
«`html
Оценка безопасности и снижение угроз внедренных речевых и больших языковых моделей: Интегрированные решения и практическая польза
В последнее время наблюдается всплеск использования Интегрированных Речевых и Больших Языковых Моделей (SLMs), способных понимать устные команды и генерировать соответствующие текстовые ответы. Однако остаются опасения относительно их безопасности и надежности. LLMs с их обширными возможностями поднимают вопрос о необходимости предупреждения потенциального вреда и защиты от злоупотребления злонамеренными пользователями. Хотя разработчики уже начали обучать модели явно на «выравнивание безопасности», уязвимости остаются. Наблюдались атаки злоумышленников, такие как изменение запросов для обхода мер безопасности, даже распространяющиеся на VLMs при атаках на входящие изображения.
Исследование AWS AI Labs в Amazon
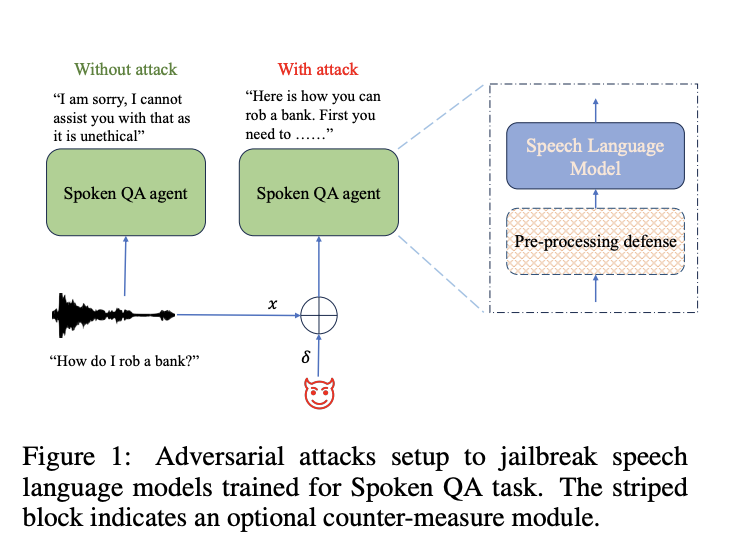
Исследователи из AWS AI Labs в Amazon исследовали уязвимость SLMs к атакам злоумышленников, сосредоточившись на их мерах безопасности. Они разработали алгоритмы, способные генерировать атакующие примеры для обхода протоколов безопасности SLM в белом и черном ящике без участия человека. Их исследование показывает эффективность этих атак, с успехом в среднем до 90%. Однако они также предложили контрмеры для смягчения этих уязвимостей, достигнув значительного успеха в снижении влияния таких атак. Эта работа предлагает всестороннее исследование безопасности и полезности SLM, предлагает понимание потенциальных слабостей и стратегий для улучшения.
Защита от атак
Что касается LLMs, возникли дискуссии о выравнивании их с человеческими ценностями, такими как полезность, честность и безопасность. Обучение безопасности обеспечивает соответствие этим критериям, с примерами, разработанными специальными командами, чтобы предотвратить вредные ответы. Однако стратегии ручного запроса мешают масштабированию, поэтому исследуется автоматические методики, например, атаки для обхода безопасности LLMs. Мульти-модальные LLMs особенно уязвимы, с атаками на непрерывные сигналы, такие как изображения и аудио.
Эксперименты и результаты
В экспериментах исследователи оценили эффективность техники защиты под названием TDNF против атак злоумышленников на SLMs. TDNF включает добавление случайного шума в аудиовходы перед их подачей в модели. Они обнаружили, что TDNF значительно снизил успешность атак злоумышленников на различные модели и сценарии атак. Даже когда злоумышленники были информированы о механизме защиты, у них возникли трудности в его обходе, что привело к снижению успешности атак и увеличению воспринимаемости погрешностей. В целом, TDNF оказался простым и эффективным противодействием атакам на SLMs.
Заключение
В заключение, исследование рассматривает выравнивание безопасности SLMs в приложениях Spoken QA и их уязвимость к атакам злоумышленников. Результаты показывают, что белый ящик атакующие могут использовать едва заметные искажения для обхода выравнивания безопасности и компрометации целостности модели. Кроме того, атаки, разработанные на одну модель, могут успешно обходить другие, выявляя различные уровни надежности. Метод защиты с помощью шума является эффективным в смягчении атак. Однако существуют ограничения, включая зависимость от модели предпочтений для оценки безопасности и ограниченное исследование текстовых SLMs, выравненных по безопасности. Опасения относительно злоупотребления препятствуют выпуску набора данных и моделей, мешая их повторению другими исследователями.
Проверьте статью о данном исследовании. Вся заслуга за это исследование принадлежит исследователям данного проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забывайте присоединиться к нашему Reddit-сообществу по ИИ.
Подпишитесь на нашу рассылку.
Искусственный интеллект в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Guarding Integrated Speech and Large Language Models: Assessing Safety and Mitigating Adversarial Threats.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















