
«`html
Введение в Mixture-of-Experts (MoE) архитектуры
MoE архитектуры используют разреженную активацию для масштабирования размеров моделей, сохраняя при этом высокую эффективность обучения и вывода. Однако обучение сети маршрутизаторов создает вызов оптимизации недифференцируемой, дискретной цели, несмотря на эффективное масштабирование моделей MoE. Недавно была представлена архитектура MoE под названием SMEAR, которая является полностью недифференцируемой и плавно объединяет экспертов в пространстве параметров. SMEAR очень эффективен, но его эффективность ограничена масштабированием моделей на небольших экспериментах по тонкой настройке на классификационных задачах.
Применение разреженных MoE моделей
Разреженные MoE модели стали полезным методом для эффективного масштабирования размеров моделей. Архитектура разреженной MoE адаптирована для моделей трансформера для достижения лучшей производительности в машинном переводе. Традиционные MoE модели обучаются направлять входные данные в экспертные модули, что приводит к недифференцируемой, дискретной проблеме обучения принятия решений. Кроме того, для обучения существующих моделей используются стратегии маршрутизации top-1 или top-2 на основе разработанной цели балансировки нагрузки. Обучение MoE моделей усложняется проблемой нестабильности обучения, недостаточной специализации экспертов и неэффективного обучения.
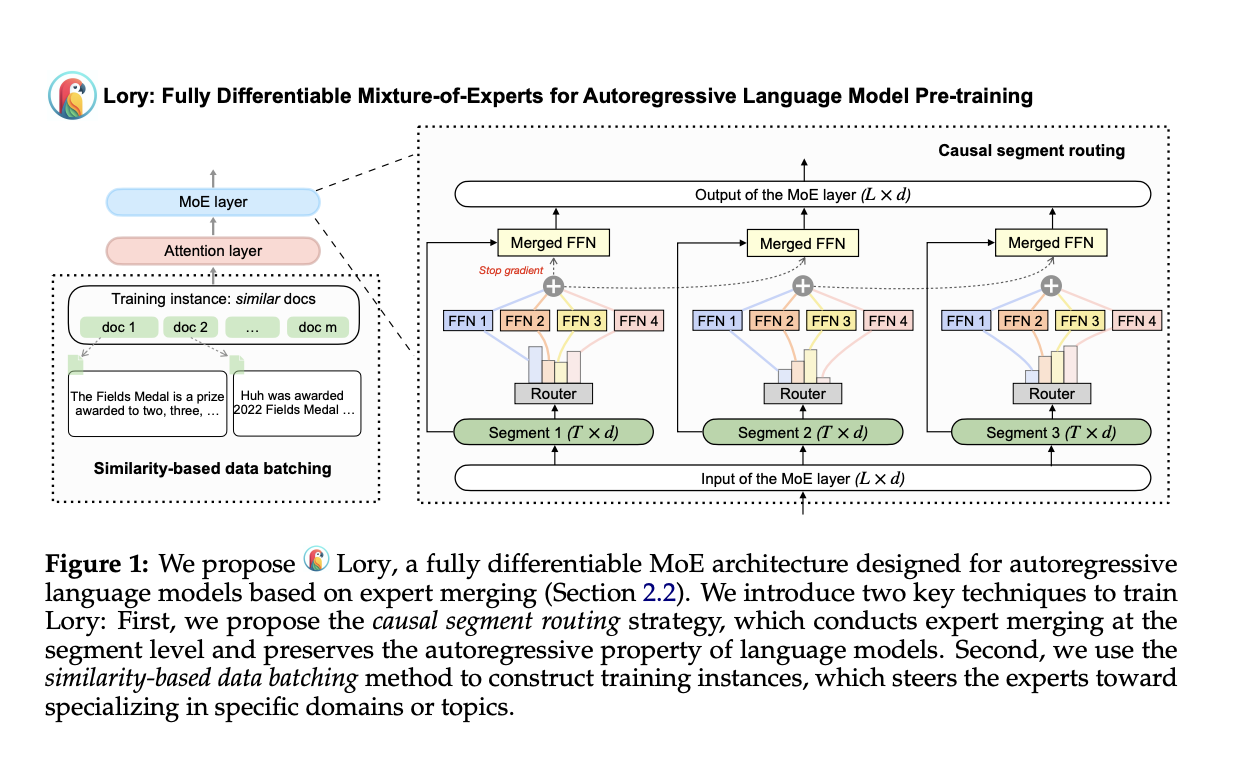
Метод Lory для масштабирования MoE архитектур
Исследователи из Принстонского университета и Meta AI представили метод Lory для масштабирования MoE архитектур для предварительного обучения авторегрессивных языковых моделей. Lory состоит из двух основных техник: (a) стратегия маршрутизации случайного сегмента, эффективная в операциях объединения экспертов, сохраняя авторегрессивную природу языковых моделей, и (b) метод пакетной обработки данных на основе сходства, поддерживающий специализацию экспертов путем создания групп для похожих документов во время обучения. Кроме того, модели Lory превосходят современные MoE модели благодаря маршрутизации на уровне токенов вместо маршрутизации на уровне сегментов.
Результаты и преимущества метода Lory
Метод Lory показывает выдающиеся результаты по различным факторам:
- Эффективность обучения и сходимость: Lory достигает эквивалентного уровня потерь с менее чем половиной обучающих токенов для моделей 0.3B и 1.5B, что указывает на лучшую производительность при том же вычислительном обучении.
- Языковое моделирование: Предложенные MoE модели превосходят плотную базовую модель во всех областях, что приводит к уменьшению перплексии. Например, по сравнению с плотной моделью 0.3B, модели 0.3B/32E достигают относительного улучшения на 13.9% в категории Books.
- Подзадачи: Модель 0.3B/32E достигает среднего увеличения производительности на +3.7% в рассуждениях о здравом смысле, +3.3% в понимании чтения, +1.5% в понимании чтения и +11.1% в классификации текста.
Выводы и рекомендации
Исследователи из Принстонского университета и Meta AI предложили метод Lory, полностью дифференцируемую MoE модель, разработанную для предварительного обучения авторегрессивных языковых моделей. Метод Lory состоит из двух основных техник: стратегии маршрутизации случайного сегмента и метода пакетной обработки данных на основе сходства. Предложенный метод превосходит свою плотную аналогию в языковом моделировании и подзадачах, а обученные эксперты высоко специализированы и способны улавливать информацию на уровне домена. Дальнейшая работа включает масштабирование Lory и интеграцию маршрутизации на уровне токенов и сегментов путем разработки эффективных методов декодирования для Lory.
Подробнее ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
«`




















