«`html
Раскрытие потенциала больших языковых моделей: улучшение генерации обратной связи в образовании в области вычислительной техники
Обратная связь играет ключевую роль в успехе студентов, особенно в условиях растущего спроса на курсы по вычислительной технике. Автоматизированные инструменты, использующие методы анализа и тестирования, становятся все более популярными, но часто нуждаются в более полезных рекомендациях. Недавние достижения в области больших языковых моделей (LLM) показывают потенциал в предоставлении быстрой обратной связи, близкой к человеческой. Однако сохраняются опасения относительно точности, надежности и этических последствий использования собственных LLM, что требует изучения альтернатив с открытым исходным кодом в образовании в области вычислительной техники.
Практические решения и ценность
Автоматизированная генерация обратной связи в образовании в области вычислительной техники долгое время представляла собой настоящее испытание, сосредоточенное в основном на выявлении ошибок, а не на предложении конструктивных рекомендаций. LLM представляют собой многообещающее решение этой проблемы. Недавние исследования исследовали использование LLM для автоматизированной генерации обратной связи, но выявили ограничения в их производительности. Хотя некоторые исследования показывают, что LLM, такие как GPT-3 и GPT-3.5, могут выявлять проблемы в коде студентов, они также проявляют несогласованность и неточности в обратной связи. Кроме того, современные передовые модели испытывают затруднения в сопоставлении с человеческой производительностью при предоставлении обратной связи по упражнениям по программированию. Концепция использования LLM в качестве судей для оценки выводов других LLM, называемая LLM-как-судьи, набирает популярность. Этот подход показал многообещающие результаты, причем модели, такие как GPT-4, достигли высоких уровней согласия с человеческими суждениями.
Исследователи из Аалто университета, университета Ювяскюля и университета Окленда предоставляют тщательное исследование для оценки эффективности LLM в предоставлении обратной связи по программам, написанным студентами, и для изучения того, могут ли LLM с открытым исходным кодом соперничать с собственными в этом отношении. Основное внимание уделяется обратной связи, выявляющей ошибки в коде студентов, такие как ошибки компилятора или неудачные тесты. Вначале оценки сравнивают программную обратную связь от GPT-4 с экспертными оценками людей, устанавливая базовую линию для оценки качества обратной связи, сгенерированной LLM. В дальнейшем исследование оценивает качество обратной связи от различных LLM с открытым исходным кодом по сравнению с собственными моделями. Для решения этих исследовательских вопросов используются существующие наборы данных и новая обратная связь, сгенерированная моделями с открытым исходным кодом, оценивается с использованием GPT-4 в качестве судьи.
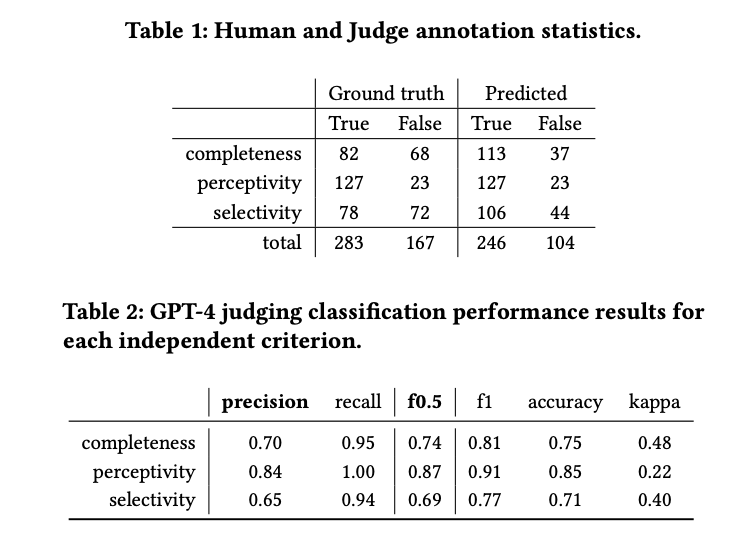
Были использованы данные из вводного курса по программированию Аалто университета, состоящие из запросов студентов на помощь и обратной связи, сгенерированной GPT-3.5. Критерии оценки сосредоточены на полноте, восприимчивости и селективности обратной связи. Обратная связь оценивалась как качественно, так и автоматически с использованием GPT-4. Модели с открытым исходным кодом оценивались наряду с собственными, используя систему оценки на основе рубрик. GPT-4 оценивал качество обратной связи, сгенерированной LLM, на основе аннотаций людей. Точность и F0.5-оценка были ключевыми метриками, используемыми для оценки производительности судьи.
Результаты показывают, что хотя большинство обратной связи воспринимается, лишь немногие полностью завершены, и многие содержат вводящий в заблуждение контент. GPT-4 склонен оценивать обратную связь более положительно по сравнению с человеческими аннотаторами, что указывает на некоторую положительную предвзятость. Результаты классификации производительности для GPT-4 показывают довольно хорошую производительность в классификации полноты и немного более низкую производительность в селективности. Оценка восприимчивости выше, частично из-за неравномерности данных. Коэффициент Каппа указывает на умеренное согласие, причем GPT-4 сохраняет высокий уровень полноты по всем критериям, сохраняя разумную точность и точность.
В заключение, в данном исследовании была изучена эффективность GPT-4 в оценке автоматически генерируемой программной обратной связи и оценена производительность различных больших языковых моделей, включая модели с открытым исходным кодом, в генерации обратной связи по коду студентов. Результаты указывают на то, что GPT-4 обещает надежно оценивать качество автоматически генерируемой обратной связи. Кроме того, модели языка с открытым исходным кодом демонстрируют потенциал в генерации программной обратной связи. Это говорит о том, что обратная связь, сгенерированная LLM, может служить экономически эффективным и доступным ресурсом в образовательной среде, позволяя преподавателям и помощникам преподавателей сосредотачиваться на более сложных случаях, в которых LLM в настоящее время могут не справляться с помощью студентов.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 42 тысячами подписчиков.
Статья опубликована на портале MarkTechPost.
«`



















