
«`html
Машинный перевод (MT) в ИИ: Решения и Практическая Ценность
Машинный перевод (MT) – важная область в обработке естественного языка (NLP), которая фокусируется на автоматическом переводе текста с одного языка на другой. Эта технология использует большие языковые модели (LLM) для понимания и генерации человеческих языков, облегчая коммуникацию между языковыми барьерами. MT направлен на преодоление глобальных коммуникационных разрывов, непрерывно улучшая точность перевода, поддерживая многоязычный обмен информацией и доступность.
Основные вызовы машинного перевода
Основной вызов в машинном переводе заключается в выборе качественных и разнообразных обучающих данных для настройки модели. Качество и разнообразие в данных обеспечивают обобщение языковых моделей в различных контекстах и языках. Без этих элементов модели могут производить переводы, лишенные точности, или не улавливать тонкие значения, что ограничивает их эффективность в реальных приложениях.
Практические решения и ценность
Существующие исследования включают методы, такие как выбор образцов перевода в контексте, оптимизация запросов и стратегии декодирования для улучшения производительности машинного перевода. Заметные модели и фреймворки, такие как GPT-4, Bayling-13B, BigTranslate-13B, TIM и NLLB-54B, сосредотачиваются на настройке обучения и производительности перевода. Эти подходы используют техники для оптимизации точности перевода и обобщения, часто полагаясь на обширные наборы данных и сложные метрики оценки, такие как BLEU, BLEURT и COMET, для измерения эффективности и улучшений в переводах языковых моделей.
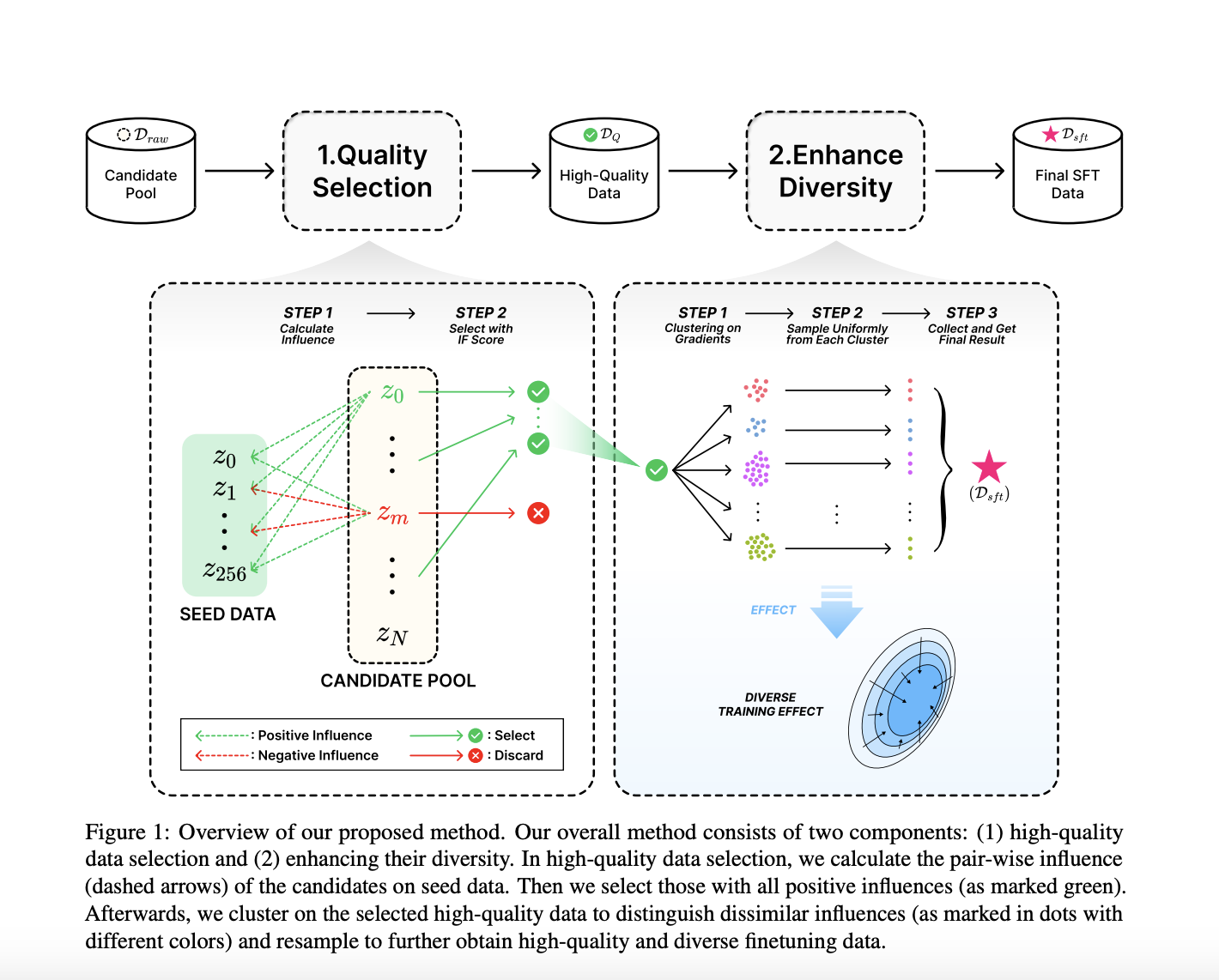
Исследователи из ByteDance Research представили новый метод под названием G-DIG, который использует градиентные техники для выбора качественных и разнообразных обучающих данных для машинного перевода. Инновация использует функции влияния для анализа того, как отдельные обучающие примеры влияют на производительность модели. Этот метод направлен на улучшение выбора данных без использования внешних моделей, тем самым улучшая качество и разнообразие обучающих наборов данных.
Метод G-DIG включает две основные компоненты: выбор высококачественных данных и улучшение разнообразия. Исследователи вручную создают небольшой набор исходных данных для высококачественных данных и используют функции влияния для идентификации обучающих примеров, которые положительно влияют на производительность модели. Для улучшения разнообразия они применяют алгоритмы кластеризации к градиентам обучающих примеров, обеспечивая разнообразное влияние на модель. Подобие градиента оценивается с использованием меры евклидового расстояния, и для группировки обучающих данных в разнообразные шаблоны используется алгоритм кластеризации K-средних. Этот двухэтапный процесс обеспечивает выбор высококачественных и разнообразных данных, улучшая общие возможности модели для перевода.
