
«`html
Итеративная оптимизация предпочтений для улучшения задач рассуждения в языковых моделях
Итеративные методы выравнивания включают как стратегии с участием человека, так и автоматизированные подходы. Некоторые полагаются на обратную связь человека для обучения с подкреплением (RLHF), в то время как другие, такие как Итеративная DPO, оптимизируют пары предпочтений автономно, генерируя новые пары для последующих итераций с использованием обновленных моделей. SPIN, вариант Итеративной DPO, использует метки человека и генерации модели для построения предпочтений, но сталкивается с ограничениями, когда производительность модели соответствует стандартам человека. Self-Rewarding LLMs также используют Итеративную DPO, при этом сама модель выступает в качестве оценщика вознаграждения, что приводит к улучшению следования инструкциям, но скромным улучшениям в рассуждениях. В отличие от этого, Expert Iteration и STaR фокусируются на отбор образцов и улучшение обучающих данных, отходя от оптимизации парных предпочтений.
Практическое применение:
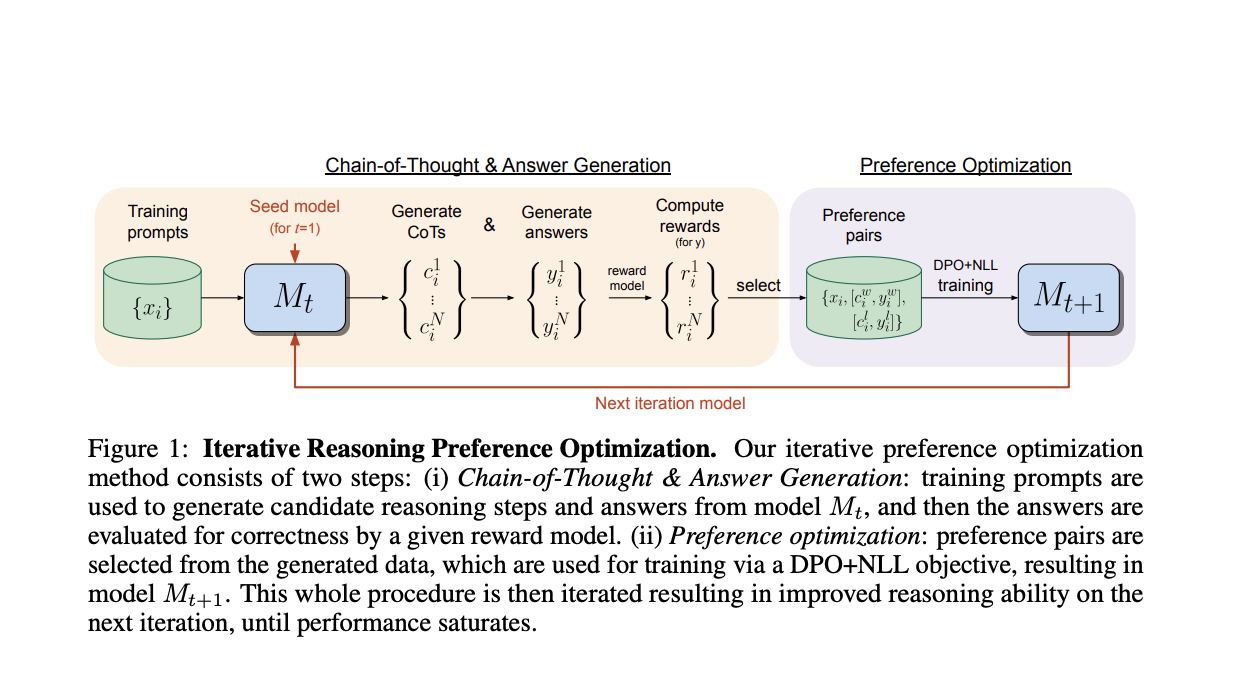
Исследователи из FAIR в Meta и Нью-Йоркского университета представляют подход, нацеленный на итеративную оптимизацию предпочтений для задач рассуждения, в частности, цепочечного рассуждения (CoT). Каждая итерация включает в себя выбор нескольких шагов рассуждения CoT и окончательных ответов, конструирование пар предпочтений, где победители обладают правильными ответами, а проигравшие — неправильными. Обучение включает в себя вариант DPO, включающий потерю отрицательного логарифма правдоподобия (NLL) для победителей пар, что существенно для улучшения производительности. Итеративный процесс повторяется путем генерации новых пар и повторного обучения модели из предыдущей итерации, тем самым поэтапно улучшая производительность модели.
Значение:
Данный подход позволяет значительно улучшить способности к рассуждению с помощью последовательных итераций, превосходя производительность других моделей на основе Llama-2, не использующих дополнительные наборы данных.
Подробнее ознакомиться с исследованием.
Все права на это исследование принадлежат его исследователям. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему Reddit с более чем 40 тысячами подписчиков.
Применение ИИ в вашем бизнесе:
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Iterative Preference Optimization for Improving Reasoning Tasks in Language Models. Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ. Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию. Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
AI Sales Bot и другие решения:
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`





















