наук и компании Baidu Inc. представляют NACL — уникальную среду вытеснения кэша KV для LLM, фокусирующуюся на фазе кодирования, а не генерации. Он реализует одноразовый процесс вытеснения по всему входу, постепенно очищая слои кэша KV. Особенностью является вытеснение PROXY-TOKENS, использующее глобальную статистику относительно задачи для значимых прокси-токенов, обычно найденных во входах вопросов в конце длинных текстов. Этот подход преодолевает проблемы смещения внимания, видимые в методах, использующих локальную статистику или нерелевантные прокси-токены. NACL нацелен на улучшение производительности моделирования длинного контекста, эффективно управляя ограничениями памяти в LLM.
Эффективное реализация алгоритма вытеснения кэша KV
NACL представляет собой гибридную политику вытеснения кэша KV, объединяющую вытеснение PROXY-TOKENS и RANDOM EVICTION. PROXY-TOKENS EVICTION идентифицирует подмножество прокси-токенов во входных данных, точно оценивающих важность токенов. Функция оценки агрегирует оценки внимания от этих прокси-токенов, уменьшая смещение и улучшая качество вытеснения. RANDOM EVICTION включает случайность в процесс вытеснения, улучшая надежность. Он строит вероятностное распределение на основе значимости токенов и случайным образом выбирает из него. Этот подход помогает сохранять важную информацию, которая иначе могла бы быть потеряна из-за смещения внимания.
NACL объединяет эти методы, применяя эффективную стратегию однократного вытеснения в рамках общего бюджета кэша KV. Гибридный подход балансирует точную оценку важности токенов с случайностью для улучшения производительности в задачах с длинными текстами. Метод совместим с эффективными механизмами внимания, такими как FlashAttention-2, минимизируя память и вычислительные затраты для применения в условиях ограниченных ресурсов.
Результаты и преимущества NACL
NACL демонстрирует впечатляющую производительность как в случае коротких, так и длинных текстов, управляя кэшем KV в условиях ограниченной памяти. В коротких текстовых бенчмарках NACL почти сравнялся с производительностью полного кэша, достигнув среднего показателя в 63,8% в настройках 5-shot по сравнению с 64,6% у полного кэша. Он значительно превзошел H2O на 3,5 процентных пункта. Даже в более сложных настройках 25-shot NACL проявляет устойчивость, поддерживая уровни производительности, близкие к или сравнимые с настройками полного кэша на некоторых наборах данных. Для задач с длинными текстами NACL достигает уменьшения использования памяти на 80% при всего лишь 0,7 процентного понижения средней точности. Он может обеспечить в 3 раза большее уменьшение кэша KV, сохраняя при этом сопоставимую производительность с базовыми данными. NACL показывает стабильную производительность при различных бюджетных настройках, даже превосходя производительность полного кэша в некоторых задачах, таких как HotpotQA и QMSum.
Эффективность NACL особенно проявляется в сохранении ключевой информации в длинных входных данных, превосходя методы, такие как H2O и MSRNN, страдающие от смещения внимания. Это демонстрирует устойчивую способность NACL обрабатывать сложные длинные тексты при эффективном управлении ограничениями памяти.
NACL: робустный алгоритм вытеснения кэша KV для эффективной обработки длинных текстов в LLM
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте NACL: A Robust KV Cache Eviction Framework for Efficient Long-Text Processing in LLMs.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















