
«`html
Применение квантования больших языковых моделей (LLM) для повышения доступности мощных технологий искусственного интеллекта (ИИ)
Квантование LLM привлекло внимание благодаря своему потенциалу сделать мощные технологии ИИ более доступными, особенно в условиях ограниченных вычислительных ресурсов. Путем снижения вычислительной нагрузки, необходимой для запуска этих моделей, квантование обеспечивает возможность использования передового ИИ в более широком спектре практических сценариев без ущерба для производительности.
Оценка эффективности квантования
Традиционные большие модели требуют значительных ресурсов, что мешает их развертыванию в менее оборудованных средах. Поэтому разработка и совершенствование техник квантования, методов сжатия моделей для уменьшения вычислительных ресурсов без значительной потери точности, является критической.
Для оценки эффективности различных стратегий квантования LLM используются различные инструменты и бенчмарки. Эти бенчмарки охватывают широкий спектр, включая задачи общего знания и рассуждения в различных областях. Они оценивают модели как в нулевых, так и в малых сценариях, изучая, насколько хорошо эти квантованные модели выполняют различные типы когнитивных и аналитических задач без обширной донастройки или с минимальным обучением на примерах, соответственно.
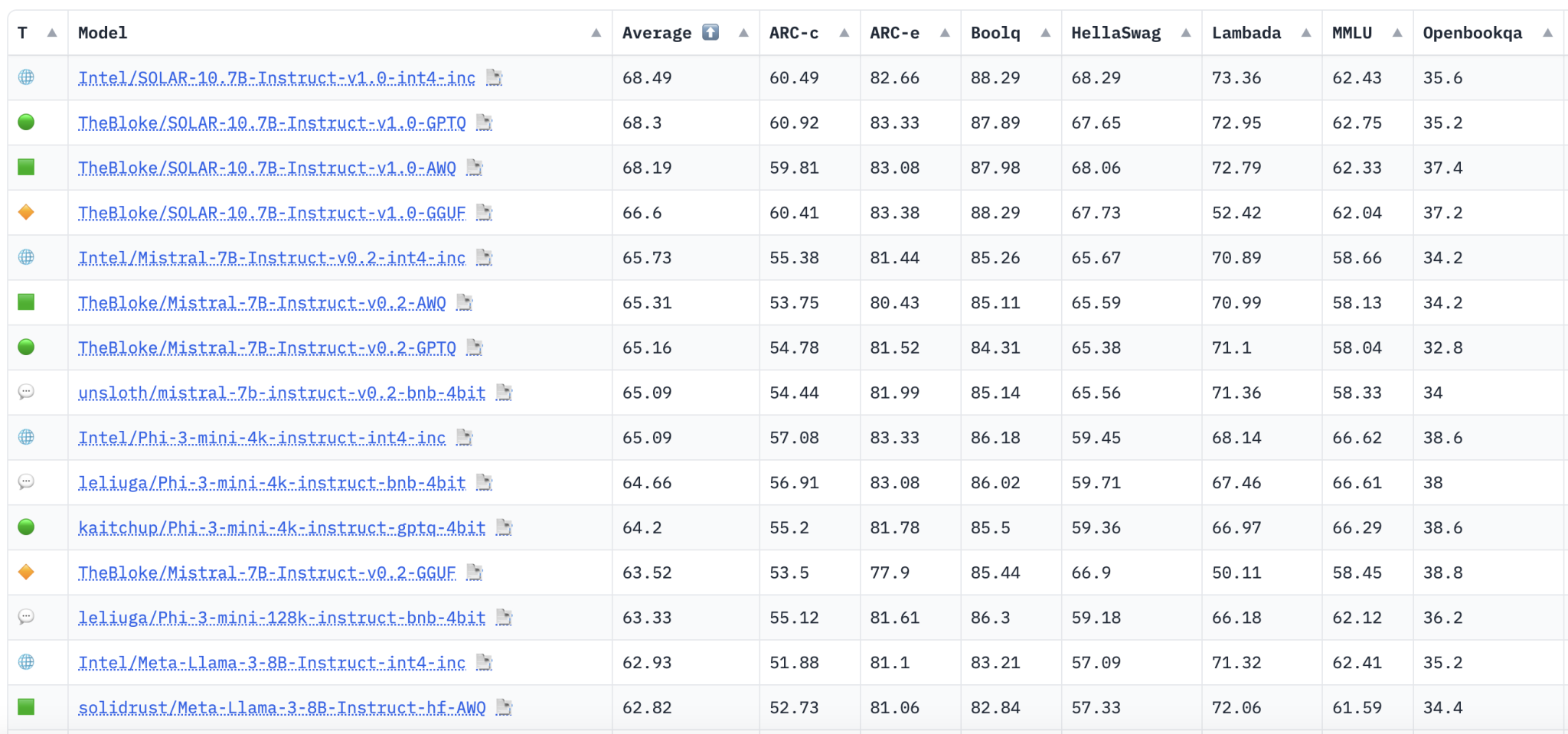
Low-bit Quantized Open LLM Leaderboard
Исследователи из Intel представили Low-bit Quantized Open LLM Leaderboard на платформе Hugging Face. Этот рейтинг предоставляет возможность сравнения производительности различных квантованных моделей с использованием последовательной и строгой системы оценки. Это позволяет исследователям и разработчикам более эффективно измерять прогресс в этой области и определять, какие методы квантования обеспечивают лучший баланс между эффективностью и эффективностью.
Электр AI-Language Model Evaluation Harness
Методика включает в себя строгие испытания через Eleuther AI-Language Model Evaluation Harness, который запускает модели через ряд задач, разработанных для тестирования различных аспектов производительности модели. Задачи включают в себя понимание и генерацию ответов, похожих на человеческие, на основе заданных подсказок, решение проблем в академических предметах, таких как математика и наука, и выявление истин в сложных сценариях вопросов. Модели оцениваются на основе точности и достоверности их выводов по сравнению с ожидаемыми человеческими ответами.
Десять ключевых бенчмарков для оценки моделей на Eleuther AI-Language Model Evaluation Harness:
- AI2 Reasoning Challenge (0-shot)
- AI2 Reasoning Easy (0-shot)
- HellaSwag (0-shot)
- MMLU (0-shot)
- TruthfulQA (0-shot)
- Winogrande (0-shot)
- PIQA (0-shot)
- Lambada_Openai (0-shot)
- OpenBookQA (0-shot)
- BoolQ (0-shot)
Выводы
Эти бенчмарки коллективно тестируют широкий спектр навыков рассуждения и общих знаний в нулевых и малых сценариях. Результаты с рейтинга показывают разнообразие производительности различных моделей и задач. Модели, оптимизированные для определенных типов рассуждений или конкретных областей знаний, иногда испытывают трудности с другими когнитивными задачами, что подчеркивает компромиссы, присущие текущим техникам квантования. Например, хотя некоторые модели могут преуспевать в понимании повествования, они могут плохо справляться с областями, требующими больших объемов данных, такими как статистика или логическое рассуждение. Эти расхождения критически важны для направления будущего проектирования моделей и улучшения подходов к обучению.
Источники:
Источник: MarkTechPost