
Google Cloud AI Researchers представили LANISTR для решения проблем эффективной и эффективной обработки неструктурированных и структурированных данных в рамках.
В машинном обучении обработка мультимодальных данных, включающих язык, изображения и структурированные данные, становится все более важной. Одной из ключевых проблем является отсутствие модальностей в крупномасштабных, безметочных и структурированных данных, таких как таблицы и временные ряды. Традиционные методы часто сталкиваются с трудностями, когда один или несколько типов данных отсутствуют, что приводит к субоптимальной производительности модели.
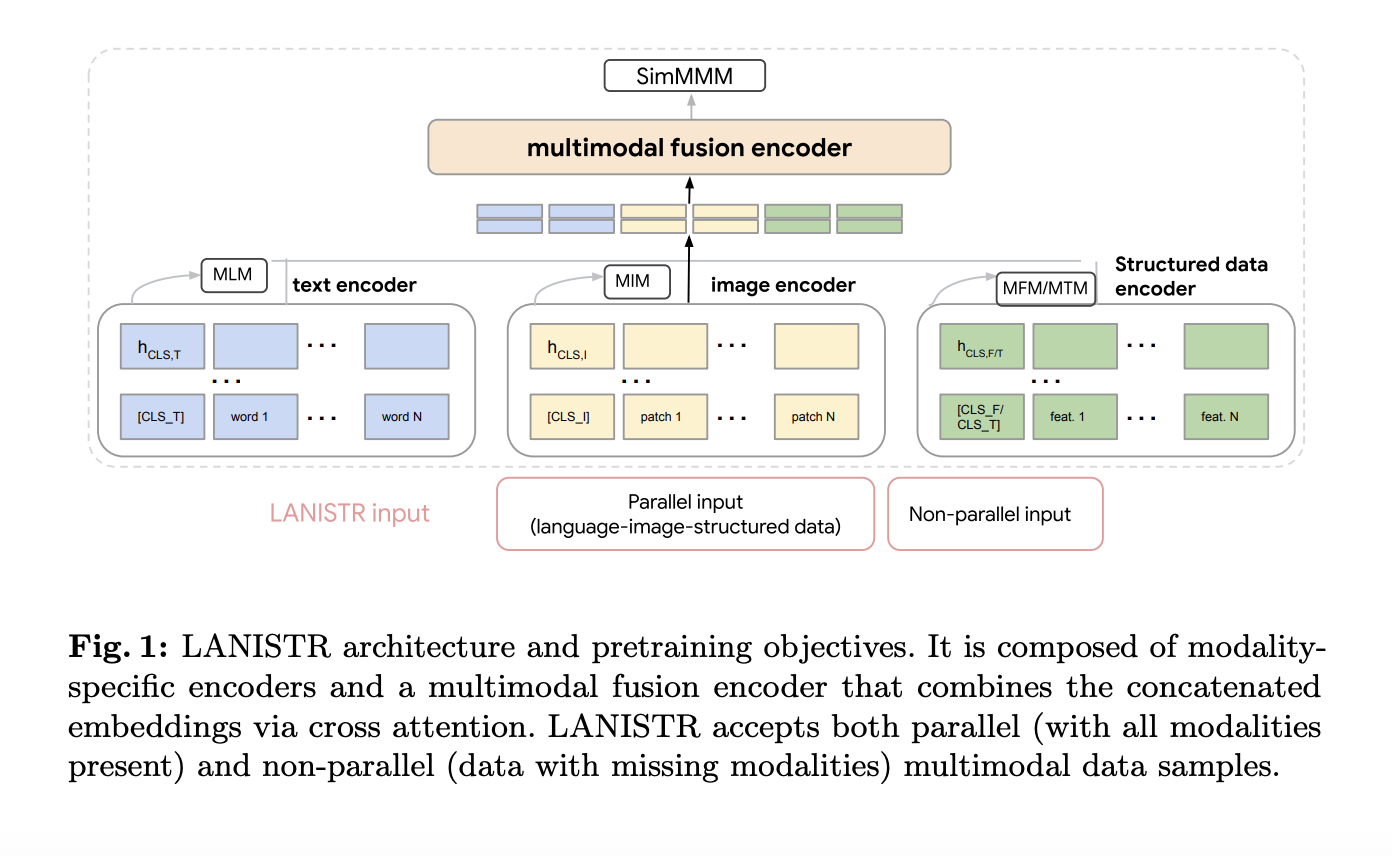
Методы предварительного обучения мультимодальных данных в настоящее время обычно полагаются на наличие всех модальностей во время обучения и вывода, что часто невозможно в реальных сценариях. Google’s LANISTR (Language, Image, and Structured Data Transformer), новая предварительная рамка, использует стратегии одномодальной и мультимодальной маскировки для создания устойчивой цели предварительного обучения, которая может эффективно обрабатывать отсутствующие модальности.
LANISTR также показал эффективность в сценариях с отсутствием распределения данных, не наблюдаемых во время обучения. Такая устойчивость к разнообразию данных критична в реальных приложениях, где изменчивость данных является общей проблемой.
LANISTR адресует критическую проблему в области мультимодального машинного обучения: проблему отсутствия модальностей в крупномасштабных неразмеченных наборах данных. Оценочный эксперимент демонстрирует, что LANISTR может эффективно учиться на неполных данных и хорошо обобщаться на новые, невидимые распределения данных, что делает его ценным инструментом для развития мультимодального обучения.
Подробнее ознакомьтесь с научной статьей и блогом.



















