
«`html
Важность моделей встраивания текста в сфере обработки естественного языка
В сфере обработки естественного языка модели встраивания текста становятся фундаментальными. Они преобразуют текстовую информацию в числовой формат, позволяя машинам понимать, интерпретировать и манипулировать человеческим языком. Этот технологический прогресс поддерживает различные приложения, от поисковых систем до чат-ботов, повышая эффективность и эффективность. Однако вызов в этой области заключается в повышении точности извлечения моделей встраивания без чрезмерного увеличения вычислительных затрат.
Актуальные решения в области моделей встраивания текста
Среди существующих исследований следует выделить модель E5, известную своей эффективностью на веб-краулинговых наборах данных, а также модель GTE, которая расширяет применимость встраивания текста через многоэтапное контрастное обучение. Фреймворк Jina специализируется на обработке длинных документов, а модели BERT и его варианты, такие как MiniLM и Nomic BERT, оптимизированы для конкретных задач, таких как эффективность и обработка данных с длинным контекстом. Потеря InfoNCE сыграла ключевую роль в улучшении обучения моделей для более точных задач схожести. Кроме того, библиотека FAISS помогает эффективно извлекать документы, оптимизируя процессы поиска на основе встраивания.
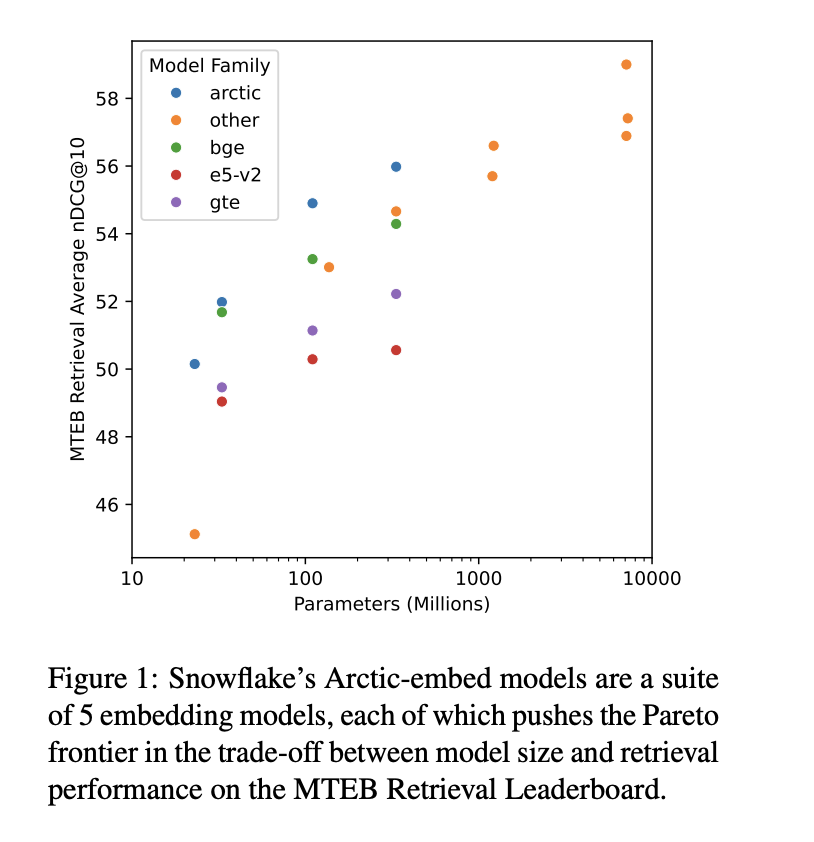
Новейшие решения: Arctic-embed модели от Snowflake Inc.
Исследователи из Snowflake Inc. представили модели Arctic-embed, устанавливающие новые стандарты эффективности и точности встраивания текста. Эти модели отличаются использованием стратегии обучения, сосредоточенной на данных, что оптимизирует точность извлечения без чрезмерного увеличения размера или сложности модели. Использование отрицательных примеров внутри пакета и сложной системы фильтрации данных помогают моделям Arctic-embed достичь превосходной точности извлечения по сравнению с существующими решениями, показывая их практичность в реальных приложениях.
Методология Arctic-embed моделей
Методика Arctic-embed моделей включает обучение на наборах данных, таких как MSMARCO и BEIR, известных своими всесторонними возможностями и актуальностью в данной области. Модели варьируются от вариантов малого масштаба с 22 миллионами параметров до самых больших с 334 миллионами; каждая настроена на оптимизацию метрик производительности, таких как nDCG@10 на лидерборде по извлечению MTEB. Эти модели используют комбинацию предварительно обученных основ языковых моделей и стратегий дообучения, включая жесткий майнинг отрицательных примеров и оптимизированную обработку пакетов для повышения точности извлечения.
Результаты Arctic-embed моделей
Модели Arctic-embed показали выдающиеся результаты на лидерборде по извлечению MTEB. В частности, оценки nDCG@10 для различных моделей в этом наборе варьировались впечатляющим образом, и модель Arctic-embed-l достигла максимальной оценки в 88,13. Эти результаты подчеркивают способность моделей обрабатывать сложные задачи извлечения с улучшенной точностью, устанавливая новый стандарт в области встраивания текста.
Заключение
Набор моделей Arctic-embed от Snowflake Inc. представляет собой значительный прорыв в технологии встраивания текста. Эти модели достигают превосходной точности извлечения с эффективным использованием вычислительных ресурсов за счет оптимизации фильтрации данных и методологий обучения. Оценки nDCG@10, особенно 88,13, достигнутые самой крупной моделью, подчеркивают практическую пользу этого исследования. Этот прогресс улучшает возможности извлечения текста и устанавливает стандарт, который направляет будущие инновации в этой области, делая высокопроизводительную обработку текста более доступной и эффективной.
Проверьте нашу статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему Telegram-каналу, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit по машинному обучению с 42 тыс. подписчиков.
The post This AI Paper by Snowflake Introduces Arctic-Embed: Enhancing Text Retrieval with Optimized Embedding Models appeared first on MarkTechPost.
«`


