Обширные эксперименты на различных задачах перевода, включая WMT22 и FLORES, показали, что G-DIG значительно превосходит существующие методы выбора данных и достигает конкурентоспособных результатов по сравнению с передовыми моделями. G-DIG показал лучшие результаты как в задачах перевода с китайского на английский, так и с немецкого на английский. Например, в задаче перевода с китайского на английский модель G-DIG последовательно превосходила случайную модель по всем метрикам и размерам набора данных. Оценка COMET для перевода с китайского на английский улучшилась на 1,7 с 1000 обучающими примерами и на 2,11 в BLEU на наборе данных FLORES. В задаче перевода с немецкого на английский G-DIG улучшил показатели BLEU на 2,11 и 1,24 на WMT и FLORES по сравнению с моделями, обученными с произвольно выбранными данными. Исследователи отметили, что модели, обученные с данными, выбранными с помощью G-DIG, проявляют лучшее качество перевода и соответствие ожиданиям людей.
Исследовательская группа успешно решила проблемы качества и разнообразия данных в машинном переводе, представив метод G-DIG. Этот подход использует выбор данных на основе градиентов, улучшая производительность модели без необходимости использования внешних моделей оценки качества. Исследование демонстрирует потенциал G-DIG для улучшения точности и эффективности перевода, открывая путь для более продвинутых и надежных систем машинного перевода. Кроме того, способность G-DIG выбирать обучающие данные, непосредственно влияющие на производительность модели, гарантирует, что LLM лучше соответствуют человеческим инструкциям, делая их более эффективными в реальных приложениях.
Заключение
ByteDance Research представил прорывный метод, который решает критические проблемы в машинном переводе, демонстрируя значительные улучшения качества перевода с помощью инновационных техник выбора данных. Метод G-DIG представляет собой существенное развитие в этой области, предлагая новый путь для улучшения возможностей LLM в различных задачах перевода. Успех этого метода подчеркивает важность качественных и разнообразных данных при обучении надежных и точных языковых моделей, обеспечивая их соответствие глобальным требованиям в области коммуникации и обмена информацией.
Подробнее ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям данного проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 42 тысячами подписчиков.
Этот AI Paper by ByteDance Research Introduces G-DIG: A Gradient-Based Leap Forward in Machine Translation Data Selection представляет собой значимый шаг вперед в области машинного перевода и открывает новые возможности для развития вашего бизнеса с применением ИИ.